

 IDG
IDG








Dell Latitude E6410 Notebook| Quantity Available: 40+
This post is intended for businesses and other organizations interested... Read more →
Posted by Richy George on 24 June, 2024
When I reviewed Amazon CodeWhisperer, Google Bard, and GitHub Copilot in June of 2023, CodeWhisperer could generate code in an IDE and did security reviews, but it lacked a chat window and code explanations. The current version of CodeWhisperer is now called Amazon Q Developer, and it does have a chat window that can explain code, and several other features that may be relevant to you, especially if you do a lot of development using AWS.
Amazon Q Developer currently runs in Visual Studio Code, Visual Studio, JetBrains IDEs, the Amazon Console, and the macOS command line. Q Developer also offers asynchronous agents, programming language translations, and Java code transformations/upgrades. In addition to generating, completing, and discussing code, Q Developer can write unit tests, optimize code, scan for vulnerabilities, and suggest remediations. It supports conversations in English, and code in the Python, Java, JavaScript, TypeScript, C#, Go, Rust, PHP, Ruby, Kotlin, C, C++, shell scripting, SQL, and Scala programming languages.
You can chat with Amazon Q Developer about AWS capabilities, and ask it to review your resources, analyze your bill, or architect solutions. It knows about AWS well-architected patterns, documentation, and solution implementation.
According to Amazon, Amazon Q Developer is “powered by Amazon Bedrock” and trained on “high-quality AWS content.” Since Bedrock supports many foundation models, it’s not clear from the web statement which one was used for Amazon Q Developer. I asked, and got this answer from an AWS spokesperson: “Amazon Q uses multiple models to execute its tasks and uses logic to route tasks to the model that is the best fit for the job.”
Amazon Q Developer has a reference tracker that detects whether a code suggestion might be similar to publicly available code. The reference tracker can label these with a repository URL and project license information, or optionally filter them out.
Amazon Q Developer directly competes with GitHub Copilot, JetBrains AI, and Tabnine, and indirectly competes with a number of large language models (LLMs) and small language models (SLMs) that know about code, such as Code Llama, StarCoder, Bard, OpenAI Codex, and Mistral Codestral. GitHub Copilot can converse in dozens of natural languages, as opposed to Amazon Q Developer’s one, and supports a number of extensions from programming, cloud, and database vendors, as opposed to Amazon Q Developer’s AWS-only ties.
Given the multiple environments in which Amazon Q Developer can run, it’s not a surprise that there are multiple installers. The only tricky bit is signing and authentication.
You can install Amazon Q Developer from the Visual Studio Code Marketplace, or from the Extensions sidebar in Visual Studio Code. You can get to that sidebar from the Extensions icon at the far left, by pressing Shift-Command-X, or by choosing Extensions: Install Extensions from the command palette. Type “Amazon Q” to find it. Once you’ve installed the extension, you’ll need to authenticate to AWS as discussed below.
Amazon Q Developer in Visual Studio Code includes a chat window (at the left) as well as code generation. The chat window is showing Amazon Q Developer’s capabilities.
Like Visual Studio Code, JetBrains has a marketplace for IDE plugins, where Amazon Q Developer is available. You’ll need to reboot the IDE after downloading and installing the plugin. Then you’ll need to authenticate to AWS as discussed below. Note that the Amazon Q Developer plugin disables local inline JetBrains full-line code completion.
Amazon Q Developer in IntelliJ IDEA, and other JetBrains IDEs, has a chat window on the right as well as code completion. The chat window is showing Amazon Q Developer’s capabilities.
For Visual Studio, Amazon Q Developer is part of the AWS Toolkit, which you can find it in the Visual Studio Marketplace. Again, once you’ve installed the toolkit you’ll need to authenticate to AWS as discussed below.
The authentication process is confusing because there are several options and several steps that bounce between your IDE and web browser. You used to have to repeat this process frequently, but the product manager assures me that re-authentication should now only be necessary every three months.
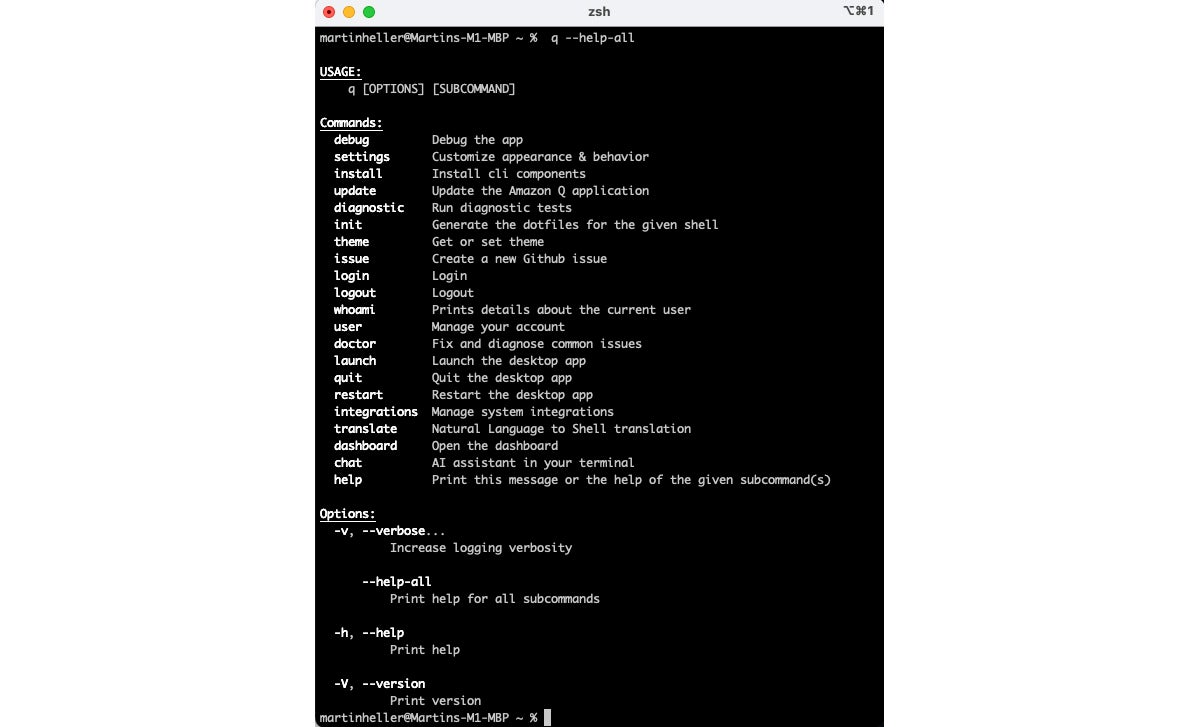
Amazon Q Developer for the command line is currently for macOS only, although a Linux version is on the roadmap and documented as a remote target. The macOS installation is basically a download of a DMG file, followed by running the disk image, dragging the Q file to the applications directory, and running that Q app to install the CLI q program and a menu bar icon that can bring up settings and the web user guide. You’ll also need to authenticate to AWS, which will log you in.
On macOS, the command-line program q supports multiple shell programs and multiple terminal programs. Here I’m using iTerm2 and the z shell. The q translate command constructs shell commands for you, and the q chat command opens an AI assistant.
If you are running as an IAM user rather than a root user, you’ll have to add IAM permissions to use Amazon Q Developer. Once you have permission, AWS should display an icon at the right of the screen that brings up the Amazon Q Developer interface.
The Amazon Q Developer window at the right, running in the AWS Console, can chat with you about using AWS and can generate architectures and code for AWS applications.
According to AWS, “Amazon Q Developer Agent achieved the highest scores of 13.4% on the SWE-Bench Leaderboard and 20.5% on the SWE-Bench Leaderboard (Lite), a data set that benchmarks coding capabilities. Amazon Q security scanning capabilities outperform all publicly benchmarkable tools on detection across the most popular programming languages.”
Both of the quoted numbers are reflected on the SWE-Bench site, but there are two issues. Neither number has as yet been verified by SWE-Bench, and the Amazon Q Developer ranking on the Lite Leaderboard has dropped to #3. In addition, if there’s a supporting document on the web for Amazon’s security scanning claim, it has evaded my searches.
SWE-Bench, from Cornell, is “an evaluation framework consisting of 2,294 software engineering problems drawn from real GitHub issues and corresponding pull requests across 12 popular Python repositories.” The scores reflect the solution rates. The Lite data set is a subset of 300 GitHub issues.
Let’s explore how Amazon Q Developer behaves on the various tasks it supports in some of the 15 programming languages it supports. This is not a formal benchmark, but rather an attempt to get a feel for how well it works. Bear in mind that Amazon Q Developer is context sensitive and tries to use the persona that it thinks best fits the environment where you ask it for help.
I tried a softball question for predictive code generation and used one of Amazon’s inline suggestion examples. The Python prompt supplied was # Function to upload a file to an S3 bucket. Pressing Option-C as instructed got me the code below the prompt in the screenshot below, after an illegal character that I had to delete. I had to type import at the top to prompt Amazon Q to generate the imports for logging, boto3, and ClientError.
I also used Q Chat to tell me how to resolve the imports; it suggested a pip command, but on my system that fixed the wrong Python environment (v 3.11). I had to do a little sleuthing in the Frameworks directory tree to remind myself to use pip3 to target my current Python v 3.12 environment. I felt like singing “Daisy, Daisy” to Dave and complaining that my mind was going.
Inline code generation and chat with Amazon Q Developer. All the code below the # TODO comment was generated by Amazon Q Developer, although it took multiple steps.
I also tried Amazon’s two other built-in inline suggestion examples. The example to complete an array of fake users in Python mostly worked; I had to add the closing ] myself. The example to generate unit tests failed when I pressed Option-C: It generated illegal characters instead of function calls. (I’m starting to suspect an issue with Option-C in VS Code on macOS. It may or may not have anything to do with Amazon Q Developer.)
When I restarted VS Code, tried again, and this time pressed Return on the line below the comment, it worked fine, generating the test_sum function below.
# Write a test case for the above function. def test_sum(): """ Unit test for the sum function. """ assert sum(1, 2) == 3 assert sum(-1, 2) == 1 assert sum(0, 0) == 0
AWS shows examples of completion with Amazon Q Developer in up to half a dozen programming languages in its documentation. The examples, like the Python ones we’ve discussed, are either very simple, e.g. add two numbers, or relate to common AWS operations supported by APIs, such as uploading files to an S3 bucket.
Since I now believed that Amazon Q Developer can generate Python, especially for its own test examples, I tried something a little different. As shown in the screenshot below, I created a file called quicksort.cpp, then typed an initial comment:
//function to sort a vector of generics in memory using the quicksort algorithm
Amazon Q Developer kept trying to autocomplete this comment, and in some cases the implementation as well, for different problems. Nevertheless it was easy to keep typing my specification while Amazon Q Developer erased what it had generated, and Amazon Q Developer eventually generated a nearly correct implementation.
Quicksort is a well-known algorithm. Both the C and C++ libraries have implementations of it, but they don’t use generics. Instead, you need to write type-specific comparison functions to pass to qsort. That’s historic, as the libraries were implemented before generics were added to the languages.
Page 2
I eventually got Amazon Q Developer to generate the main routine to test the implementation. It initially generated documentation for the function instead, but when I rejected that and tried again it generated the main function with a test case.
Unsurprisingly, the generated code didn’t even compile the first time. I saw that Amazon Q Developer had left out the required #include <iostream>, but I let VS Code correct that error without sending any code to Amazon Q Developer or entering the #include myself.
It still didn’t compile. The errors were in the recursive calls to sortVector(), which were written in a style that tried to be too clever. I highlighted and sent one of the error messages to Amazon Q Developer for a fix, and it solved a different problem. I tried again, giving Amazon Q Developer more context and asking for a fix; this time it recognized the actual problem and generated correct code.
This experience was a lot like pair programming with an intern or a junior developer who hadn’t learned much C++. An experienced C/C++ programmer might have asked to recast the problem to use the qsort library function, on grounds of using the language library. I would have justified my specification to use generics on stylistic grounds as well as possible runtime efficiency grounds.
Another consideration here is that there’s a well-known worst case for qsort, which takes a maximum time to run when the vector to be sorted is already in order. For this implementation, there’s a simple fix to be made by randomizing the partition point (see Knuth, The Art of Computer Programming: Sorting and Searching, Volume 3). If you use the library function you just have to live with the inefficiency.
Amazon Q Developer code generation from natural language to C++. I asked for a well-known sorting algorithm, quicksort, and complicated the problem slightly by specifying that the function operate on a vector of generics. It took several fixes, but got there eventually.
So far, none of my experiments with Amazon Q Developer have generated code references, which are associated with recommendations that are similar to training data. I do see a code reference log in Visual Studio Code, but it currently just says “Don’t want suggestions that include code with references? Uncheck this option in Amazon Q: Settings.”
By default, Q Developer scans your open code files for vulnerabilities in the background, and generates squiggly underlines when it finds them. From there you can bring up explanations of the vulns and often invoke automatic fixes for them. You can also ask Q to scan your whole project for vulnerabilities and generate a report. Scans look for security issues such as as resource leaks, SQL injection, and cross-site scripting; secrets such as hardcoded passwords, database connection strings, and usernames; misconfiguration, compliance, and security issues in infrastructure as code files; and deviations from quality and efficiency best practices.
You’ve already seen how you can use Q Chat in an IDE to explain and fix code. It can also optimize code and write unit tests. You can go back to the first screenshot in this review to see Q Chat’s summary of what it can and can’t do, or use the /help command yourself once you have Q Chat set up in your IDE. On the whole, having Q Chat in Amazon Q Developer improves the product considerably over last year’s CodeWhisperer.
If you set up Amazon Q Developer at the Pro level, you can customize its code generation of Python, Java, JavaScript, and TypeScript by giving it access to your code base. The code base can be in an S3 bucket or in a repository on GitHub, GitLab, or Bitbucket.
Running a customization generates a fine-tuned model that your users can choose to use for their code suggestions. They’ll still be able to use the default base model, but companies have reported that using customized code generation increases developer productivity even more than using the base model.
Developer agents are long-running Amazon Q Developer processes. The one agent I’ve seen so far is for code transformation, specifically transforming Java 8 or Java 11 Maven projects to Java 17. There are a bunch of specific requirements your Java project needs to meet for a successful transformation, but the transformation agent worked well in AWS’s internal tests. While I have seen it demonstrated, I haven’t run it myself.
Amazon Q Developer for the CLI currently (v 1.2.0) works in macOS; supports the bash, zsh, and fish shells; runs in the iTerm2, macOS Terminal, Hyper, Alacritty, Kitty, and wezTerm terminal emulators; runs in the VS Code terminal and JetBrains terminals (except Fleet); and supports some 500 of the most popular CLIs such as git, aws, docker, npm, and yarn. You can extend the CLI to remote macOS systems with q integrations install ssh. You can also extend it to 64-bit versions of recent distributions of Fedora, Ubuntu, and Amazon Linux 2023. (That one’s not simple, but it’s documented.)
Amazon Q Developer CLI performs three major services. It can autocomplete your commands as you type, it can translate natural language specifications to CLI commands (q translate), and it can chat with you about how to perform tasks from the command line (q chat).
For example, I often have trouble remembering all the steps it takes to rebase a Git repository, which is something you might want to do if you and a colleague are working on the same code (careful!) on different branches (whew!). I asked q chat, “How can I rebase a git repo?”
It gave me the response in the first screenshot below. To get brushed up on how the action works, I asked the follow-up question, “What does rebasing really mean?” It gave me the response in the second screenshot below. Finally, to clarify the reasons why I would rebase my feature branch versus merging it with an updated branch, I asked, “Why rebase a repo instead of merging branches?” It gave me the response in the third screenshot below.
The simple answer to the question I meant to ask is item 2, which talks about the common case where the main branch is changing while you work on a feature. The real, overarching answer is at the end: “The decision to rebase or merge often comes down to personal preference and the specific needs of your project and team. It’s a good idea to discuss your team’s Git workflow and agree on when to use each approach.”
In the first screenshot above, I asked q chat, “How can I rebase a git repo?” In the second screenshot, I asked “What does rebasing really mean?” In the third, I asked “Why rebase a repo instead of merging branches?”
As you saw earlier in this review, a small Q icon at the upper right of the AWS Management Console window brings up a right-hand column where Amazon Q Developer invites you to “Ask me anything about AWS.” Similarly a large Q icon at the bottom right of an AWS documentation page brings up that same AMAaA column as a modeless floating window.
Overall, I like Amazon Q Developer. It seems to be able to handle the use cases for which it was trained, and generate whole functions in common programming languages with only a few fixes. It can be useful for completing lines of code, doc strings, and if/for/while/try code blocks as you type. It’s also nice that it scans for vulnerabilities and can help you fix code problems.
On the other hand, Q Developer can’t generate full functions for some use cases; it then reverts to line-by-line suggestions. Also, there seems to be a bug associated with the use of Option-C to trigger code generation. I hope that will be fixed fairly soon, but the workaround is to press Return a lot.
According to Amazon, a 33% acceptance rate is par for the course for AI code generators. By acceptance rate, they mean the percentage of generated code that is used by the programmer. They claim a higher rate than that, even for their base model without customization. They also claim over 50% boosts in programmer productivity, although how they measure programmer productivity isn’t clear to me.
Their claim is that customizing the Amazon Q Developer model to “the way we do things here” from the company’s code base offers an additional boost in acceptance rate and programmer productivity. Note that code bases need to be cleaned up before using them for training. You don’t want the model learning bad, obsolete, or unsafe coding habits.
I can believe a hefty productivity boost for experienced developers from using Amazon Q Developer. However, I can’t in good conscience recommend that programming novices use any AI code generator until they have developed their own internal sense for how code should be written, validated, and tested. One of the ways that LLMs go off the rails is to start generating BS, also called hallucinating. If you can’t spot that, you shouldn’t rely on their output.
How does Amazon Q Developer compare to GitHub Copilot, JetBrains AI, and Tabnine? Stay tuned. I need to reexamine GitHub Copilot, which seems to get updates on a monthly basis, and take a good look at JetBrains AI and Tabnine before I can do that comparison properly. I’d bet good money, however, that they’ll all have changed in some significant way by the time I get through my full round of reviews.
—
Cost: Free with limited monthly access to advanced features; Pro tier $19/month.
Platform: Amazon Web Services. Supports Visual Studio Code, Visual Studio, JetBrains IDEs, the Amazon Console, and the macOS command line. Supports recent 64-bit Fedora, Ubuntu, and Amazon Linux 2023 as remote targets from macOS ssh.
Next read this:
Posted by Richy George on 17 June, 2024
“Turn your enterprise data into production-ready LLM applications,” blares the LlamaIndex home page in 60 point type. OK, then. The subhead for that is “LlamaIndex is the leading data framework for building LLM applications.” I’m not so sure that it’s the leading data framework, but I’d certainly agree that it’s a leading data framework for building with large language models, along with LangChain and Semantic Kernel, about which more later.
LlamaIndex currently offers two open source frameworks and a cloud. One framework is in Python; the other is in TypeScript. LlamaCloud (currently in private preview) offers storage, retrieval, links to data sources via LlamaHub, and a paid proprietary parsing service for complex documents, LlamaParse, which is also available as a stand-alone service.
LlamaIndex boasts strengths in loading data, storing and indexing your data, querying by orchestrating LLM workflows, and evaluating the performance of your LLM application. LlamaIndex integrates with over 40 vector stores, over 40 LLMs, and over 160 data sources. The LlamaIndex Python repository has over 30K stars.
Typical LlamaIndex applications perform Q&A, structured extraction, chat, or semantic search, and/or serve as agents. They may use retrieval-augmented generation (RAG) to ground LLMs with specific sources, often sources that weren’t included in the models’ original training.
LlamaIndex competes with LangChain, Semantic Kernel, and Haystack. Not all of these have exactly the same scope and capabilities, but as far as popularity goes, LangChain’s Python repository has over 80K stars, almost three times that of LlamaIndex (over 30K stars), while the much newer Semantic Kernel has over 18K stars, a little over half that of LlamaIndex, and Haystack’s repo has over 13K stars.
Repository age is relevant because stars accumulate over time; that’s also why I qualify the numbers with “over.” Stars on GitHub repos are loosely correlated with historical popularity.
LlamaIndex, LangChain, and Haystack all boast a number of major companies as users, some of whom use more than one of these frameworks. Semantic Kernel is from Microsoft, which doesn’t usually bother publicizing its users except for case studies.
The LlamaIndex framework helps you to connect data, embeddings, LLMs, vector databases, and evaluations into applications. These are used for Q&A, structured extraction, chat, semantic search, and agents.
At a high level, LlamaIndex is designed to help you build context-augmented LLM applications, which basically means that you combine your own data with a large language model. Examples of context-augmented LLM applications include question-answering chatbots, document understanding and extraction, and autonomous agents.
The tools that LlamaIndex provides perform data loading, data indexing and storage, querying your data with LLMs, and evaluating the performance of your LLM applications:
LLMs have been trained on large bodies of text, but not necessarily text about your domain. There are three major ways to perform context augmentation and add information about your domain, supplying documents, doing RAG, and fine-tuning the model.
The simplest context augmentation method is to supply documents to the model along with your query, and for that you might not need LlamaIndex. Supplying documents works fine unless the total size of the documents is larger than the context window of the model you’re using, which was a common issue until recently. Now there are LLMs with million-token context windows, which allow you to avoid going on to the next steps for many tasks. If you plan to perform many queries against a million-token corpus, you’ll want to cache the documents, but that’s a subject for another time.
Retrieval-augmented generation combines context with LLMs at inference time, typically with a vector database. RAG procedures often use embedding to limit the length and improve the relevance of the retrieved context, which both gets around context window limits and increases the probability that the model will see the information it needs to answer your question.
Essentially, an embedding function takes a word or phrase and maps it to a vector of floating point numbers; these are typically stored in a database that supports a vector search index. The retrieval step then uses a semantic similarity search, often using the cosine of the angle between the query’s embedding and the stored vectors, to find “nearby” information to use in the augmented prompt.
Fine-tuning LLMs is a supervised learning process that involves adjusting the model’s parameters to a specific task. It’s done by training the model on a smaller, task-specific or domain-specific data set that’s labeled with examples relevant to the target task. Fine-tuning often takes hours or days using many server-level GPUs and requires hundreds or thousands of tagged exemplars.
You can install the Python version of LlamaIndex three ways: from the source code in the GitHub repository, using the llama-index starter install, or using llama-index-core plus selected integrations. The starter installation would look like this:
pip install llama-index
This pulls in OpenAI LLMs and embeddings in addition to the LlamaIndex core. You’ll need to supply your OpenAI API key (see here) before you can run examples that use it. The LlamaIndex starter example is quite straightforward, essentially five lines of code after a couple of simple setup steps. There are many more examples in the repo, with documentation.
Doing the custom installation might look something like this:
pip install llama-index-core llama-index-readers-file llama-index-llms-ollama llama-index-embeddings-huggingface
That installs an interface to Ollama and Hugging Face embeddings. There’s a local starter example that goes with this installation. No matter which way you start, you can always add more interface modules with pip.
If you prefer to write your code in JavaScript or TypeScript, use LlamaIndex.TS (repo). One advantage of the TypeScript version is that you can run the examples online on StackBlitz without any local setup. You’ll still need to supply an OpenAI API key.
LlamaCloud is a cloud service that allows you to upload, parse, and index documents and search them using LlamaIndex. It’s in a private alpha stage, and I was unable to get access to it. LlamaParse is a component of LlamaCloud that allows you to parse PDFs into structured data. It’s available via a REST API, a Python package, and a web UI. It is currently in a public beta. You can sign up to use LlamaParse for a small usage-based fee after the first 7K pages a week. The example given comparing LlamaParse and PyPDF for the Apple 10K filing is impressive, but I didn’t test this myself.
LlamaHub gives you access to a large collection of integrations for LlamaIndex. These include agents, callbacks, data loaders, embeddings, and about 17 other categories. In general, the integrations are in the LlamaIndex repository, PyPI, and NPM, and can be loaded with pip install or npm install.
create-llama is a command-line tool that generates LlamaIndex applications. It’s a fast way to get started with LlamaIndex. The generated application has a Next.js powered front end and a choice of three back ends.
RAG CLI is a command-line tool for chatting with an LLM about files you have saved locally on your computer. This is only one of many use cases for LlamaIndex, but it’s quite common.
The LlamaIndex Component Guides give you specific help for the various parts of LlamaIndex. The first screenshot below shows the component guide menu. The second shows the component guide for prompts, scrolled to a section about customizing prompts.
The LlamaIndex component guides document the different pieces that make up the framework. There are quite a few components.
We’re looking at the usage patterns for prompts. This particular example shows how to customize a Q&A prompt to answer in the style of a Shakespeare play. This is a zero-shot prompt, since it doesn’t provide any exemplars.
Once you’ve read, understood, and run the starter example in your preferred programming language (Python or TypeScript, I suggest that you read, understand, and try as many of the other examples as look interesting. The screenshot below shows the result of generating a file called essay by running essay.ts and then asking questions about it using chatEngine.ts. This is an example of using RAG for Q&A.
The chatEngine.ts program uses the ContextChatEngine, Document, Settings, and VectorStoreIndex components of LlamaIndex. When I looked at the source code, I saw that it relied on the OpenAI gpt-3.5-turbo-16k model; that may change over time. The VectorStoreIndex module seemed to be using the open-source, Rust-based Qdrant vector database, if I was reading the documentation correctly.
After setting up the terminal environment with my OpenAI key, I ran essay.ts to generate an essay file and chatEngine.ts to field queries about the essay.
As you’ve seen, LlamaIndex is fairly easy to use to create LLM applications. I was able to test it against OpenAI LLMs and a file data source for a RAG Q&A application with no issues. As a reminder, LlamaIndex integrates with over 40 vector stores, over 40 LLMs, and over 160 data sources; it works for several use cases, including Q&A, structured extraction, chat, semantic search, and agents.
I’d suggest evaluating LlamaIndex along with LangChain, Semantic Kernel, and Haystack. It’s likely that one or more of them will meet your needs. I can’t recommend one over the others in a general way, as different applications have different requirements.
Open source: free. LlamaParse import service: 7K pages per week free, then $3 per 1000 pages.
Python and TypeScript, plus cloud SaaS (currently in private preview).
Next read this:





This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →
Copyright 2015 - InnovatePC - All Rights Reserved
Site Design By Digital web avenue