

Dell Latitude E6410 Notebook| Quantity Available: 40+
This post is intended for businesses and other organizations interested... Read more →
Posted by Richy George on 31 January, 2024

San Francisco-based Zilliz has released a new version of its database-as-a-service (DBaaS) offering, Zilliz Cloud. The company claims the new version offers better performance while reducing cost of ownership compared to its previous version.
Zilliz Cloud is built atop the open source Milvus vector database management system. Zilliz was founded by engineers who had helped develop the Milvus vector database.
The new version of Zilliz Cloud, according to the company, offers 10x better performance than the original Milvus vector database. This is achieved by using the Hierarchical Navigable Small World (HNSW) graph index in combination with an improved filtered search.
HNSW, however, is table stakes for most vector databases, including those of rivals Weaviate and Pinecone. It is one of the most popular graph indexes for building vector databases.
“HNSW is increasingly a must-have capability, so Zilliz would be at a disadvantage without it being supported by its DBMS,” said Doug Henschen, principal analyst at Constellation Research.
The reason behind the popularity of graph-based indexes can be attributed to their fundamental quality of being able to find the approximate nearest neighbors in high-dimensional data while being memory efficient. This quality results in an increase in performance and reduction in cost of ownership.
Another example of a graph-based index is Vamana. Other types of indexes used in vector databases include the Inverted File Index (IVF).
Additional features of the Zilliz Cloud update include the cosine similarity metric, range search, and upsert.
The cosine similarity metric is often used for text processing, where the direction of the embedding vectors is important but the distance between them is not.
A range search is used in a vector database to narrow search results based on the distance between a query vector and database vectors.
The upsert function, in a vector database, is used to either add a new vector to the index or update one if a vector with the same ID exists.
In addition to providing a unified Milvus Client that Zilliz claims will improve the developer experience, the new version of Zilliz Cloud can be integrated with data analytics, machine learning, and streaming platforms like Apache Spark, Apache Kafka, and Airbyte.
Despite the advantages of the new version, Constellation Research’s Henschen believes that many enterprises will turn to mainstream databases they already use for capabilities such as vector embeddings and vector search.
“The challenge for vendors like Zilliz is that they don’t have the transactional data of the enterprise with them typically,” said Holger Mueller, another principal analyst at Constellation Research.
“Either they have to provide the ease of use of getting transactional data in them or they need to have a solution that helps enterprises update vectors from their system of record. Failure to do so will force enterprises to look at their existing databases, such as the ones from Oracle, AWS, IBM, and Microsoft,” Mueller added.
The competition is even stiffer for Zilliz as rivals such as Pinecone also offer their products as cloud-based services, Henschen added.
However, the analyst said that dedicated AI teams and AI developers may find performance and cost advantages in using a dedicated vector database product or service, assuming it provides all of the features they need for supporting their use cases.
Next read this:
Posted by Richy George on 29 January, 2024
Generative AI has had an immediate and enormous impact on software development. Software developers have embraced generative AI tools that help with coding, and they are working feverishly to build generative AI applications themselves. Databases can help—especially fast, scalable, multi-model databases like SingleStore.
At the inaugural SingleStore Now conference, SingleStore announced several AI-focused innovations with developers in mind. These include SingleStore hybrid search, compute service, Notebooks, and the Elegance SDK. Given the impact that AI and LLMs are having on developers, it makes sense to dive into the ways that these innovations make developing AI applications easier.
If you’ve been working with AI or LLMs in any way, you know that vector databases have become much more popular because of their ability to help you search for the nearest n representations of the data you’re working with. You can then use those search results to provide additional context to your LLM to make the responses more accurate. SingleStoreDB has supported vector functions and vector search for a number of years now, but generative AI applications require you to search among millions or billions of vector embeddings in milliseconds—which gets difficult using k-Nearest Neighbor (kNN) across huge data sets.
Hybrid search adds Approximate Nearest Neighbor (ANN) search as an additional option to the already existing k-Nearest Neighbor (kNN) search. The primary difference between ANN and kNN is in the name: approximate vs. nearest. Initial testing shows ANN to be orders of magnitude faster for vector search, taking your AI use cases from fast to real time. Real-time vector search ensures that your applications respond instantly to queries, even when that data has just been written to the database.
Hybrid search uses a number of techniques to make your search functions more performant, namely inverted file (IVF) with product quantization (PQ). With IVF with PQ, you can lower the build times of your index while improving the compression ratios and memory footprint of your vector searches. Beyond IVF with PQ, hybrid search adds the hierarchical navigable small world (HNSW) approach to allow for high-performance vector index searches using high dimensionality.
With hybrid search, you can combine all of these new indexing approaches, along with full-text search, to combine hybrid semantic (vector similarity) and lexical/keyword search in one query.
Below you can see an example of using hybrid search. To view the code in its broader context, check out the full notebook on SingleStore Spaces.
hyb_query = 'Articles about Aussie captures'
hyb_embedding = model.encode(hyb_query)
# Create the SQL statement.
hyb_statement = sa.text('''
SELECT
title,
description,
genre,
DOT_PRODUCT(embedding, :embedding) AS semantic_score,
MATCH(title, description) AGAINST (:query) AS keyword_score,
(semantic_score + keyword_score) / 2 AS combined_score
FROM news.news_articles
ORDER BY combined_score DESC
LIMIT 10
''')
# Execute the SQL statement.
hyb_results = pd.DataFrame(conn.execute(hyb_statement, dict(embedding=hyb_embedding, query=hyb_query)))
hyb_results
The above query finds the average scores of semantic and keyword searches, combines them, and sorts the news articles by this calculated score. By removing the extra complexity of performing lexical/keyword and semantic searches separately, hybrid search simplifies the code for your application.
SingleStore’s implementation of these new indexing strategies also allows us to quickly incorporate new strategies as they become available, ensuring that your application will always perform its best when backed by SingleStoreDB.
When you’re working with extremely large data sets, one of the best things you can do to keep your performance and cost in check is to perform the compute work as close to the data as possible. SingleStore compute service enables you to deploy compute resources (CPUs and GPUs) for AI, machine learning, or ETL (extract, transform, load) workloads alongside your data. With compute service, SingleStore customers can use these new compute resources to run their own machine learning models or other software in a way that allows them to have the full context of their enterprise data, without worrying about egress performance and cost.
Coupling compute service with job service (private preview), you can schedule SQL and Python jobs from within SingleStore Notebooks to process their data, train or fine-tune a machine learning model, or do other complex data transformation work. If your company often updates the fine-tuning of your AI model or LLM, you can now do so in a scheduled manner—using optimized compute platforms that live next to your data.
Many engineers and data scientists are comfortable working with Jupyter Notebooks, hosted, interactive, shareable documents in which you can write and execute code blocks, interspersed with documentation, and visualize data. What is often missing in a Jupyter environment are native connections to your databases and SQL functionality.
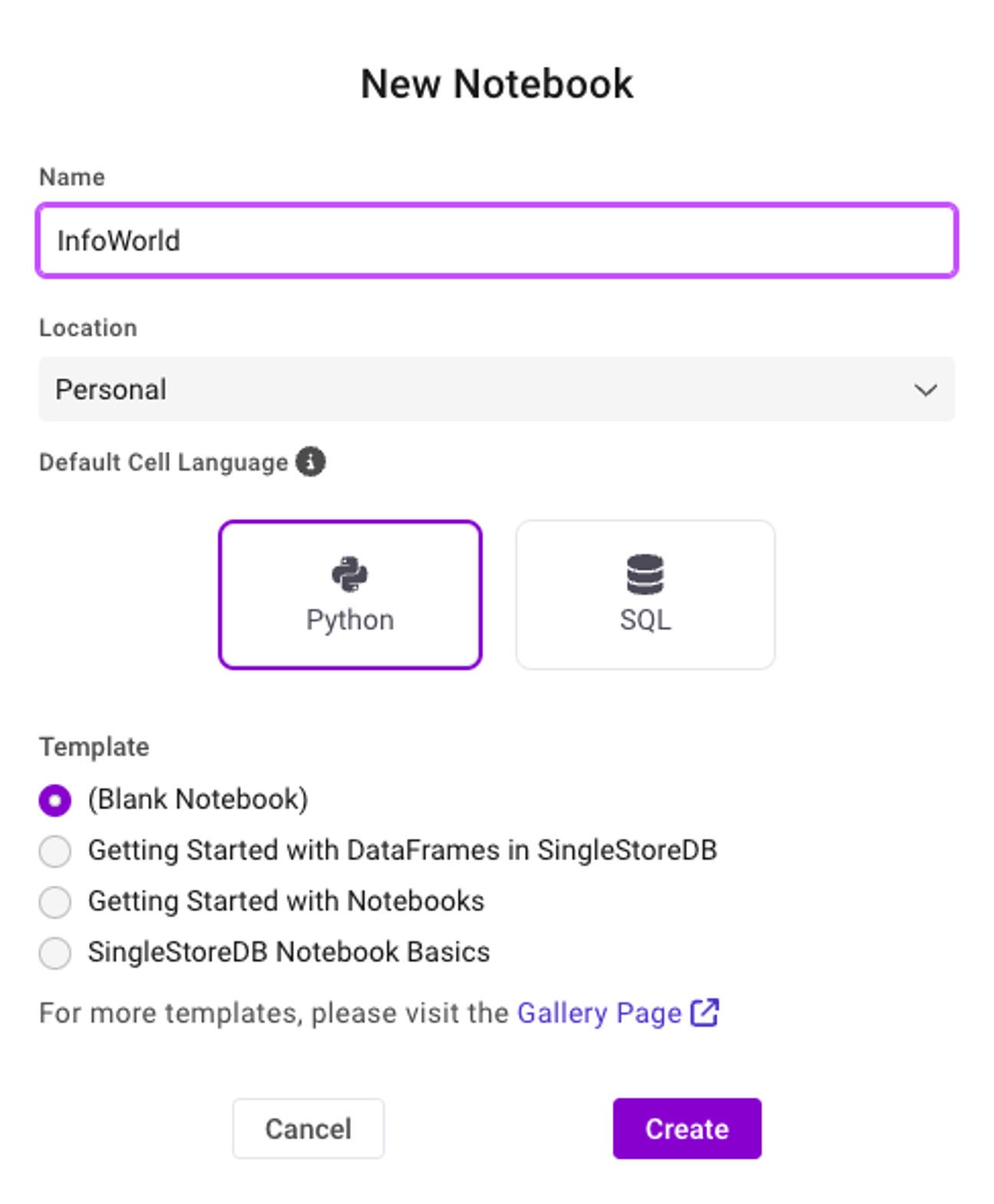
With the announcement of general availability of SingleStore Notebooks, SingleStore makes it easy for you to explore, visualize, and collaborate with your data and peers in real time. Getting started with SingleStore Notebooks is extremely simple:
In the navigation pane on the left, you’ll see Notebooks. Click the plus sign next to Notebooks and fill out the details. If you intend on sharing this notebook with your colleagues, ensure that you choose Shared under Location. Set the Default Cell Language to the language you will primarily use in the notebook, then click create.
Note: You can also choose one of the templates or select from the gallery, if you’d like to see how a Notebook can look.
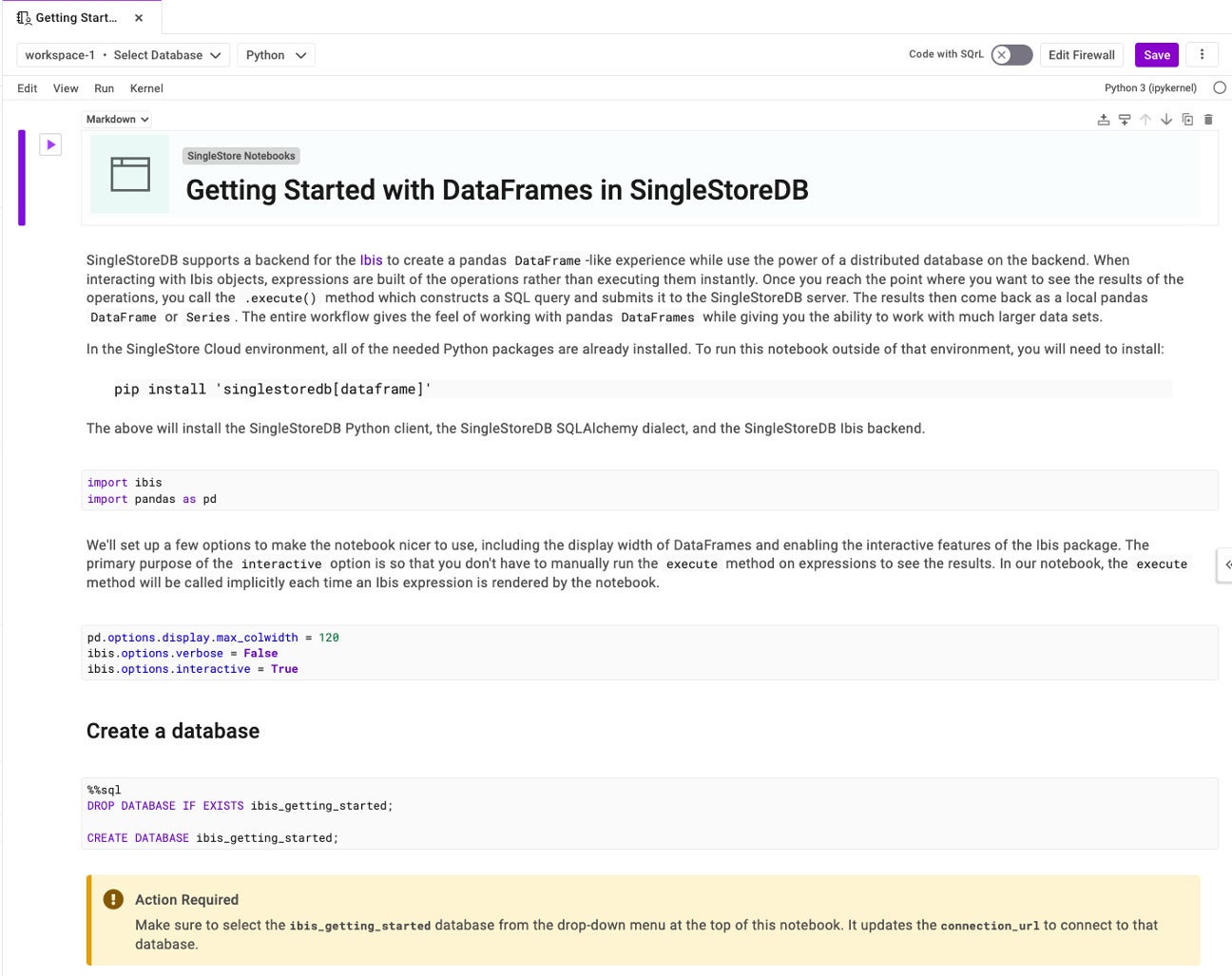
For a handy example, I have imported a notebook from the gallery called “Getting Started with DataFrames in SingleStoreDB.” This notebook walks you through the process of using pandas DataFrames to better take advantage of the distributed nature of SingleStoreDB.
When you select the Workspace and Database at the top of the notebook, it will update the connection_url variable so you can quickly and easily connect to and work with your data.
In this notebook, we use a simple command, conn = ibis.singlestoredb.connect(), to create a connection to the database. No more worrying about putting together the connection string, removing one more thing from the complex process of prototyping something using your data.
In Notebooks, you simply select the Play button next to each cell to run that code block. In the screenshot above, we’re importing packages ibis and pandas.
SingleStore Notebooks is an extremely powerful platform that will allow you to prototype applications, perform data analysis, and quickly repeat tasks that you may need to perform using your data living inside of SingleStoreDB. This rapid prototyping is an extremely effective way to see how you could implement AI, LLMs, or other big data methods into your business.
Be sure to check out SingleStore Spaces to see a large sample of Notebooks that showcase anything from image matching to building LLM apps that use retrieval-augmented generation (RAG) on your own data.
SingleStore Elegance is an NPM package designed to help React developers rapidly build applications on top of SingleStoreDB using SingleStore Kai or MySQL connections to the database. With the release of Elegance, there has never been a better time to develop an AI application that is backed by SingleStoreDB.
Elegance offers a powerful SDK covering a number of features:
Getting started with a demo application is as simple as following just a few simple steps:
git clone https://github.com/singlestore-labs/elegance-sdk-app-books-chat.git
npm i
sh ./scripts/start.sh
If you’d prefer to start from scratch and build something on your own, you can get started with a simple npm install @singlestore/elegance-sdk and follow the steps from our package page on npmjs.com.
The business landscape is changing rapidly with the mainstreaming of AI and LLMs, causing nearly everyone to evaluate whether or not they should implement some form of AI. Many companies are already putting together POCs. These releases show that SingleStore is 100% focused on building a real-time analytics and AI database that gives you the tooling you need to build your applications quickly and efficiently—getting your AI and LLM projects to market faster.
That wraps up the AI innovations that emerged from SingleStore Now. In case you were unable to make the event in person, you can watch all of the sessions on demand.
Wes Kennedy is a principal evangelist at SingleStore, where he creates content, demo environments, and videos and dives into ways that we can meet customers where they are. He has a diverse background in tech covering everything from being a virtualization engineer, sales engineer, to technical marketing.
—
Generative AI Insights provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss the challenges and opportunities of generative artificial intelligence. The selection is wide-ranging, from technology deep dives to case studies to expert opinion, but also subjective, based on our judgment of which topics and treatments will best serve InfoWorld’s technically sophisticated audience. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Contact doug_dineley@foundryco.com.
Next read this:
Posted by Richy George on 29 January, 2024
Generative AI has had an immediate and enormous impact on software development. Software developers have embraced generative AI tools that help with coding, and they are working feverishly to build generative AI applications themselves. Databases can help—especially fast, scalable, multi-model databases like SingleStore.
At the inaugural SingleStore Now conference, SingleStore announced several AI-focused innovations with developers in mind. These include SingleStore Scope, Aura, Notebooks, and the Elegance SDK. Given the impact that AI and LLMs are having on developers, it makes sense to dive into the ways that these innovations make developing AI applications easier.
If you’ve been working with AI or LLMs in any way, you know that vector databases have become much more popular because of their ability to help you search for the nearest n representations of the data you’re working with. You can then use those search results to provide additional context to your LLM to make the responses more accurate. SingleStoreDB has supported vector functions and vector search for a number of years now, but generative AI applications require you to search among millions or billions of vector embeddings in milliseconds—which gets difficult using k-Nearest Neighbor (kNN) across huge data sets.
Scope adds Approximate Nearest Neighbor (ANN) search as an additional option to the already existing k-Nearest Neighbor (kNN) search. The primary difference between ANN and kNN is in the name: approximate vs. nearest. Initial testing shows ANN to be orders of magnitude faster for vector search, taking your AI use cases from fast to real time. Real-time vector search ensures that your applications respond instantly to queries, even when that data has just been written to the database.
Scope uses a number of techniques to make your search functions more performant, namely inverted file (IVF) with product quantization (PQ). With IVF with PQ, you can lower the build times of your index while improving the compression ratios and memory footprint of your vector searches. Beyond IVF with PQ, Scope adds the hierarchical navigable small world (HNSW) approach to allow for high-performance vector index searches using high dimensionality.
With Scope, you can combine all of these new indexing approaches, along with full-text search, to combine hybrid semantic (vector similarity) and lexical/keyword search in one query.
Below you can see an example of using hybrid search. To view the code in its broader context, check out the full notebook on SingleStore Spaces.
hyb_query = 'Articles about Aussie captures'
hyb_embedding = model.encode(hyb_query)
# Create the SQL statement.
hyb_statement = sa.text('''
SELECT
title,
description,
genre,
DOT_PRODUCT(embedding, :embedding) AS semantic_score,
MATCH(title, description) AGAINST (:query) AS keyword_score,
(semantic_score + keyword_score) / 2 AS combined_score
FROM news.news_articles
ORDER BY combined_score DESC
LIMIT 10
''')
# Execute the SQL statement.
hyb_results = pd.DataFrame(conn.execute(hyb_statement, dict(embedding=hyb_embedding, query=hyb_query)))
hyb_results
The above query finds the average scores of semantic and keyword searches, combines them, and sorts the news articles by this calculated score. By removing the extra complexity of performing lexical/keyword and semantic searches separately, hybrid search simplifies the code for your application.
SingleStore’s implementation of these new indexing strategies also allows us to quickly incorporate new strategies as they become available, ensuring that your application will always perform its best when backed by SingleStoreDB.
When you’re working with extremely large data sets, one of the best things you can do to keep your performance and cost in check is to perform the compute work as close to the data as possible. SingleStore Aura enables you to deploy compute resources (CPUs and GPUs) for AI, machine learning, or ETL (extract, transform, load) workloads alongside your data. With Aura, SingleStore customers can use these new compute resources to run their own machine learning models or other software in a way that allows them to have the full context of their enterprise data, without worrying about egress performance and cost.
Coupling Aura with Aura Job Service (private preview), you can schedule SQL and Python jobs from within SingleStore Notebooks to process their data, train or fine-tune a machine learning model, or do other complex data transformation work. If your company often updates the fine-tuning of your AI model or LLM, you can now do so in a scheduled manner—using optimized compute platforms that live next to your data.
Many engineers and data scientists are comfortable working with Jupyter Notebooks, hosted, interactive, shareable documents in which you can write and execute code blocks, interspersed with documentation, and visualize data. What is often missing in a Jupyter environment are native connections to your databases and SQL functionality.
With the announcement of general availability of SingleStore Notebooks, SingleStore makes it easy for you to explore, visualize, and collaborate with your data and peers in real time. Getting started with SingleStore Notebooks is extremely simple:
In the navigation pane on the left, you’ll see Notebooks. Click the plus sign next to Notebooks and fill out the details. If you intend on sharing this notebook with your colleagues, ensure that you choose Shared under Location. Set the Default Cell Language to the language you will primarily use in the notebook, then click create.
Note: You can also choose one of the templates or select from the gallery, if you’d like to see how a Notebook can look.
For a handy example, I have imported a notebook from the gallery called “Getting Started with DataFrames in SingleStoreDB.” This notebook walks you through the process of using pandas DataFrames to better take advantage of the distributed nature of SingleStoreDB.
When you select the Workspace and Database at the top of the notebook, it will update the connection_url variable so you can quickly and easily connect to and work with your data.
In this notebook, we use a simple command, conn = ibis.singlestoredb.connect(), to create a connection to the database. No more worrying about putting together the connection string, removing one more thing from the complex process of prototyping something using your data.
In Notebooks, you simply select the Play button next to each cell to run that code block. In the screenshot above, we’re importing packages ibis and pandas.
SingleStore Notebooks is an extremely powerful platform that will allow you to prototype applications, perform data analysis, and quickly repeat tasks that you may need to perform using your data living inside of SingleStoreDB. This rapid prototyping is an extremely effective way to see how you could implement AI, LLMs, or other big data methods into your business.
Be sure to check out SingleStore Spaces to see a large sample of Notebooks that showcase anything from image matching to building LLM apps that use retrieval-augmented generation (RAG) on your own data.
SingleStore Elegance is an NPM package designed to help React developers rapidly build applications on top of SingleStoreDB using SingleStore Kai or MySQL connections to the database. With the release of Elegance, there has never been a better time to develop an AI application that is backed by SingleStoreDB.
Elegance offers a powerful SDK covering a number of features:
Getting started with a demo application is as simple as following just a few simple steps:
git clone https://github.com/singlestore-labs/elegance-sdk-app-books-chat.git
npm i
sh ./scripts/start.sh
If you’d prefer to start from scratch and build something on your own, you can get started with a simple npm install @singlestore/elegance-sdk and follow the steps from our package page on npmjs.com.
The business landscape is changing rapidly with the mainstreaming of AI and LLMs, causing nearly everyone to evaluate whether or not they should implement some form of AI. Many companies are already putting together POCs. These releases show that SingleStore is 100% focused on building a real-time analytics and AI database that gives you the tooling you need to build your applications quickly and efficiently—getting your AI and LLM projects to market faster.
That wraps up the AI innovations that emerged from SingleStore Now. In case you were unable to make the event in person, you can watch all of the sessions on demand.
Wes Kennedy is a principal evangelist at SingleStore, where he creates content, demo environments, and videos and dives into ways that we can meet customers where they are. He has a diverse background in tech covering everything from being a virtualization engineer, sales engineer, to technical marketing.
—
Generative AI Insights provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss the challenges and opportunities of generative artificial intelligence. The selection is wide-ranging, from technology deep dives to case studies to expert opinion, but also subjective, based on our judgment of which topics and treatments will best serve InfoWorld’s technically sophisticated audience. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Contact doug_dineley@foundryco.com.
Next read this:
Posted by Richy George on 29 January, 2024
In August 2023, a small group of Google development and UX leads bewailed the difficulty of setting up a development environment for multiplatform and full-stack apps, and offered their take on an experimental prototype intended to solve the issues. Difficulty setting up technology stacks for development is not a new problem. It has been an issue since at least the early 1980s, when personal computers became available.
Project IDX is a browser-based development environment built on Code OSS and powered by Codey, a generative AI foundation model trained on code and built on PaLM 2. Project IDX is designed to make it easier to build, manage, and deploy full-stack web and multiplatform applications, using popular frameworks and languages.
Code OSS is the fully open-source version of Microsoft’s Visual Studio Code. The latter has a few proprietary additions, despite being free software.
At the time of its announcement in August, Project IDX was only available through a waitlist sign-up; my application was finally approved in December. Project IDX is still very much a rough-edged preview, but has an interesting design and some utility, even if it’s not yet intended for use in a production environment.
There are several products that compete with Project IDX at some level. These include AWS Cloud9, Gitpod, Online IDE, Replit, StackBlitz, Eclipse Che, Codeanywhere, and GitHub Codespaces.
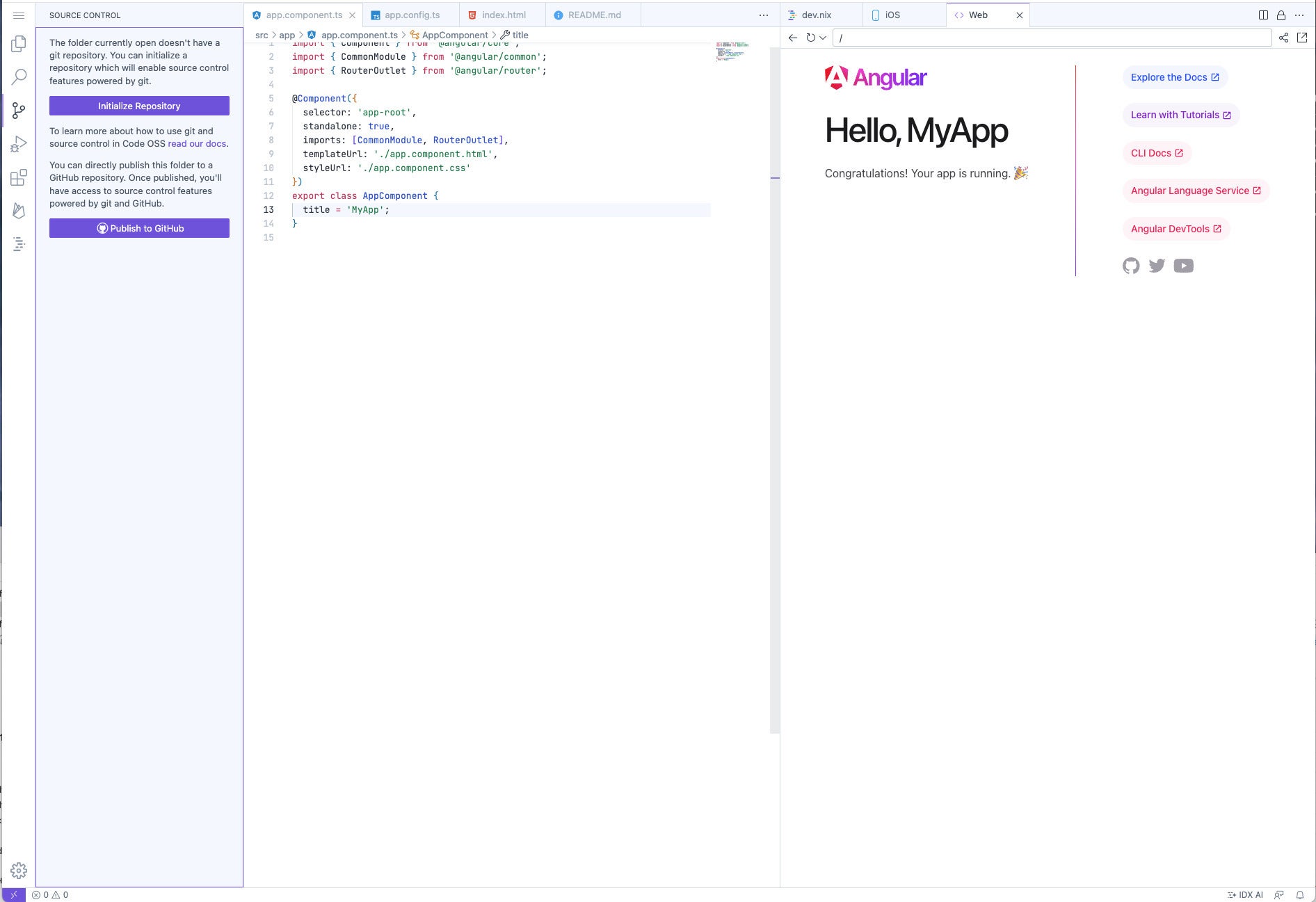
There are a number of features that make Project IDX look promising despite its rough edges and its feel of being under construction. For starters, it’s actually a familiar environment for anyone who uses Visual Studio Code. As I understand it, the portions of VS Code that aren’t included in Code OSS are the Microsoft-specific customizations, which don’t matter too much in this context.
Some of those customizations are replaced by the IDX AI powered by Codey. The IDX AI provides code suggestions as you type and offers an AI-powered code chat you can ask for help with your code, to generate new code, to translate code to another language, to explain code, and to write unit tests. Supposedly, IDX AI also highlights possible license requirements based on AI-generated code, although I haven’t seen that pop up.
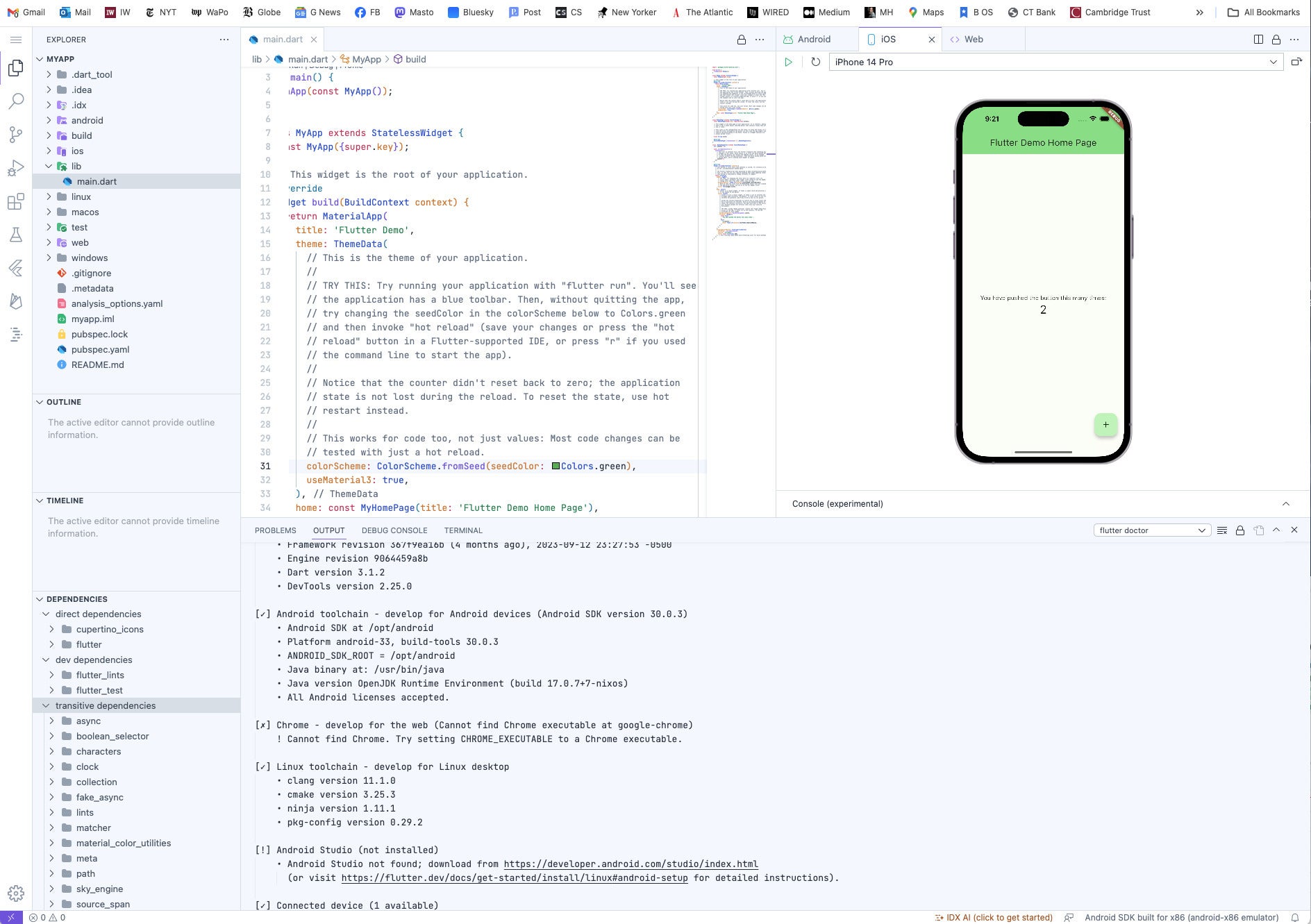
Project IDX will feel familiar because of its similarity to VS Code. The top left “hamburger” menu replaces the top row menu in VS Code, and offers most of the same menu items when it pops out. The icons in the vertical row below that control the contents of the next column to the right, currently showing the file explorer, the code outline for the current file, the timeline for the current file, and the dependencies for the app. The large editing pane currently showing main.dart can display up to four tabs. The preview window to the right can also display the IDX AI pane and additional code file tabs. The large area at the bottom right displays code problems, output, a debug console, and a terminal.
The IDX Code OSS editor runs in a Google Cloud VM, called a Cloud Workstation. Normally, Cloud Workstation time is billed per hour at a rate that varies with the size of the machine type, from $0.16/hour to $9.36/hour. Project IDX is currently free.
Normally, Cloud Workstations support a variety of popular IDEs and Duet AI. Project IDX supports only Code OSS, and Codey instead of Duet. (I can’t tell you the difference between Duet AI and Codey in practice, although it might be an interesting comparison to investigate.) Cloud Workstations can normally run inside your private network and in your staging environment. Project IDX is currently restricted to its own environment.
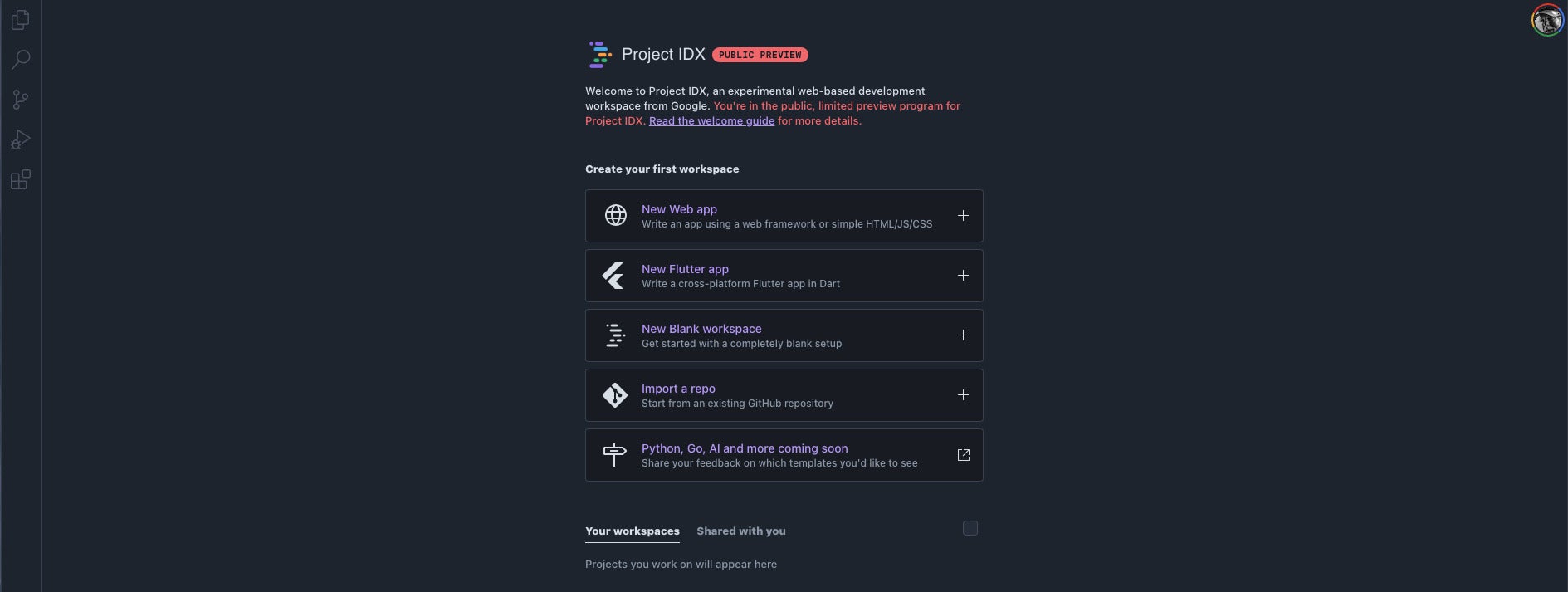
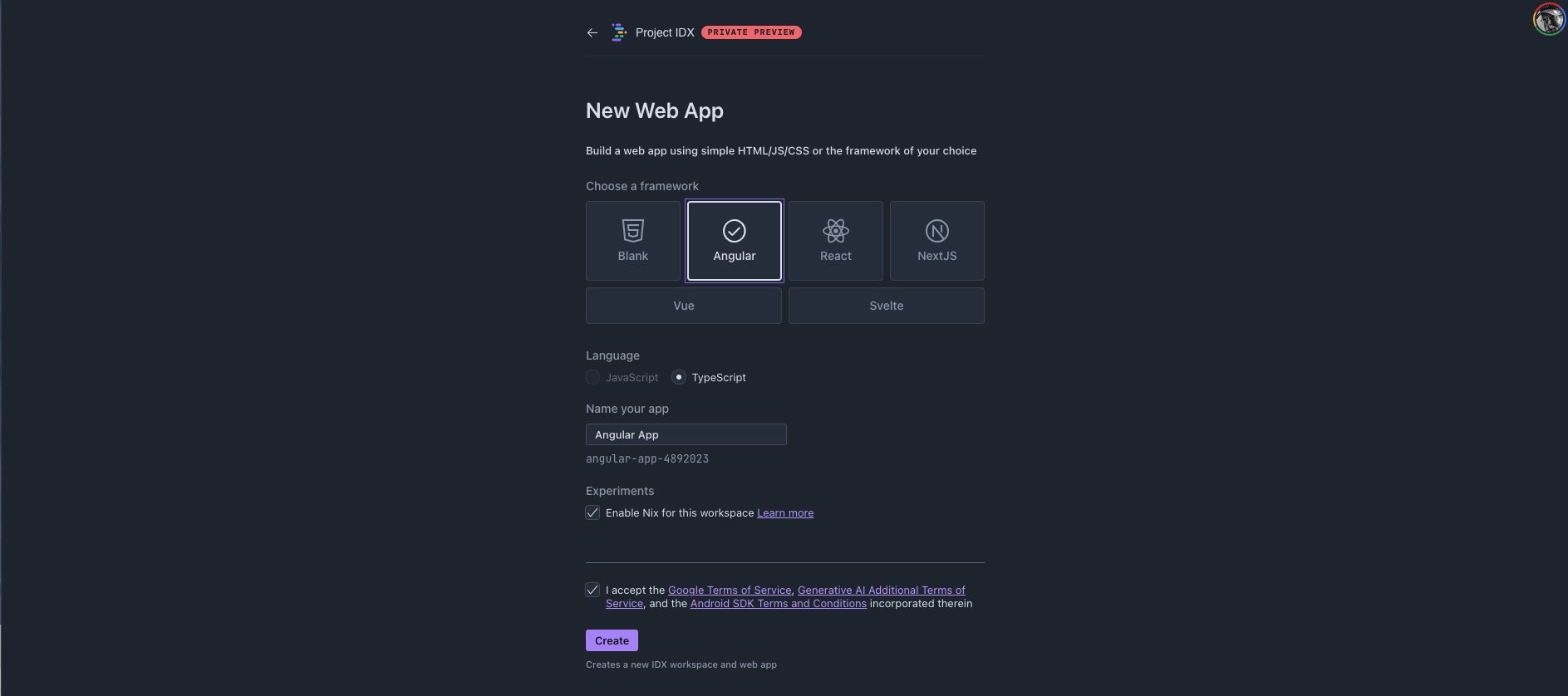
You can create projects in Project IDX with built-in templates and GitHub imports. The templates support the JavaScript, TypeScript, and Dart languages and the Angular, React, NextJS, Vue, Svelte, and Flutter frameworks. In the future, Project IDX is due to support Python, Go, and “AI.” You can optionally use Nix to customize your workspace.
This menu offers you your initial choice of the kind of app you’ll generate or import. Each item (other than the “coming soon” group at the bottom) opens a secondary screen for specifying your app framework and naming your app.
—
The second-level screen for generating a new web app currently offers a choice of six web frameworks. They are Angular, React, Next.js, Vue, Svelte, or a blank app, which implies writing your own HTML, JavaScript/TypeScript, and CSS. Nix is the file you can use to customize a workspace.
GitHub imports can be of three types: web, Flutter, and “other,” which currently appears to mean JavaScript/TypeScript frameworks other than those explicitly listed. The frameworks explicitly supported include Angular, React, Next.js, Vue, and Svelte.
If your GitHub project has JavaScript dependencies, you can run npm install in your IDX terminal window after your import completes. You can also turn your project into a Git repository from within IDX and sync that with GitHub.
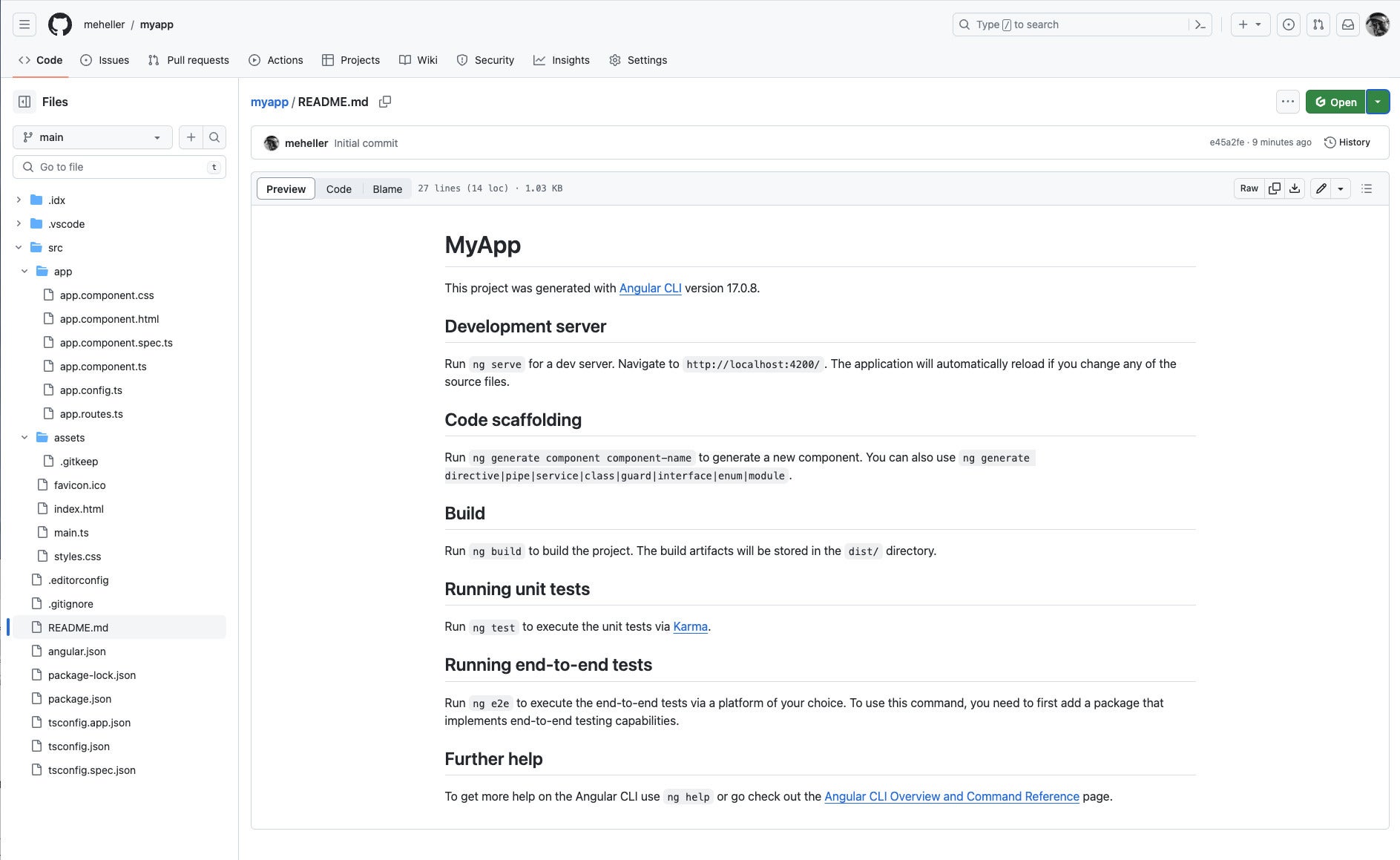
Project IDX integrates well with Git and GitHub. At left, you can see the options to initialize a Git repository and publish it to GitHub.
—
Once you have created a repo and authenticated to GitHub, Project IDX can push the repo to GitHub. Here you can see the typical GitHub display of the README.md file generated for the app by Angular.
In addition to a web preview, Project IDX presents previews in Android emulators and iOS simulators, where supported by the underlying template. All three work for a Flutter app. Only two, web preview and iOS simulator, work for an Angular app, since a stock Angular app isn’t native unless you add something like Ionic or NativeScript.
You can deploy directly from your workspace to Firebase hosting. On an experimental basis, you can share your workspace with complete shared access.
Project IDX comes with pre-installed extensions for the languages and frameworks it supports. It is supposed to support additional extensions that are available from OpenVSX, although I can’t confirm whether all of those work at this point—there are just too many (over 3,000) to check.
One current major limitation of Project IDX is that only two projects are allowed at once. You can get around this by saving projects to GitHub and juggling which you have open in IDX.
Note that there are numerous bug reports beyond the list in the FAQ.
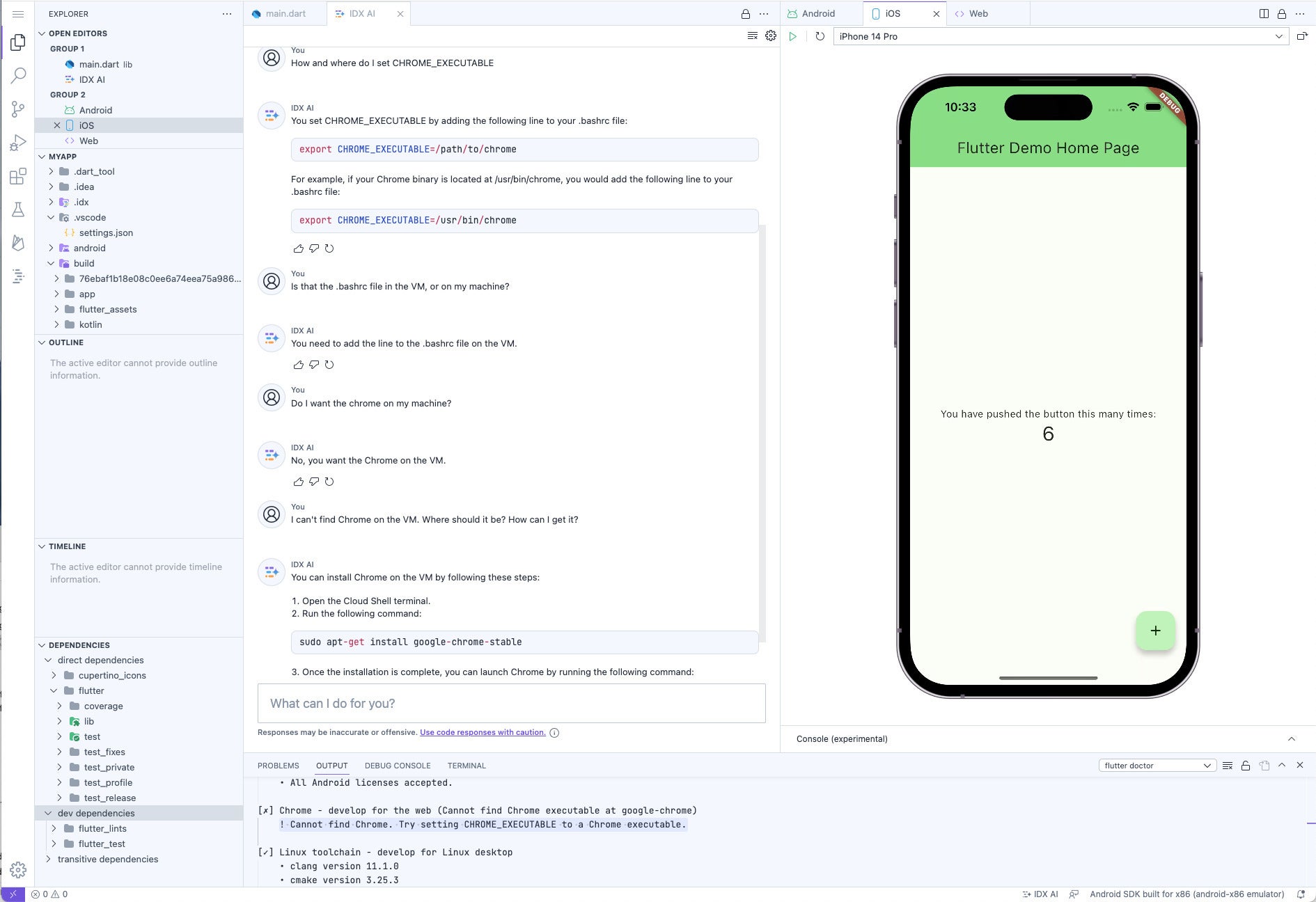
The Flutter app reported two setup errors. Here I am trying to resolve one of them with the help of IDX AI. Unfortunately, the AI’s advice to use sudo apt-get to install Chrome turned out to be useless, since the IDX VM does not currently include either sudo or apt-get. I won’t call that a hallucination, since those utilities might be planned for a future version.
Project IDX shows a lot of promise. It’s visually similar to Visual Studio Code for the Web (which, sadly, lacks a terminal and debugger). It’s both visually and functionally similar to GitHub Codespaces and Gitpod, and it’s functionally similar to Eclipse Che.
One reason you might prefer Project IDX to any of those would be its hosting in a Google Cloud Workspace, which is a big advantage if you want to integrate with any Google Cloud services, or with other programs you have running in the Google Cloud. On the other hand, if your existing code runs on AWS, you might want to consider using AWS Cloud9.
My biggest concern about making a commitment to Project IDX would be Google’s long history of killing its projects and services. Remember Google+? Freebase? The Google Search Appliance? Polymer? Google Domains? All ex-parrots, they’ve rung down the curtain and joined the choir invisible.
Nevertheless, Project IDX has its attractions. As long as you create a GitHub repository from your workspace and keep it current, it’s certainly worth a try.
—
Cost: Free preview
Platform: Browser-based, hosted on Google Cloud
Next read this:





This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →
Copyright 2015 - InnovatePC - All Rights Reserved
Site Design By Digital web avenue