







Dell Latitude E6410 Notebook| Quantity Available: 40+
This post is intended for businesses and other organizations interested... Read more →
Posted by Richy George on 27 February, 2024
Amazon Web Services’ fully managed service for building, deploying, and scaling generative AI applications, Amazon Bedrock offers a catalog of foundation models, implements retrieval-augmented generation (RAG) and vector embeddings, hosts knowledge bases, implements fine-tuning of foundation models, and allows continued pre-training of selected foundation models.
Amazon Bedrock complements the almost 30 other Amazon machine learning services available, including Amazon Q, the AWS generative AI assistant.
There are currently six major features in Amazon Bedrock:
One major competitor to Amazon Bedrock is Azure AI Studio, which, while still in preview and somewhat under construction, checks most of the boxes for a generative AI application builder. Azure AI Studio is a nice system for picking generative AI models, grounding them with RAG using vector embeddings, vector search, and data, and fine-tuning them, all to create what Microsoft calls copilots, or AI agents.
Another major competitor is Google Vertex AI’s Generative AI Studio, which allows you to tune foundation models with your own data, using tuning options such as adapter tuning and reinforcement learning from human feedback (RLHF), or style and subject tuning for image generation. Generative AI Studio complements the Vertex AI model garden and foundation models as APIs.
Other possible competitors include LangChain (and LangSmith), Poe, and the ChatGPT GPT Builder. LangChain does require you to do some programming.
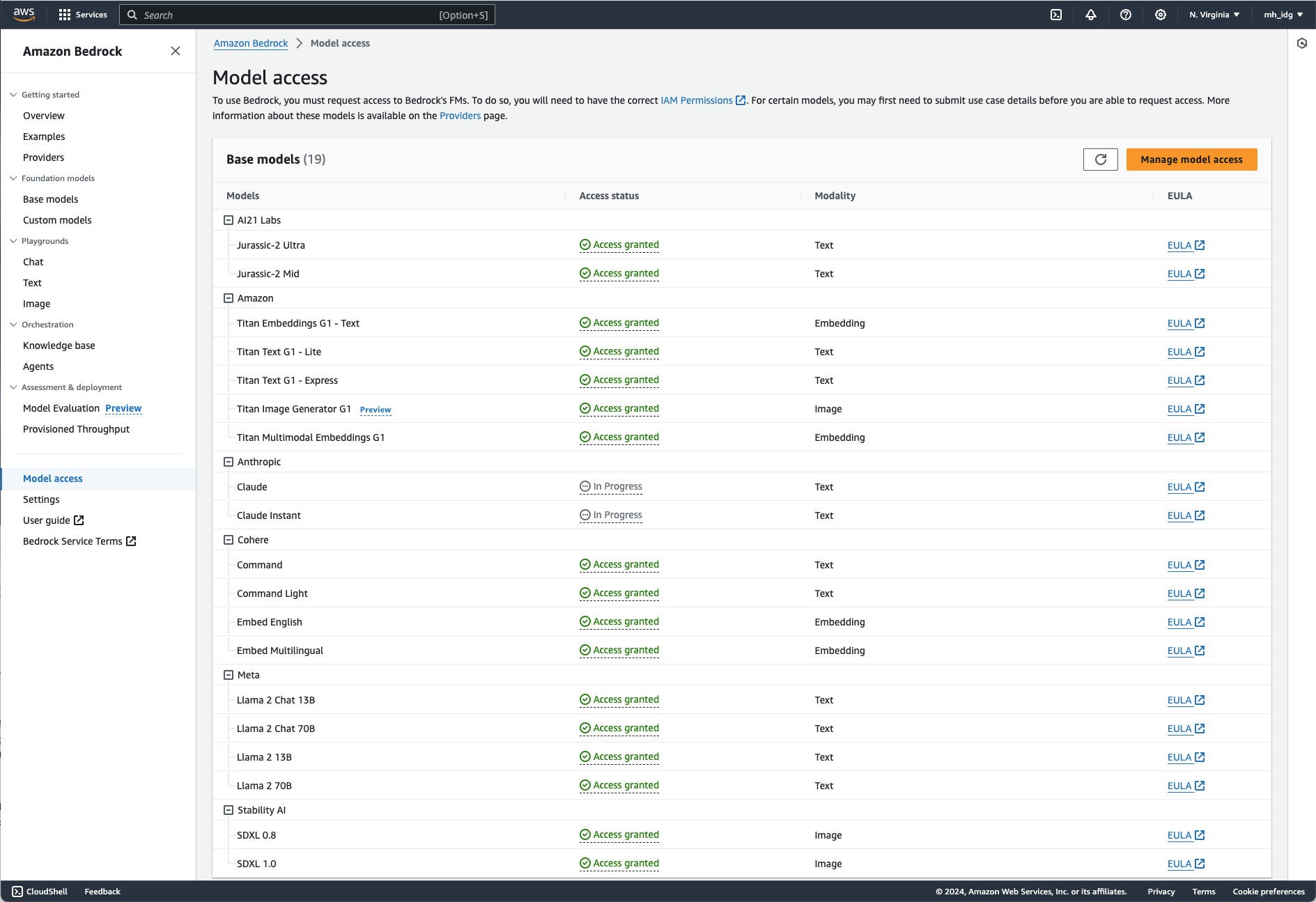
There are two setup tasks for Bedrock: model setup and API setup. You need to request access to models before you can use them. If you want to use the AWS command line interface or any of the AWS SDKs, you also need to install and configure the CLI or SDK.
I didn’t bother with API setup, as I’m concentrating on using the console for the purposes of this review. Completing the model access request form was easier than it looked, and I was granted access to models faster than I expected.
You can’t use a model in Amazon Bedrock until you’ve requested and received permission to use it. Most vendors grant access immediately. Anthropic takes a few minutes, and requires you to fill out a short questionnaire about your planned usage. This screenshot was taken just before my Claude access requests were granted.
Amazon Bedrock uses slightly different parameters to control the response of models than, say, OpenAI. Bedrock controls randomness and diversity using the temperature of the probability distribution, the top K, and the top P. It controls the length of the output with the response length, penalties, and stop sequences.
Temperature modulates the probability for the next token. A lower temperature leads to more deterministic responses, and a higher temperature leads to more random responses. In other words, choose a lower temperature to increase the likelihood of higher-probability tokens and decrease the likelihood of lower-probability tokens; choose a higher temperature to increase the likelihood of lower-probability tokens and decrease the likelihood of higher-probability tokens. For example, a high temperature would allow the completion of “I hear the hoof beats of” to include unlikely beasts like unicorns, while a low temperature would weight the output to likely ungulates like horses.
Top K is the number of most-likely candidates that the model considers for the next token. Lower values limit the options to more likely outputs, like horses. Higher values allow the model to choose less likely outputs, like unicorns.
Top P is the percentage of most-likely candidates that the model considers for the next token. As with top K, lower values limit the options to more likely outputs, and higher values allow the model to choose less likely outputs.
Response length controls the number of tokens in the generated response. Penalties can apply to length, repeated tokens, frequency of tokens, and type of tokens in a response. Stop sequences are sequences of characters that stop the model from generating further tokens.
Amazon Bedrock currently displays 33 examples of generative AI model usage, and offers three playgrounds. Playgrounds provide a console environment to experiment with running inference on different models and with different configurations. You can start with one of the playgrounds (chat, text, or image), select a model, construct a prompt, and set the metaparameters. Or you can start with an example and open it in the appropriate playground with the model and metaparameters pre-selected and the prompt pre-populated. Note that you need to have been granted access to a model before you can use it in a playground.
Amazon Bedrock examples demonstrate prompts and parameters for various supported models and tasks. Tasks include summarization, question answering, problem solving, code generation, text generation, and image generation. Each example shows a model, prompt, parameters, and response, and presents a button you can press to open the example in a playground. The results you get in the playground may or may not match what is shown in the example, especially if the parameters allow for lower-probability tokens.
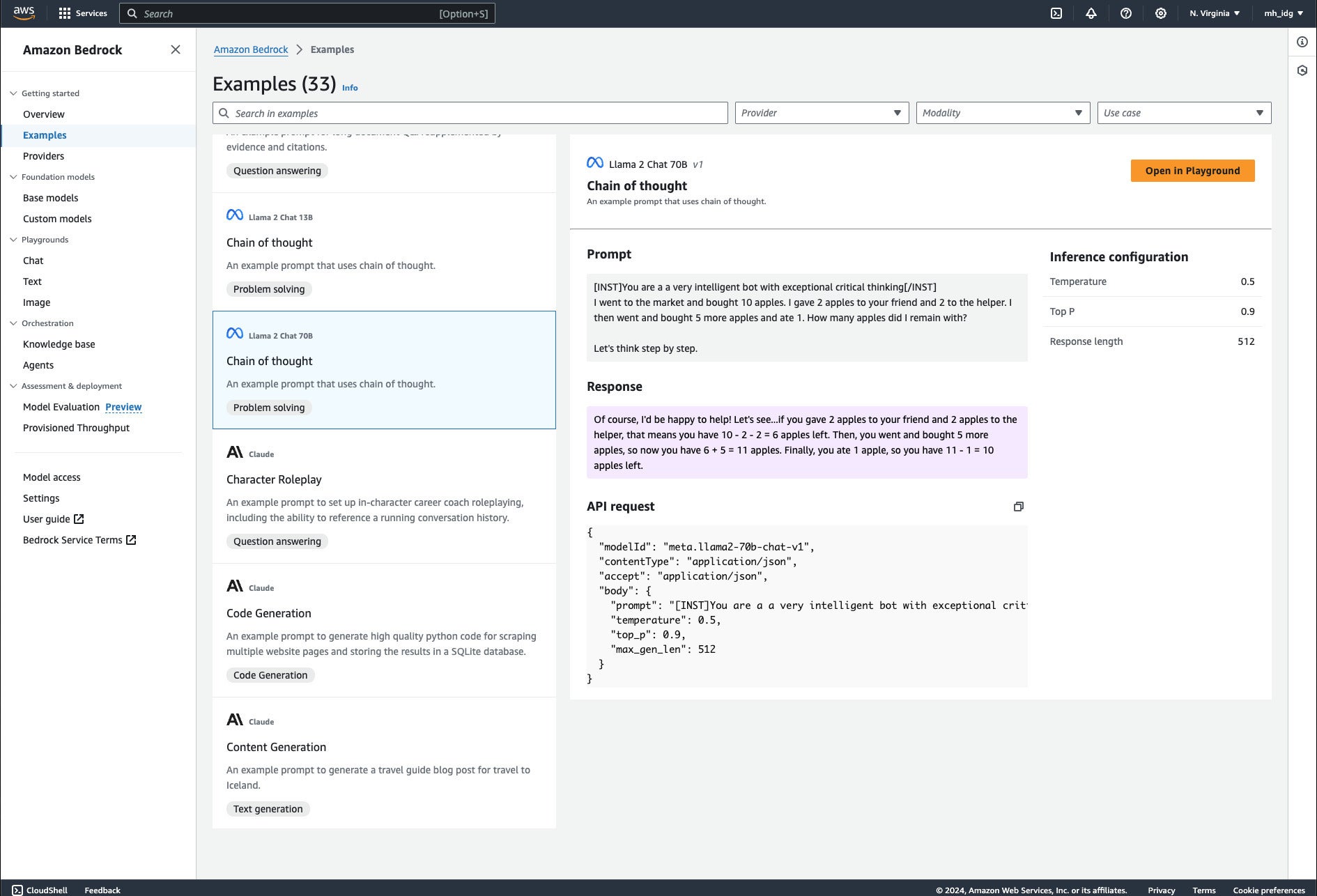
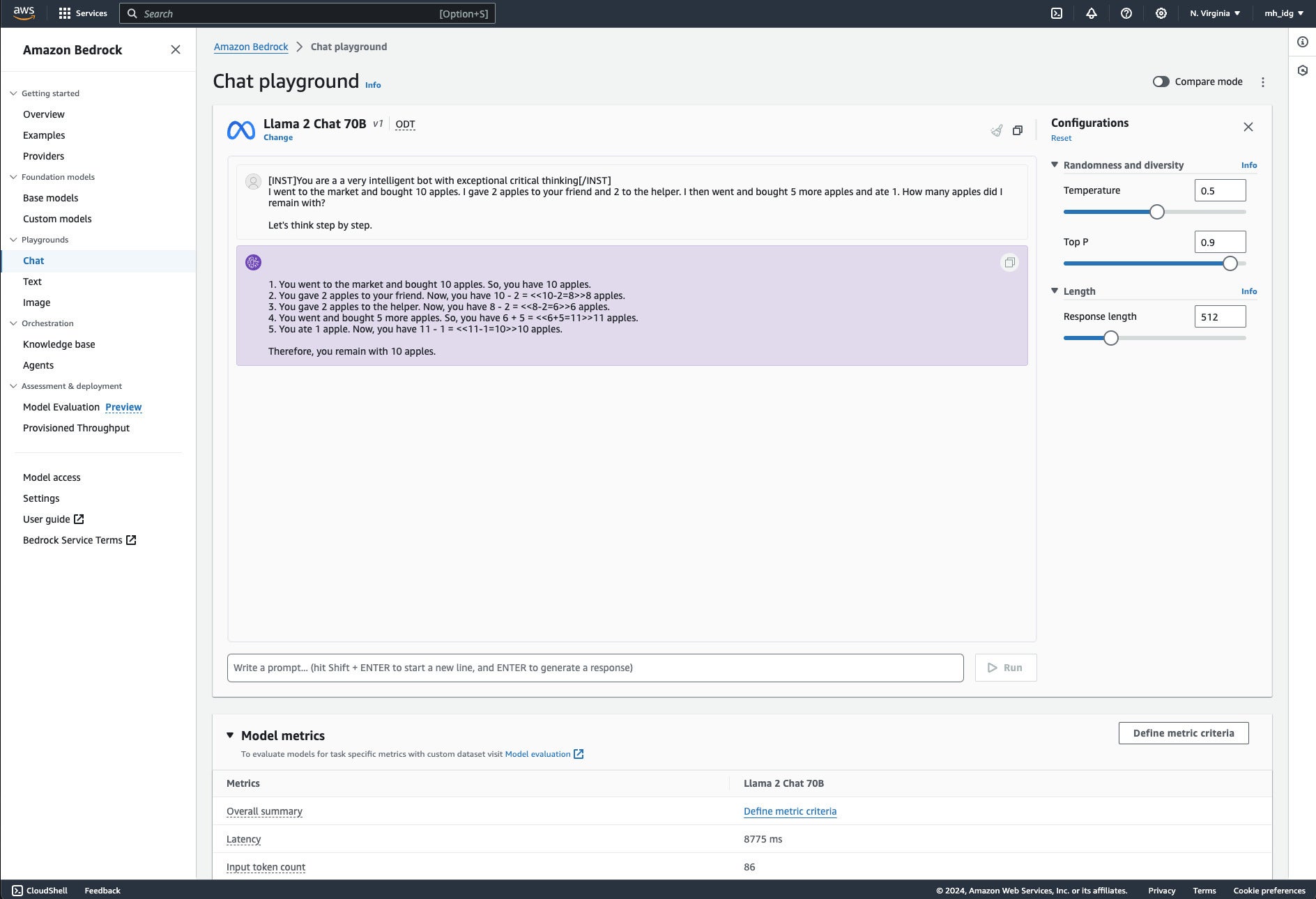
Our first example shows arithmetic word problem solving using a chain-of-thought prompt and the Llama 2 Chat 70B v1 model. There are several points of interest in this example. First, it works with a relatively small open-source chat model. (As an aside, there’s a related example that uses a 7B (billion) parameter model instead of the 70B parameter model used here; it also works.) Second, the chain-of-thought action is triggered by a simple addition to the prompt, “Let’s think step by step.” Note that if you remove that line, the model often goes off the rails and generates a wrong answer.
The chain-of-thought problem-solving example uses a Llama 2 chat model and presents a typical 2nd or 3rd grade arithmetic word problem. Note the [INST]You are a…[/INST] block at the beginning of the prompt. This seems to be specific to Llama. You’ll see other models respond to different formats for defining instructions or system prompts.
The chain-of-thought problem-solving example running in the Amazon Bedrock Chat playground. This particular set of prompts and hyperparameters usually gives correct answers, although not in the exact same format every time. If you remove the “Let’s think step by step” part of the prompt it usually gives wrong answers. The temperature setting of 0.5 asks for moderate randomness in the probability mass function, and the top P setting of 0.9 allows the model to consider less likely outputs.
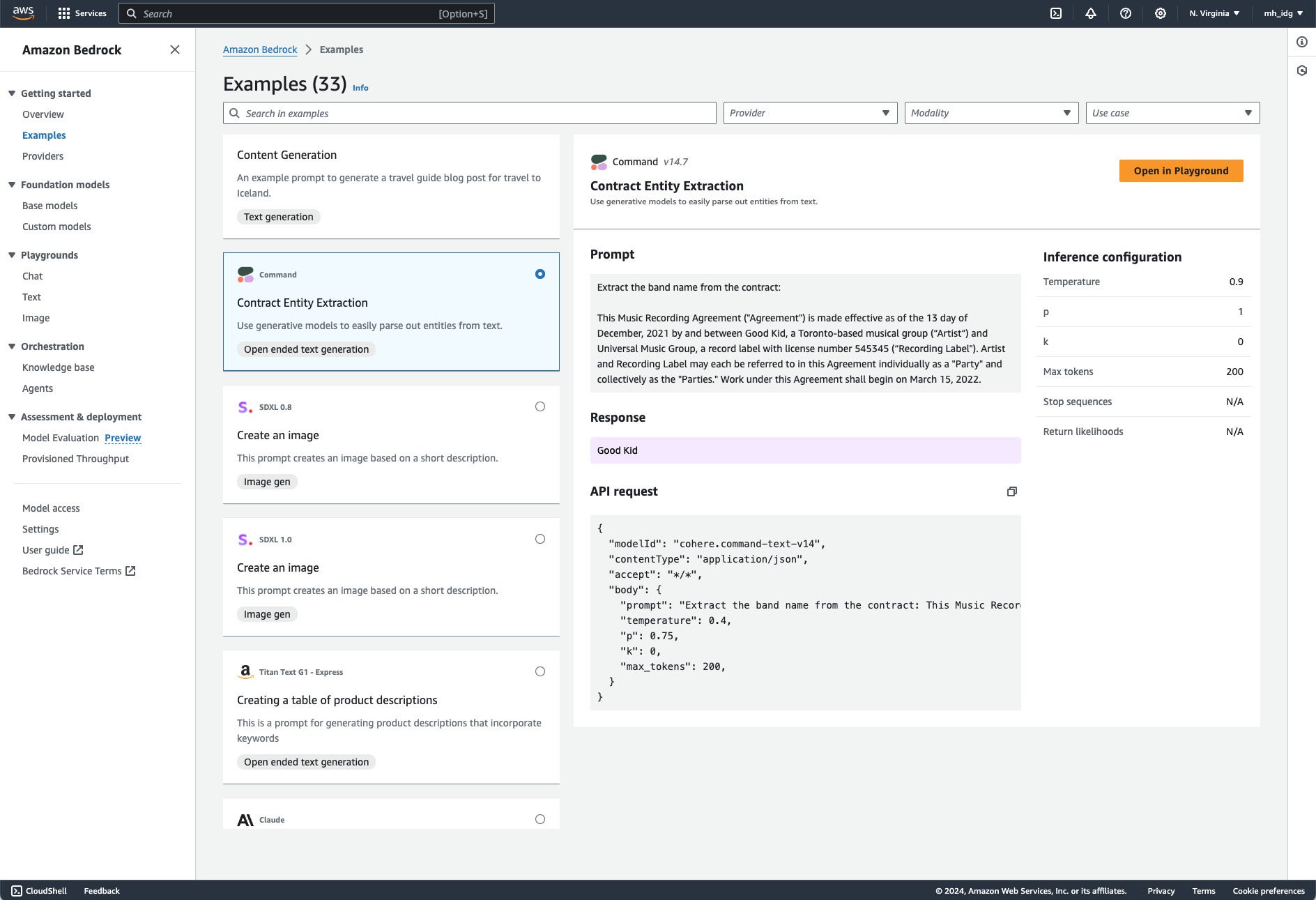
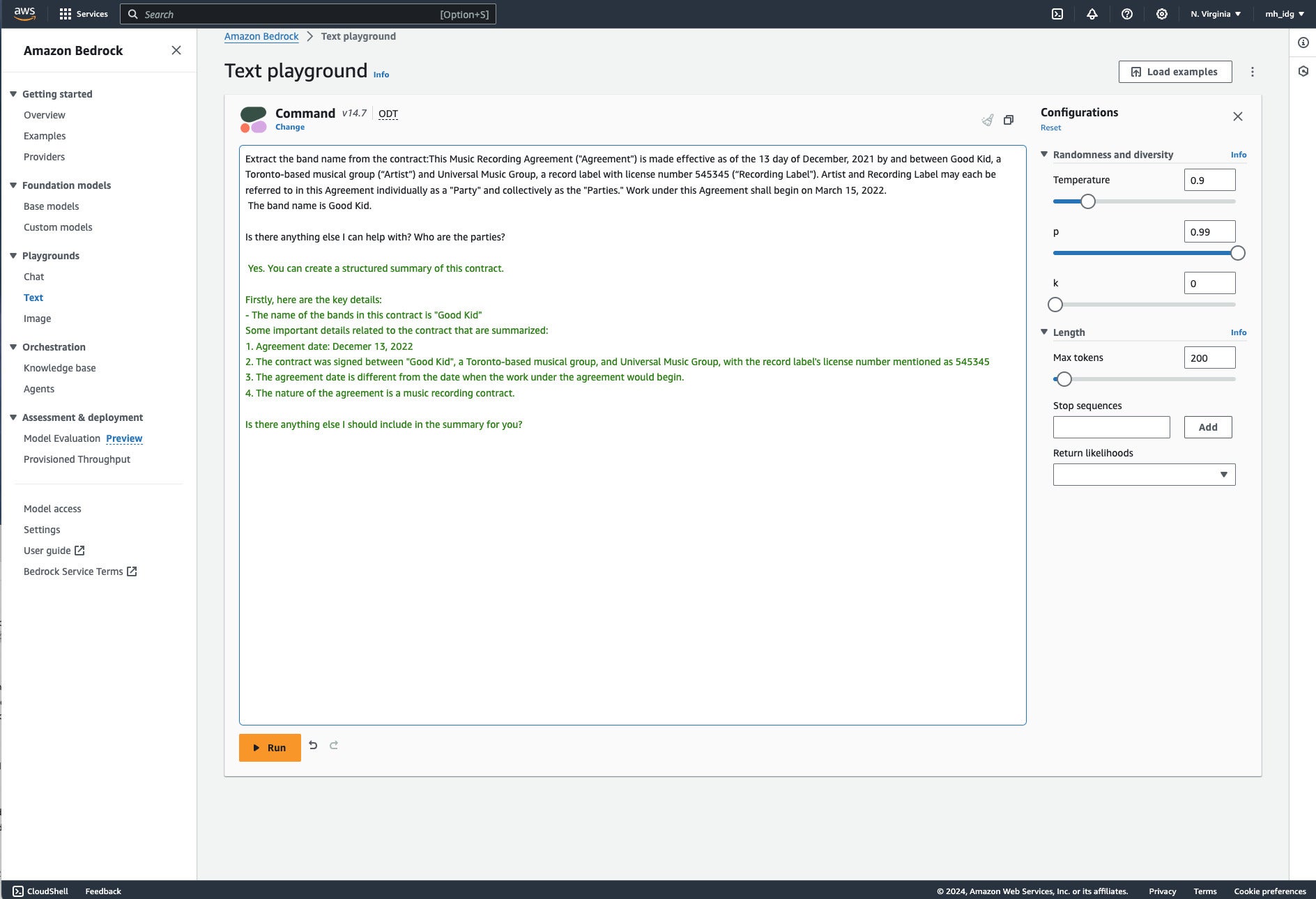
Our second example shows contract entity extraction using Cohere’s Command text generation model. Text LLMs (large language models) often allow for many different text processing functions.
Amazon Bedrock contract entity extraction example using Cohere’s Command text generation model. Note that the instruction here is on the first line followed by a colon, and then the contract body follows.
Contract entity extraction example running in the Amazon Bedrock text playground. Note that there was an opportunity for additional interaction in the playground, which didn’t show up in the example. While the temperature of this run was 0.9, Cohere’s Command model takes temperature values up to 5. The top p value is set to 1 (and displayed at 0.99) and the top k parameter is not set. These allow for high randomness in the generated text.
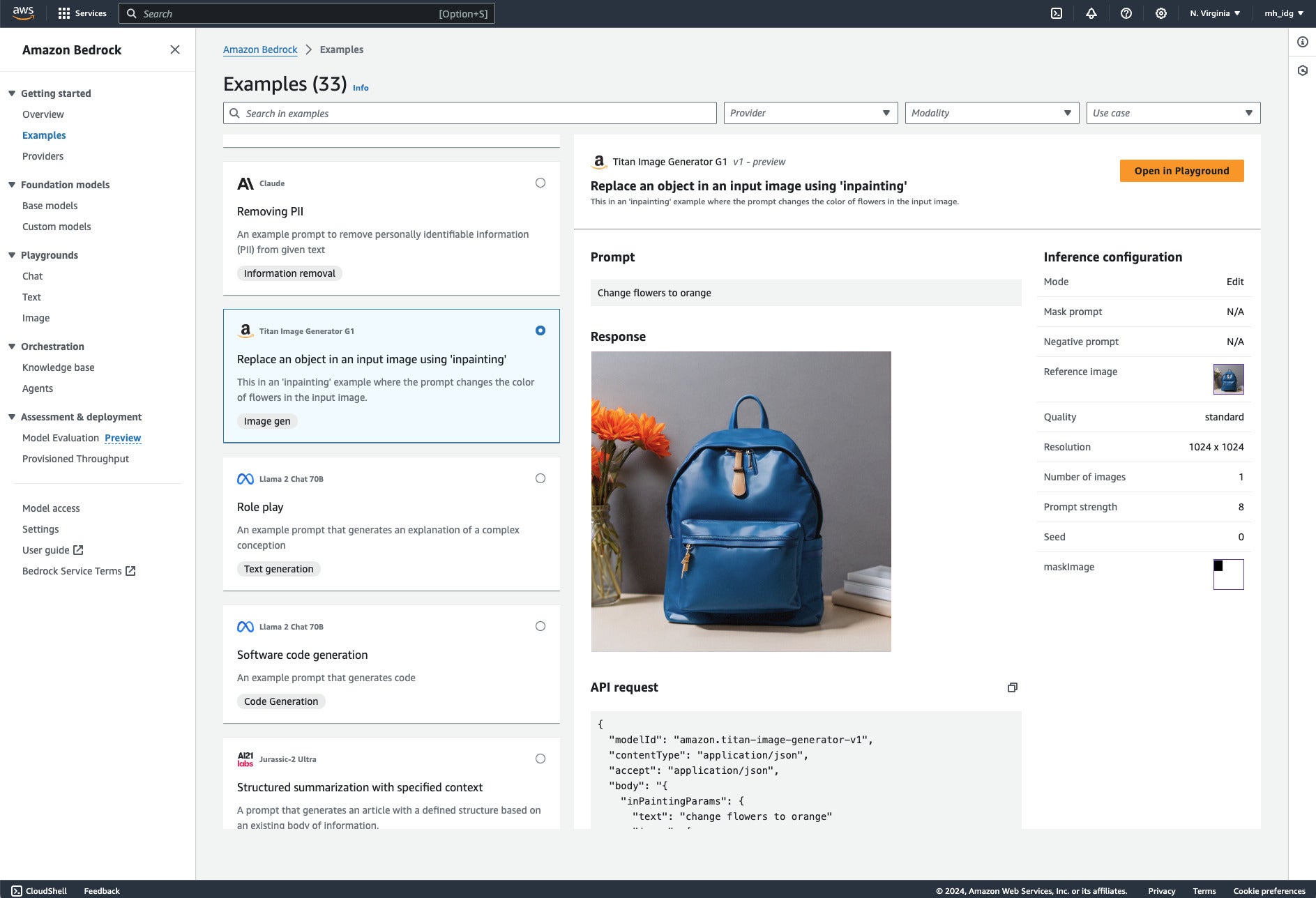
Our final example shows image inpainting, an application of image generation that uses a reference image, a mask, and prompts to produce a new image. Up until now, I’ve only done AI image inpainting in Adobe Photoshop, which has had the capability for awhile.
Amazon Bedrock’s image inpainting example uses the Titan Image Generator G1 model. Note the reference image and mask image in the image configuration.
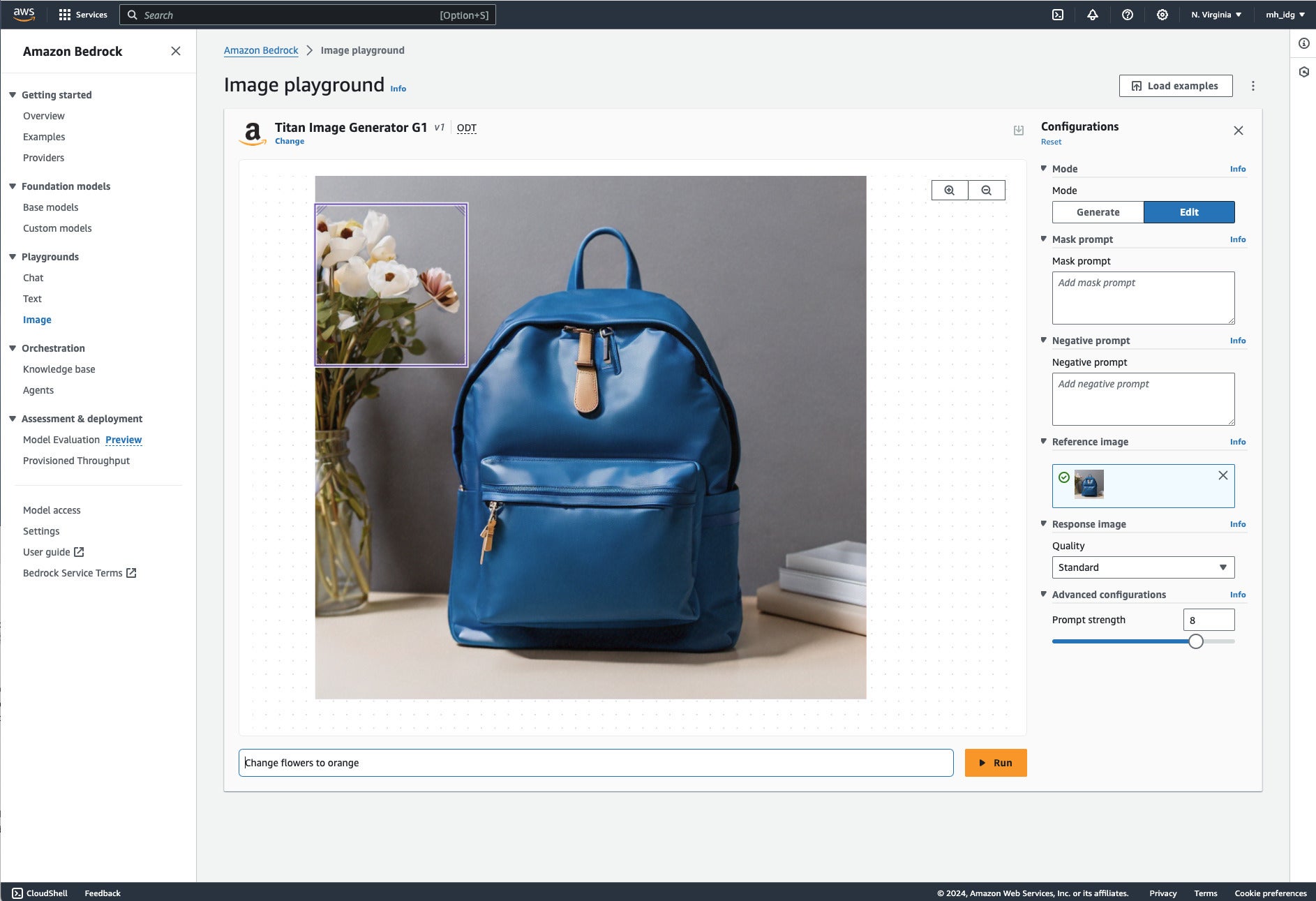
In order to actually select the flowers for inpainting, I had to move the mask from the default selection of the backpack to the area containing the white flowers in the reference image. When I didn’t do that, orange flowers were generated in front of the backpack.
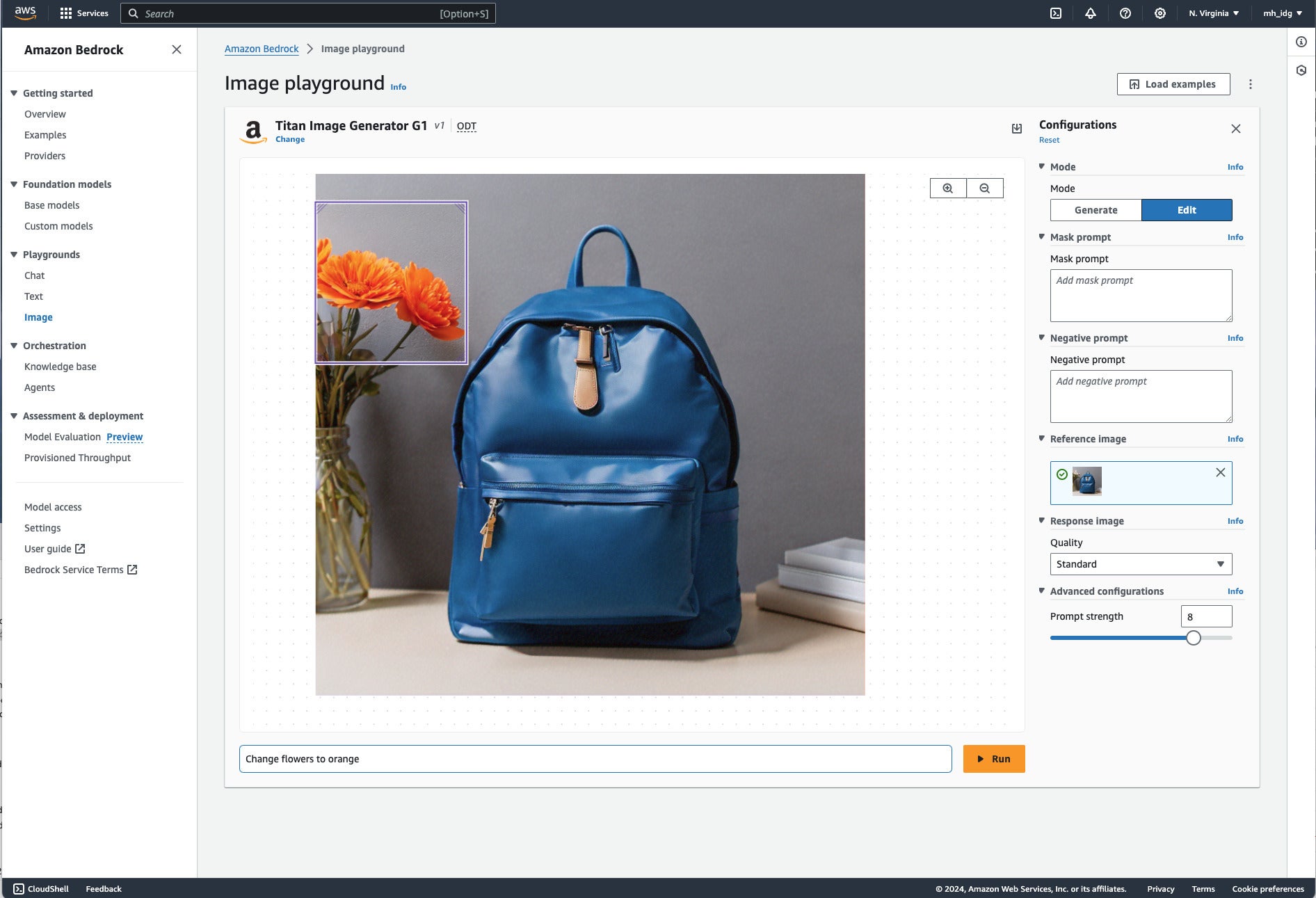
Successful inpainting in Amazon Bedrock. Note that I could have used the mask prompt to refine the mask for complex mask selections in noncontiguous areas, for example selecting the flowers and the books. You can use the Info links to see explanations of individual hyperparameters.
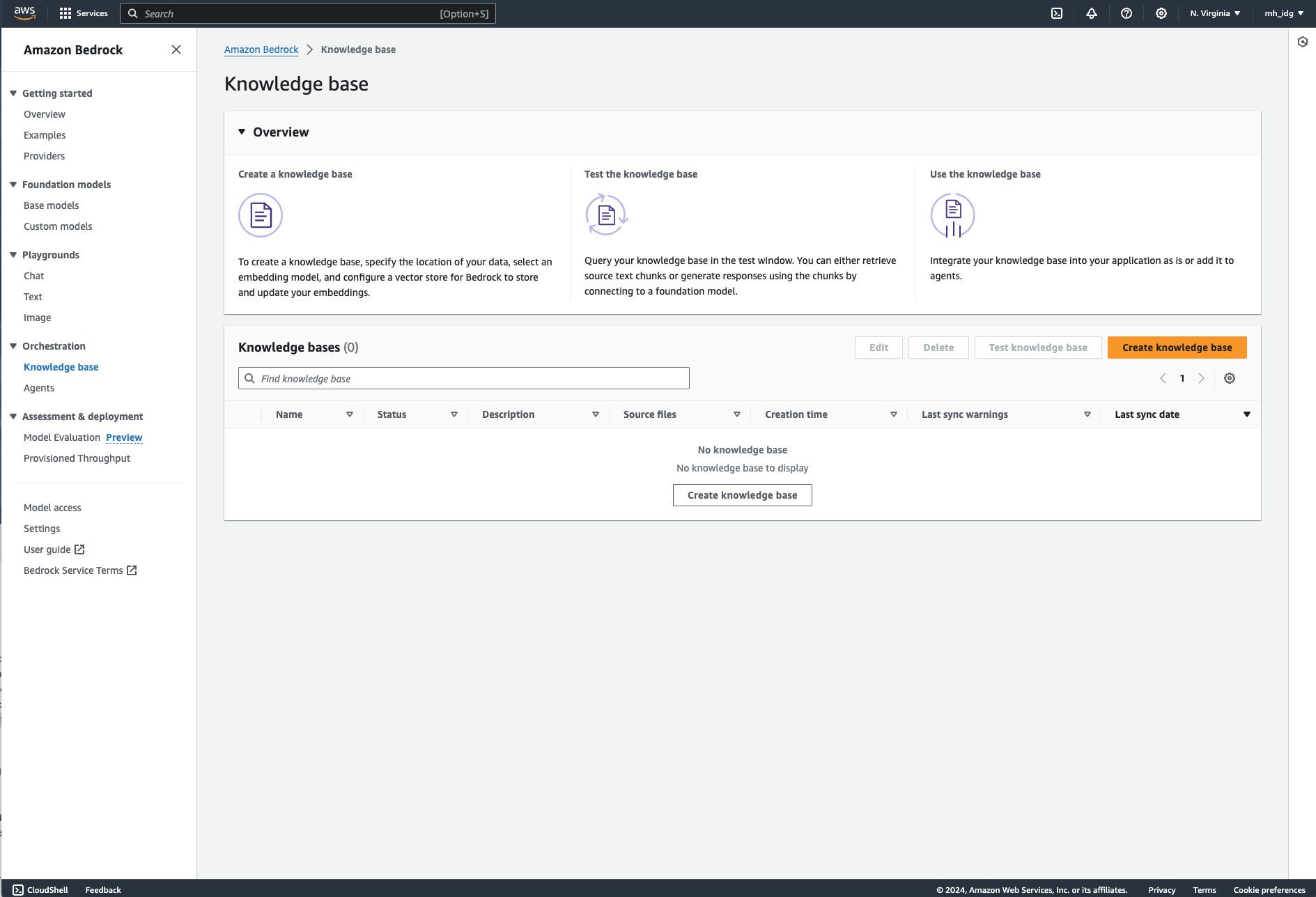
Amazon Bedrock orchestration currently includes importing data sources into knowledge bases that you can then use for setting up RAG, and creating agents that can execute actions. These are two of the most important techniques available for building generative AI applications, falling between simple prompt engineering and expensive and time-consuming continued pre-training or fine-tuning.
Using knowledge bases takes multiple steps. Start by importing your data sources into an Amazon S3 bucket. When you do that, specify the chunking you’d like for your data. The default is approximately 300 tokens per chunk, but you can set your own size. Then set up your vector store and embeddings model in the database you prefer, or allow AWS to use its default of Amazon OpenSearch Serverless. Then create your knowledge base from the Bedrock console, ingest your data sources, and test your knowledge base. Finally, you can connect your knowledge base to a model for RAG, or take the next step and connect it to an agent. There’s a good one-hour video about this by Mani Khanuja, recorded at AWS re:Invent 2023.
Agents orchestrate interactions between foundation models, data sources, software applications, and prompts, and call APIs to take actions. In addition to the components of RAG, agents can follow instructions, use an OpenAPI schema to define the APIs that the agent can invoke, and/or invoke a Lambda function.
Amazon Bedrock knowledge base creation and testing starts with this screen. There are several more steps.
The Assessment and Deployment panel in Amazon Bedrock contains functionality for model evaluation and provisioned throughput.
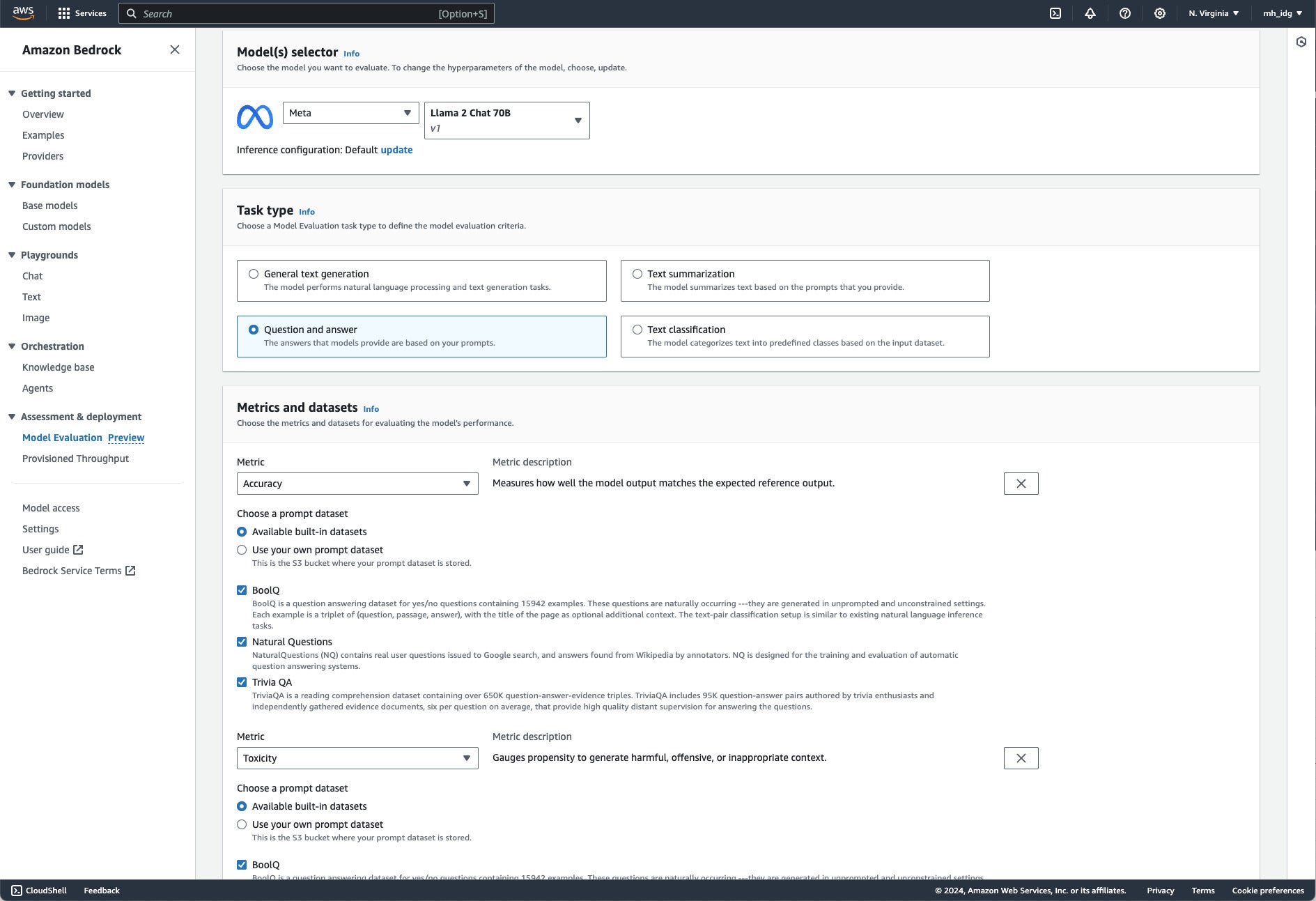
Model evaluation supports automatic evaluation of a single model, manual evaluation of up to two models using your own work team, and manual evaluation of as many models as you wish using an AWS-managed work team. Automatic evaluation uses recommended metrics, which vary depending on the type of task being evaluated, and can either use your own prompt data or built-in curated prompt data sets.
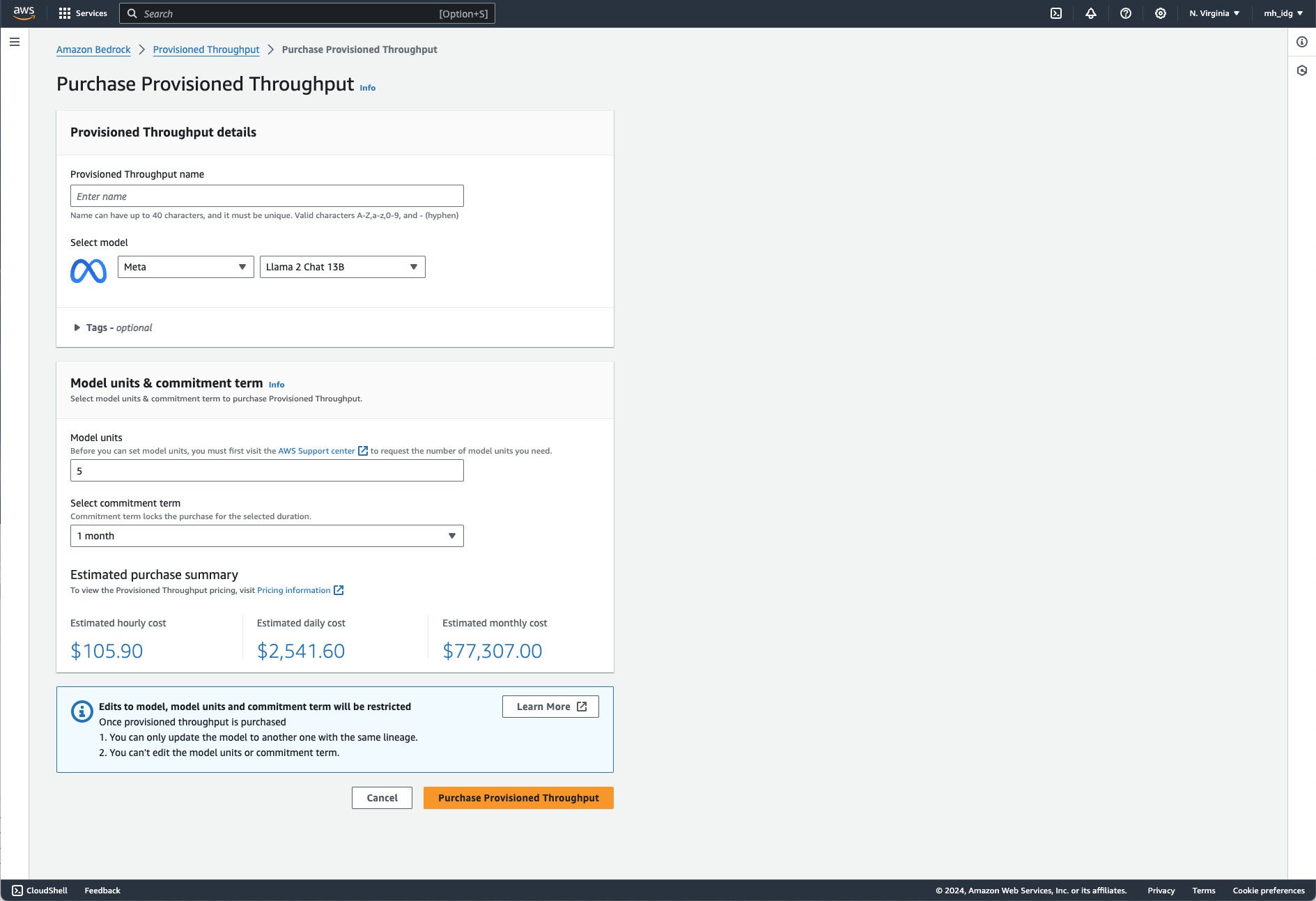
Provisioned throughput allows you to purchase dedicated capacity to deploy your models. Pricing varies depending on the model that you use and the level of commitment you choose.
Automatic model evaluation selection in Amazon Bedrock. Bedrock can also set up human model evaluations. The metrics and data sets used vary with the task type being evaluated.
Amazon Bedrock’s provisioning throughput isn’t cheap, and it isn’t available for every model. Here we see an estimated monthly cost of provisioning five model units of the Llama 2 Chat 13B model for one month. It’s $77.3K. Upping the term to six months drops the monthly cost to $47.7K. You can’t edit the provisioned model units or term once you’ve purchased the throughput.
It’s worth discussing ways of customizing models in general at this point. Below we’ll talk specifically about the customization methods implemented in Amazon Bedrock.
Prompt engineering, as shown above, is one of the simplest ways to customize a generative AI model. Typically, models accept two prompts, a user prompt and a system or instruction prompt, and generate an output. You normally change the user prompt all the time, and use the system prompt to define the general characteristics you want the model to take on. Prompt engineering is often sufficient to define the way you want a model to respond for a well-defined task, such as generating text in specific styles by presenting sample text or question-and-answer pairs. You can easily imagine creating a prompt for “Talk Like a Pirate Day.” Ahoy, matey.
Page 2
Retrieval-augmented generation helps to ground LLMs with specific sources, often sources that weren’t included in the models’ original training. As you might guess, RAG’s three steps are retrieval from a specified source (the knowledge base in Amazon Bedrock parlance), augmentation of the prompt with the context retrieved from the source, and then generation using the model and the augmented prompt.
RAG procedures often use embedding to limit the length and improve the relevance of the retrieved context. Essentially, an embedding function takes a word or phrase and maps it to a vector of floating point numbers; these are typically stored in a database that supports a vector search index. The retrieval step then uses a semantic similarity search, typically using the cosine of the angle between the query’s embedding and the stored vectors, to find “nearby” information to use in the augmented prompt. Search engines usually do the same thing to find their answers.
Agents, aka conversational retrieval agents, expand on the idea of conversational LLMs with some combination of tools, running code, embeddings, and vector stores. In other words, they are RAG plus additional steps. Agents often help to specialize LLMs to specific domains and to tailor the output of the LLM. Azure Copilots are usually agents; Google and Amazon use the term agents. LangChain and LangSmith simplify building RAG pipelines and agents.
Fine-tuning large language models is a supervised learning process that involves adjusting the model’s parameters to a specific task. It’s done by training the model on a smaller, task-specific data set that’s labeled with examples relevant to the target task. Fine-tuning often takes hours or days using many server-level GPUs and requires hundreds or thousands of tagged exemplars. It’s still much faster than extended pre-training.
Pre-training is the unsupervised learning process on huge text data sets that teaches LLMs the basics of language and creates a generic base model. Extended or continued pre-training adds unlabeled domain-specific or task-specific data sets to the base model to specialize the model, for example to add a language, add terms for a specialty such as medicine, or add the ability to generate code. Continued pre-training (using unsupervised learning) is often followed by fine-tuning (using supervised learning).
Both fine-tuning and continued pre-training tend to be expensive and lengthy processes. Even preparing the data for these can be a challenge. For fine-tuning, the challenge is getting the tagging done within budget. For continued pre-training, the challenge is to find a data set for your domain of interest that doesn’t introduce biases or toxicity of any kind.
Amazon Bedrock can create custom models by continued pre-training and/or with fine-tuning. You can manage your models and training jobs from this screen. Note the requirement for purchasing provisioned throughput to deploy your custom model.
Creating a fine-tuning job in Amazon Bedrock. Note that only certain models can currently be fine-tuned: four Amazon models, two Cohere models, and two Meta models.
You can manage your custom model training jobs as well as your custom models in Amazon Bedrock. Note the three status codes for jobs: failed, stopped, and complete. Only completed jobs will get a link from their custom model name. All jobs get links from their job names.
Digging into a training job detail in Amazon Bedrock shows you its source model, when it was started, its status, and various parameters and hyperparameters.
Once you have completed customizing your models in Amazon Bedrock you can manage them on the models tab. You can provision them, open them in the playground, delete them, and open their details.
Model details look similar to training job details in Amazon Bedrock, with a few differences, such as offering purchase and management of provisioned input.
While the setup of a continued pre-training job looks similar to the setup of a fine-tuning job, they have some major differences. Continued pre-training is an unsupervised learning job that needs a lot of untagged data and a lot of time. Fine-tuning is a supervised learning job that needs less data (but tagged!) and less time.
To accompany Amazon Bedrock, AWS has released a mostly free low-code platform for learning generative AI and building small AI apps. The introductory PartyRock blog post is by Jeff Barr, and tells you enough that you can dive in yourself; it also supplies links to PartyRock learning resources near the end of the post. If you don’t want to build an app yourself, you can still play with the apps others have built.
Amazon Bedrock is a credible competitor to Azure AI Studio. If you’re already committed to AWS rather than Microsoft Azure or Google Cloud, then Bedrock will certainly be a good choice for building and scaling generative AI applications. Bedrock offers fewer foundation models than Azure AI Studio, and furthermore lacks access to any OpenAI models, but it should do the job for most generative AI apps. Bedrock is currently a little behind Azure AI Studio when it comes to content filters, but that could easily change in the future.
Note that the cost of deploying generative AI apps tends to dwarf the cost of developing them. The cost of using Amazon Bedrock to do prompt engineering and develop RAG apps tends to be low (ignoring the people costs), and the cost of testing these in the Bedrock playgrounds is usually negligible. The cost of fine-tuning tends to be something that might give small companies pause. The cost of continued pre-training may also give medium-size companies pause. But deploy an app with a customized model at scale sufficient to serve a large audience with low lag for a long period of time, and soon you’re talking about real money.
—
Cost: Pricing is based on the model, the volume of input tokens and output tokens, and on whether you have purchased provisioned throughput for the model. For more information, see the Model providers page in the Amazon Bedrock console.
Platform: Browser-based, hosted on AWS. API access available.
Next read this:





This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →
Copyright 2015 - InnovatePC - All Rights Reserved
Site Design By Digital web avenue