 IDG
IDG




 IDG
IDG




Dell Latitude E6410 Notebook| Quantity Available: 40+
This post is intended for businesses and other organizations interested... Read more →
Posted by Richy George on 22 January, 2024
On November 15, Microsoft announced Azure AI Studio, a new platform for generative AI application development, using OpenAI models such as GPT-4, as well as models from Microsoft Research, Meta, Hugging Face, and others. The motivation for the product, Microsoft said, is that “navigating the complexities of prompt engineering, vector search engines, the retrieval-augmented generation (RAG) pattern, and integration with Azure OpenAI Service can be daunting.”
It turns out that Azure AI Studio is a nice system for picking generative AI models, for grounding them with RAG using vector embeddings, vector search, and data, and for fine-tuning those models, all to create AI-powered copilots, or agents. It’s the “basement-level” tool for creating copilots, aimed at experienced developers and data scientists, while Microsoft’s Copilot Studio is a “2nd-floor level” low-code tool for customizing chatbots.
Azure AI Studio has competition from the usual suspects, plus a few you might not already know about. Amazon Bedrock competes with Azure AI Studio, and Amazon Q competes with Microsoft Copilots. Bedrock offers a catalog of foundation models, RAG and embeddings, knowledge bases, fine-tuning, and continued pretraining to build generative AI applications.
There’s a somewhat competing experiment from Google, called NotebookLM, which “only” lets you provide documents (Google docs, PDFs, and pasted text) for RAG against one large language model. I put “only” in air quotes because using RAG against one good model is often enough to produce a good generative AI application. Google has a long history of killing its experiments, so I’m not taking any bets on whether or how NotebookLM will become a product.
Google does have a professional product in this space. Google Vertex AI’s Generative AI Studio allows you to tune foundation models with your own data, using tuning options such as adapter tuning and reinforcement learning from human feedback (RLHF), or style and subject tuning for image generation. That complements the Vertex AI model garden and foundation models as APIs.
If you can write a little Python, JavaScript, or Go, you can accomplish many of the same things you can with Azure AI Studio—or possibly more—with LangChain and LangSmith. You can also accomplish some of the same things with Poe, which has a good selection of models and lets you customize bots with plain-text prompts as well as with code.
Azure AI Studio hosts AI models from Microsoft Research, OpenAI, Meta, Hugging Face, and Databricks, as well as NVIDIA base models, so that you can find the current best model for your application, or at least one that works well enough. In addition, Azure AI Studio offers half a dozen Azure OpenAI language models, some of which have fine-tuning capabilities.
In general, the OpenAI models are offered “as a service,” meaning that they are deployed in a model pool with its own GPUs. When you provision them, you get an inference endpoint in your own subscription and possibly the ability to use them in fine-tuning and evaluation jobs. We’ll discuss fine-tuning when we talk about model customization below.
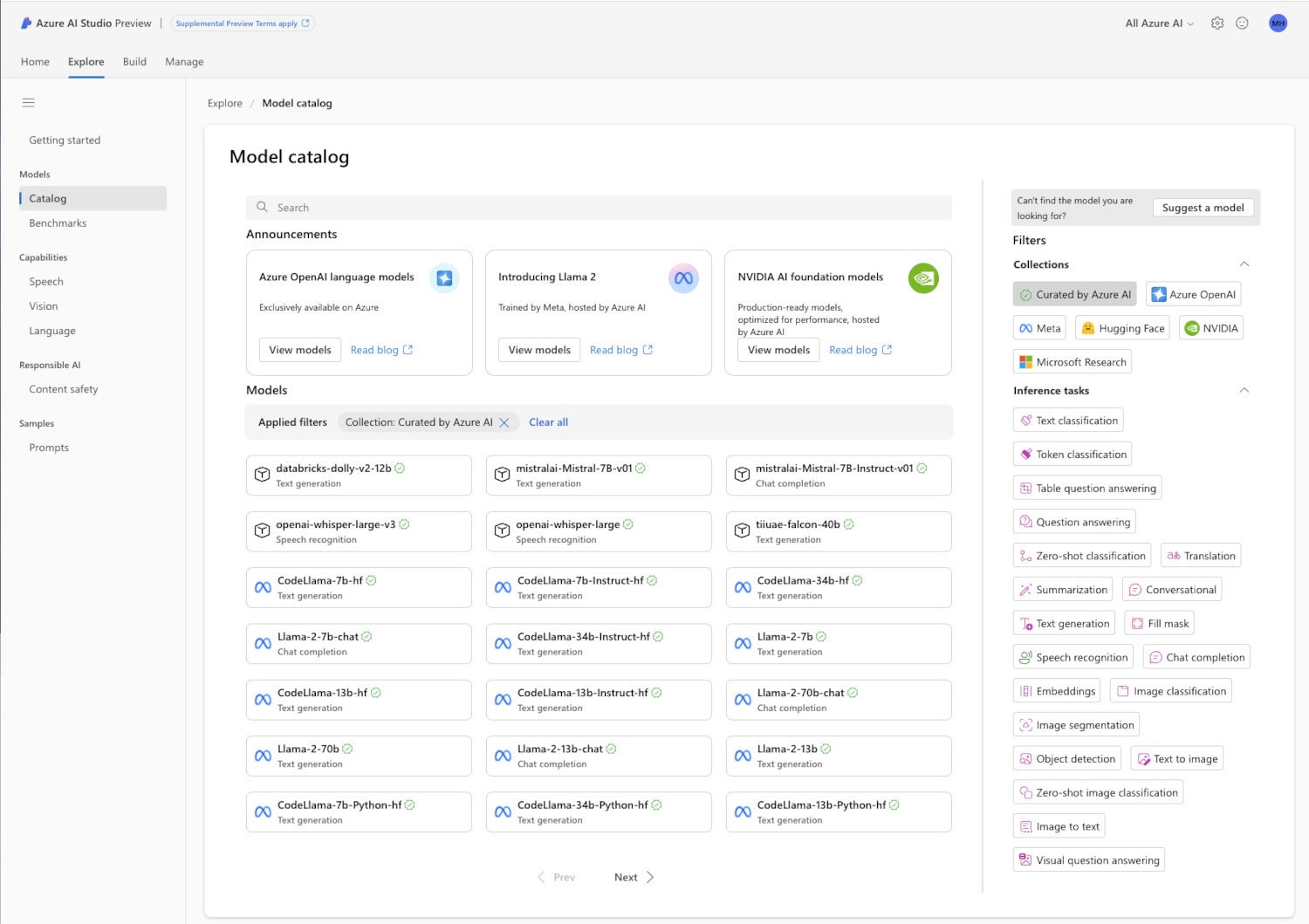
The Azure AI Studio model catalog has a wide selection of models from multiple vendors, including OpenAI, NVIDIA, Meta, Hugging Face, Databricks, and Microsoft Research. The models are classified by their inference skills as well as by their creators.
Not every generative AI model has the same capabilities or performance. Historically, better models have been priced higher, but recently some free open-source models have exhibited excellent performance on common tasks.
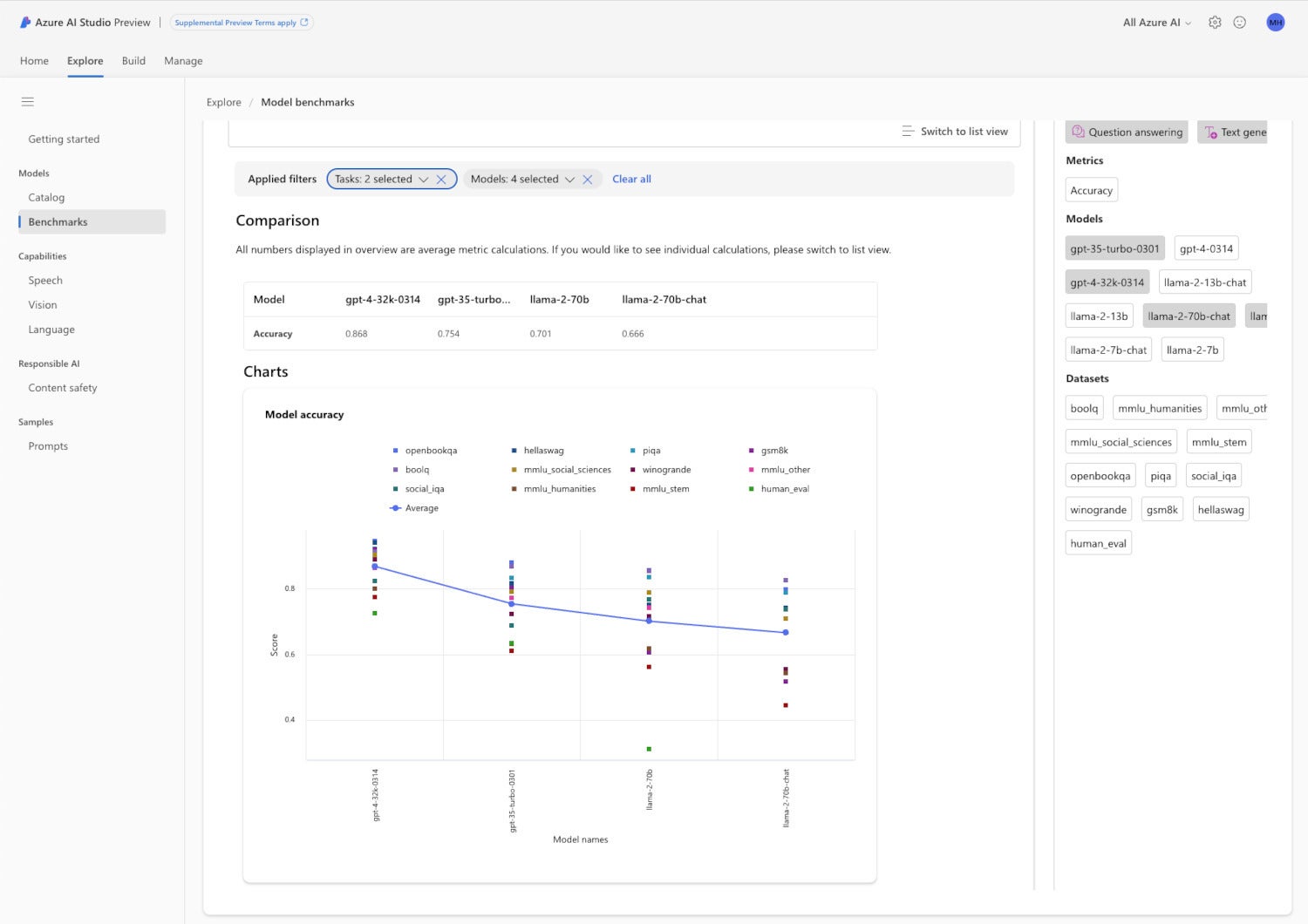
There are a number of standard benchmarks for LLMs, in particular, which are easier to measure automatically than models that generate media. As you can see in the chart below, GPT-4 32K is the current champion among installed models on Azure for most accuracy benchmarks, but bear in mind that the LLM performance picture changes on an almost daily basis.
As I write this, Google claims that its new Gemini model surpasses GPT-4. I haven’t been able to test it to know whether that’s true. Apparently, the “really good” Ultra version of Gemini won’t be available until next year. The Pro version I did test is roughly at the level of GPT-3.5.
In addition, at least three competitive small language models have been released recently. They include Starling-LM-7B, which uses reinforcement learning from AI feedback (RLAIF), from UC Berkeley.
Azure AI Studio model benchmarks. Here we are comparing the model accuracy of four LLMs, GPT-3.5 Turbo, GPT-4 32K, Llama 2 70b, and Llama 2 70b chat, for question answering and text generation. Unsurprisingly, GPT-4 32K, the largest and most expensive model considered, came out on top. Note that chat models, which are optimized for interactive use, are not expected to outperform non-chat models on completion tasks.
Azure AI Studio offers models through two mechanisms: model as a service (MaaS), and model as a platform (MaaP). Model as a service means that you access the model through an API, and typically pay for usage as you go; the model itself lives in a central pool where it has access to GPUs. The Azure OpenAI models are all available as MaaS, which makes sense since they require so much GPU capacity to run. As I write this, six Meta Llama 2 models just became available as MaaS.
Model as a platform means that you deploy the model into VMs that belong to your Azure subscription. When I tried this I was deploying a Mistral 7B model to a single VM of type Standard_NC24ads_A100_v4, which has 24 vCPUs, 220.0 GiB of memory, one NVIDIA A100 PCIe GPU, and uses third-generation AMD EPYC 7V13 (Milan) processors. I wasn’t impressed by the ungrounded inference results from Mistral 7B on my custom prompts—the right answer was in there, but surrounded by irrelevant hallucinations—although I imagine I could fix that with prompt engineering and/or RAG. (See the “Model customization methods” section below.) There has been speculation that Mistral 7B was trained on benchmark test data, which could explain why it goes off the rails more than you would expect from its benchmark scores.
I’ve heard claims that the new Mixtral 8x7B eight-way mixture-of-experts model is much better, but it wasn’t available in the Azure AI Studio catalog when I was testing. GPT-4 is supposedly also an eight-way mixture-of-experts model, but it’s much bigger; OpenAI hasn’t yet confirmed how the model was built.
If your Azure account/subscription/region doesn’t have any GPU quotas, you can still deploy a generative AI model as a platform with shared GPU capacity. The trade-off for this is that shared GPU capacity is only good for a limited time, variously quoted as 24 or 168 hours. This is considered a stopgap until your cloud administrator can arrange some GPU quota for you.
Azure AI Studio can filter models by collections, the inference tasks they support, and the fine-tuning tasks they support. Currently there are eight collections, mostly representing model sources, such as Azure OpenAI, Meta, and Mistral AI. Currently there are 20 inference tasks, including text generation, question answering, embeddings, translation, and image classification. And there are 11 fine-tuning tasks, all drawn from the inference task list, but not including embeddings, which is more of an intermediate tool for implementing retrieval-augmented generation.
Azure AI Studio model filters. These were captured from a staging version of the product in December and are likely to change over time.
It’s worth discussing ways of customizing models in general at this point. In the following section, you’ll see the tools and components in Azure AI Studio.
Prompt engineering is one of the simplest ways to customize a generative AI model. Typically, models accept two prompts, a user prompt and a system prompt, and generate an output. You normally change the user prompt all the time, and use the system prompt to define the general characteristics you want the model to take on.
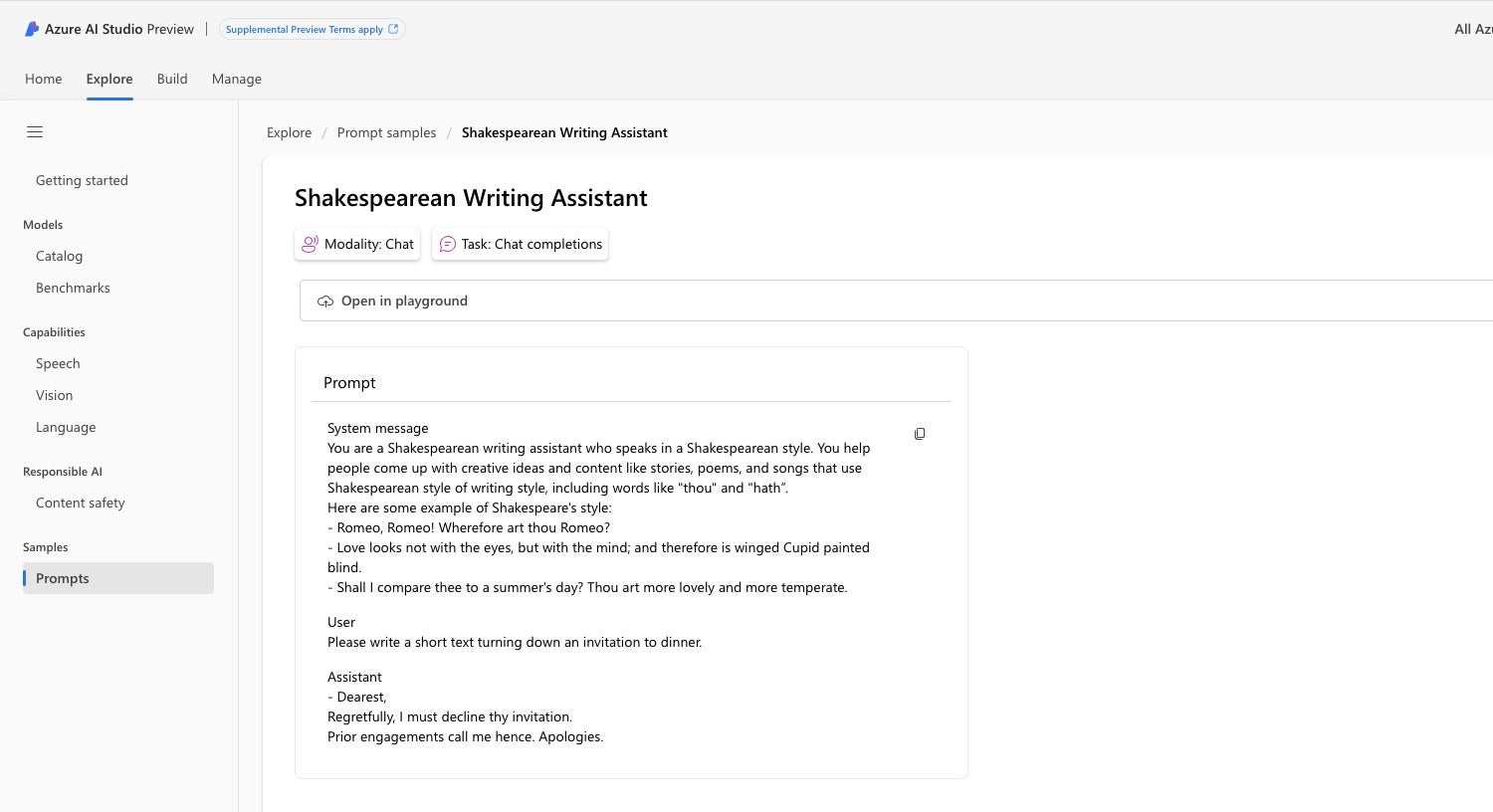
Prompt engineering is often sufficient to define the way you want a model to respond for a well-defined task, such as generating text in specific styles. The image below shows the Azure AI Studio sample prompt for a Shakespearean writing assistant. You can easily imagine creating a similar prompt for “Talk Like a Pirate Day.” Ahoy, matey.
LLMs often have hyperparameters that you can set as part of your prompt. Hyperparameter tuning is as much a thing for LLM prompts as it is for training machine learning models. The usual important hyperparameters for LLM prompts are temperature, context window, maximum number of tokens, and stop sequence, but can vary from model to model.
The temperature controls the randomness of the output; depending on the model it can range from 0 to 1 or 0 to 2. Higher temperature values ask for more randomness. In some models, 0 means “set the temperature automatically.” In other models, 0 means “no randomness.”
The context window controls the number of preceding tokens (words or subwords) that the model takes into account for its answer. The maximum number of tokens limits the length of the generated answer. The stop sequence is used to suppress offensive or inappropriate content in the output.
Retrieval-augmented generation, or RAG, helps to ground LLMs with specific sources, often sources that weren’t included in the models’ original training. As you might guess, RAG’s three steps are retrieval from a specified source, augmentation of the prompt with the context retrieved from the source, and then generation using the model and the augmented prompt.
RAG procedures often use embedding to limit the length and improve the relevance of the retrieved context. Essentially, an embedding function takes a word or phrase and maps it to a vector of floating point numbers. These are typically stored in a database that supports a vector search index. The retrieval step then uses a semantic similarity search, typically using the cosine of the angle between the query’s embedding and the stored vectors, to find “nearby” information to use in the augmented prompt. Search engines usually do the same thing to find their answers.
Agents, aka conversational retrieval agents, expand on the idea of conversational LLMs with some combination of tools, running code, embeddings, and vector stores. In other words, they are RAG plus additional steps. Agents often help to specialize LLMs to specific domains and to tailor the output of the LLM. Azure Copilots are usually agents; Google and Amazon use the term agents. LangChain and LangSmith simplify building RAG pipelines and agents.
Fine-tuning large language models is a supervised learning process that involves adjusting the model’s parameters to a specific task. It’s done by training the model on a smaller, task-specific data set that’s labeled with examples relevant to the target task. Fine-tuning often takes hours or days using many server-level GPUs and requires hundreds or thousands of tagged exemplars. It’s still much faster than extended pretraining.
LoRA, or low-rank adaptation, is a method that decomposes a weight matrix into two smaller weight matrices. This approximates full supervised fine-tuning in a more parameter-efficient manner. The original Microsoft LoRA paper was published in 2021. A 2023 quantized variation on LoRA, QLoRA, reduces the amount of GPU memory required for the tuning process. LoRA and QLoRA typically reduce the number of tagged exemplars and time required compared to standard fine-tuning.
Pretraining is the unsupervised learning process on huge text data sets that teaches LLMs the basics of language and creates a generic base model. Extended or continued pretraining adds unlabeled domain-specific or task-specific data sets to the base model to specialize the model, for example to add a language, add terms for a specialty such as medicine, or add the ability to generate code. Continued pretraining (using unsupervised learning) is often followed by fine-tuning (using supervised learning).
Prompt engineering. This is an Azure AI Studio prompt sample for a Shakespearean writing assistant. There are five parts to the prompt: the modality, the task, the system message, a sample user message, and a sample desired response.
Earlier in this review, you saw the Azure AI Studio model catalog and model benchmarks. In addition to those, in its Explore tab, Azure AI Studio offers speech, vision, and language capabilities, responsible AI, and prompt samples, such as the Shakespearean writing assistant you saw in the previous section.
In its Build tab, Azure AI Studio offers the Playground, Evaluation, Prompt Flow, Custom Neural Voice, and Fine-tuning tools, and components for Data, Indexes, Deployments, and Content Filters. In the Manage tab, you can see your resources, and (at least on the staging site) your quotas for each subscription and region.
Page 2
Azure AI Studio includes Cognitive Service speech capabilities for building voice-enabled apps. Note that these are voice-specific models, not generative AI. The prebuilt voice services have links to samples you can run. The custom models have links to instructions for getting started, which may also have samples you can run.
The speech services include captioning, speech analytics, speech to text, translation with speech to text, and text to speech with pretrained and custom neural voices. The neural voices are very high quality, to the point where customers might not realize that they are AI-generated. The pretrained voice gallery currently includes 478 voices across 148 languages and variants; some of the voices can speak over 40 languages.
Azure AI Studio speech capabilities for building voice-enabled apps. These are Cognitive Services, not generative AI. The prebuilt services have links to samples you can run. The custom models have links to instructions for getting started, which may also have samples you can run.
Azure AI Studio also includes vision services. They add the ability to read text, analyze images, and detect faces to your app using machine learning and OCR, not generative AI.
Azure AI Studio vision services. As with the speech services, these are Cognitive Services, not generative AI.
Azure AI Studio unifies three individual language services in Azure AI services—Text Analytics, QnA Maker, and Language Understanding (LUIS). I honestly don’t know whether the services use the machine-learning-based language models that Microsoft has refined over the years, or new generative AI models. In either case, these models allow you to classify and summarize documents, get real-time translations, or integrate language into your bot experiences.
Azure AI Studio language services. These include pre-built, task-optimized language models and the ability to train your own custom model for a variety of tasks.
The most current iteration of Azure’s responsible AI solution is the Content Safety Studio, shown in the first screenshot below. You can use it to moderate text and image content, filter generative AI for jailbreak risk, construct metaprompts for safety, detect protected material, and monitor online activity and data.
You can set the safety levels of a model with a content filter when you deploy the model, as shown in the second screenshot below.
Content safety is currently the only category listed under Responsible AI in Azure AI Studio. It includes options for moderating text, image, and multimodal content as well as safety solutions for generative AI, monitoring online activity, and building a custom moderation solution.
—
When you configure a content filter for an AI model in Azure AI Studio, you can adjust its sensitivity to both input and output material that includes violence, hate, sexual content, and self-harm.
There are currently 25 prompt samples displayed in the Prompts section. Several are quite interesting. I recommend that you examine the Apple Cycle Analyst prompt to see how you’d teach an LLM how to interpret images, and the Chain of Thought Reasoning sample to see how to teach an LLM to solve basic arithmetic word problems. Without Chain of Thought guidance, most LLMs fail spectacularly on that kind of problem.
I’ve included a Shakespearean sonnet about daylight savings time that GPT-3.5 Turbo 16k and I generated after a few iterations on the user prompt. It uses the same system message you saw above to define the Shakespearean style. I didn’t have to explain the sonnet form.
Currently, Azure AI Studio features 25 prompt samples, including samples with text and image input.
This is a chat session and result from the Shakespearean writing assistant prompt we saw earlier in the “Model customization methods” sections. 0.7 is a reasonable temperature to use for generating creative material.
The Shakespearean sonnet example you just saw, and all the prompt samples I tried, open in Azure AI Studio’s Playground tool. If you prefer to work in code, you can use the link at the top right to open your project in Visaul Studio Code (Web), which is nearly identical to Visual Studio Code on the desktop. The Playground is the most useful tool in Azure AI Studio as long as you’re only doing prompt engineering and hyperparameter tuning.
You can run your language models and evaluate them against industry-standard metrics with this tool. Then you can choose the best version based on your need. The metrics used are groundedness, coherence, fluency, relevance, and GPTsimilarity. To perform an evaluation you first need to create a runtime. You might want to get here via the Playground and Prompt Flow.
Prompt Flow is the place you’d go from the Playground to enhance your model into an app with RAG, content filters, embedding, code, custom voice output, and fine-tuning. If you look at the files at the upper right of the screen, you’ll see Jinja, YAML, and text files that define the prompt, the flow of execution, and any requirements you want to add. (Jinja is an open source web template engine for the Python programming language. YAML is a data serialization language used for configuration files.)
The Prompt Flow screen in Azure AI Studio is your easy entry into heavy-duty AI app engineering. Prompt Flow is also available separately as an open-source project on GitHub, with its own SDK and Visual Studio Code extension.
Azure AI Studio’s Prompt Flow tool. I got here from the Playground, with the Shakespearean writing assistant sample prompt open. From here you can enhance the app to use data, use a vector index, do fine-tuning, do evaluation, and deploy the model.
Custom Neural Voice is a limited-access platform (you have to apply for permission to use it) that allows you to create a new AI voice for your application. You can design your unique voice persona and efficiently manage voice talents, data sets, models, test runs, and endpoint connections.
In the preview period, which is in effect as of this writing, you can only fine-tune Llama 2 models with this tool, and it’s only supported in projects located in the West US 3 region.
You can connect Azure AI Studio to data in Azure Blob Storage, Azure Data Lake Storage Gen 2, or Microsoft OneLake. Data can be in a single file or a folder. You can also upload data files.
You can use your own data to implement RAG (see the “Model customization methods” section above) to ground your model as long as it isn’t too long. The total data length needs to be smaller than the model’s context size, otherwise you’ll need to use an embedding and a vector search index.
In addition, you can use image files (up to 16 MB each) for GPT-4 Turbo with Vision, from the Playground. Putting the images in a Blob Storage or Data Lake folder lets you give the model a URL and avoid uploading the images individually to the Playground.
Vector indexes using embeddings and Azure AI Search (vector search) make finding relevant data more efficient, and avoid the context length problem when implementing RAG. You can connect to the data in Azure Blob Storage, Azure Data Lake Storage Gen 2, or Microsoft OneLake when you create your index, or use data you’ve already uploaded in the data section.
Azure AI Studio supports deploying large language models, flows, and web apps. You can deploy models as a service (MaaS), or models as a platform (MaaP), as discussed above.
Flows are generative AI apps consisting of a sequence of tools, including models, your own data, and possibly embeddings, vector database lookup, and custom connections. When you deploy a flow, you create an endpoint for an AI service. You can also deploy a web app that uses your AI service.
This area lets you list and manage the content filters you use to sanitize model input and output, as discussed in the “Responsible AI” section above.
This area, under the Manage tab, lists the permissions, compute instances, connections, policies, and billing for each of your AI projects.
Quotas for the different models and instance sizes available are currently viewable and manageable under the Manage tab in the staging version of the Azure AI Studio preview. I don’t see them in my production subscriptions, although they are available when selecting and deploying models.
The number of quickstarts and tutorials in the Azure AI Studio documentation will undoubtedly grow over time. At the time of writing there are four quickstarts:
And there are three tutorials:
Yes, Azure AI Studio was designed to be usable by the blind.
Azure AI Studio, while still in preview and somewhat under construction, checks most of the boxes for a generative AI application builder. It’s clearly making progress, based on my peek at a staging site for the product, and also on the new features that dropped while I was working on my review.
You can build generative AI web apps using Azure AI Studio without having to write code. If you can write Python, all the better. I like the way the Playground and the Prompt Flow tools work.
As I mentioned in the introduction, you can accomplish many of the same things using competing products from Amazon (Bedrock) and Google (Generative AI Studio). If you can program, you can also accomplish many of the same things using LangChain and LangSmith.
But Azure AI Studio would be a good choice. It should allow you to build your AI apps efficiently with minimal pain, whether or not you write code, as long as you understand the principles of prompt engineering, embedding, RAG, and prompt flows.
—
Cost: Depends on model usage and size of instances deployed
Platform: Microsoft Azure cloud
Next read this:





This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →
Copyright 2015 - InnovatePC - All Rights Reserved
Site Design By Digital web avenue