

Dell Latitude E6410 Notebook| Quantity Available: 40+
This post is intended for businesses and other organizations interested... Read more →
Posted by Richy George on 29 January, 2024
Generative AI has had an immediate and enormous impact on software development. Software developers have embraced generative AI tools that help with coding, and they are working feverishly to build generative AI applications themselves. Databases can help—especially fast, scalable, multi-model databases like SingleStore.
At the inaugural SingleStore Now conference, SingleStore announced several AI-focused innovations with developers in mind. These include SingleStore hybrid search, compute service, Notebooks, and the Elegance SDK. Given the impact that AI and LLMs are having on developers, it makes sense to dive into the ways that these innovations make developing AI applications easier.
If you’ve been working with AI or LLMs in any way, you know that vector databases have become much more popular because of their ability to help you search for the nearest n representations of the data you’re working with. You can then use those search results to provide additional context to your LLM to make the responses more accurate. SingleStoreDB has supported vector functions and vector search for a number of years now, but generative AI applications require you to search among millions or billions of vector embeddings in milliseconds—which gets difficult using k-Nearest Neighbor (kNN) across huge data sets.
Hybrid search adds Approximate Nearest Neighbor (ANN) search as an additional option to the already existing k-Nearest Neighbor (kNN) search. The primary difference between ANN and kNN is in the name: approximate vs. nearest. Initial testing shows ANN to be orders of magnitude faster for vector search, taking your AI use cases from fast to real time. Real-time vector search ensures that your applications respond instantly to queries, even when that data has just been written to the database.
Hybrid search uses a number of techniques to make your search functions more performant, namely inverted file (IVF) with product quantization (PQ). With IVF with PQ, you can lower the build times of your index while improving the compression ratios and memory footprint of your vector searches. Beyond IVF with PQ, hybrid search adds the hierarchical navigable small world (HNSW) approach to allow for high-performance vector index searches using high dimensionality.
With hybrid search, you can combine all of these new indexing approaches, along with full-text search, to combine hybrid semantic (vector similarity) and lexical/keyword search in one query.
Below you can see an example of using hybrid search. To view the code in its broader context, check out the full notebook on SingleStore Spaces.
hyb_query = 'Articles about Aussie captures'
hyb_embedding = model.encode(hyb_query)
# Create the SQL statement.
hyb_statement = sa.text('''
SELECT
title,
description,
genre,
DOT_PRODUCT(embedding, :embedding) AS semantic_score,
MATCH(title, description) AGAINST (:query) AS keyword_score,
(semantic_score + keyword_score) / 2 AS combined_score
FROM news.news_articles
ORDER BY combined_score DESC
LIMIT 10
''')
# Execute the SQL statement.
hyb_results = pd.DataFrame(conn.execute(hyb_statement, dict(embedding=hyb_embedding, query=hyb_query)))
hyb_results
The above query finds the average scores of semantic and keyword searches, combines them, and sorts the news articles by this calculated score. By removing the extra complexity of performing lexical/keyword and semantic searches separately, hybrid search simplifies the code for your application.
SingleStore’s implementation of these new indexing strategies also allows us to quickly incorporate new strategies as they become available, ensuring that your application will always perform its best when backed by SingleStoreDB.
When you’re working with extremely large data sets, one of the best things you can do to keep your performance and cost in check is to perform the compute work as close to the data as possible. SingleStore compute service enables you to deploy compute resources (CPUs and GPUs) for AI, machine learning, or ETL (extract, transform, load) workloads alongside your data. With compute service, SingleStore customers can use these new compute resources to run their own machine learning models or other software in a way that allows them to have the full context of their enterprise data, without worrying about egress performance and cost.
Coupling compute service with job service (private preview), you can schedule SQL and Python jobs from within SingleStore Notebooks to process their data, train or fine-tune a machine learning model, or do other complex data transformation work. If your company often updates the fine-tuning of your AI model or LLM, you can now do so in a scheduled manner—using optimized compute platforms that live next to your data.
Many engineers and data scientists are comfortable working with Jupyter Notebooks, hosted, interactive, shareable documents in which you can write and execute code blocks, interspersed with documentation, and visualize data. What is often missing in a Jupyter environment are native connections to your databases and SQL functionality.
With the announcement of general availability of SingleStore Notebooks, SingleStore makes it easy for you to explore, visualize, and collaborate with your data and peers in real time. Getting started with SingleStore Notebooks is extremely simple:
In the navigation pane on the left, you’ll see Notebooks. Click the plus sign next to Notebooks and fill out the details. If you intend on sharing this notebook with your colleagues, ensure that you choose Shared under Location. Set the Default Cell Language to the language you will primarily use in the notebook, then click create.
Note: You can also choose one of the templates or select from the gallery, if you’d like to see how a Notebook can look.
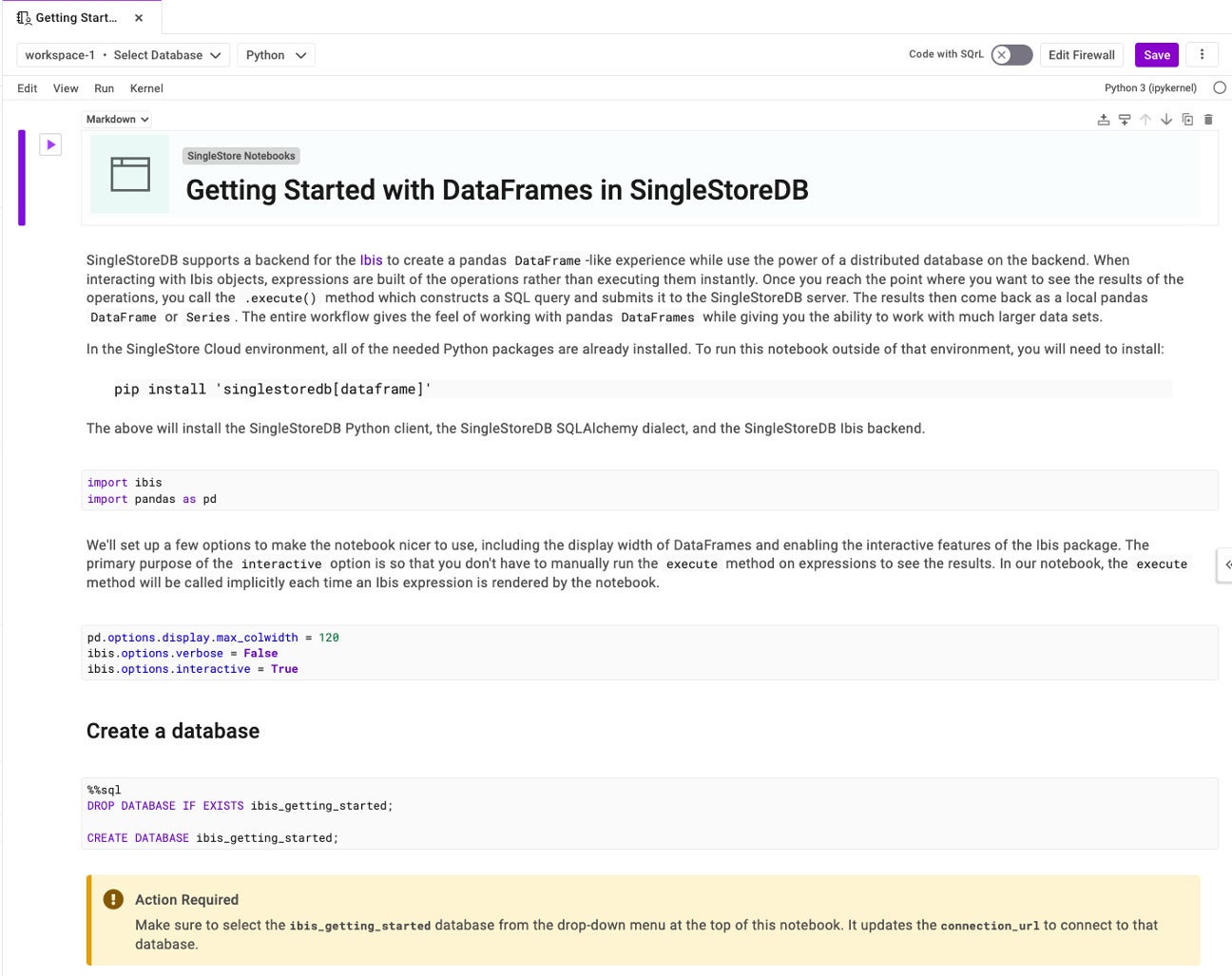
For a handy example, I have imported a notebook from the gallery called “Getting Started with DataFrames in SingleStoreDB.” This notebook walks you through the process of using pandas DataFrames to better take advantage of the distributed nature of SingleStoreDB.
When you select the Workspace and Database at the top of the notebook, it will update the connection_url variable so you can quickly and easily connect to and work with your data.
In this notebook, we use a simple command, conn = ibis.singlestoredb.connect(), to create a connection to the database. No more worrying about putting together the connection string, removing one more thing from the complex process of prototyping something using your data.
In Notebooks, you simply select the Play button next to each cell to run that code block. In the screenshot above, we’re importing packages ibis and pandas.
SingleStore Notebooks is an extremely powerful platform that will allow you to prototype applications, perform data analysis, and quickly repeat tasks that you may need to perform using your data living inside of SingleStoreDB. This rapid prototyping is an extremely effective way to see how you could implement AI, LLMs, or other big data methods into your business.
Be sure to check out SingleStore Spaces to see a large sample of Notebooks that showcase anything from image matching to building LLM apps that use retrieval-augmented generation (RAG) on your own data.
SingleStore Elegance is an NPM package designed to help React developers rapidly build applications on top of SingleStoreDB using SingleStore Kai or MySQL connections to the database. With the release of Elegance, there has never been a better time to develop an AI application that is backed by SingleStoreDB.
Elegance offers a powerful SDK covering a number of features:
Getting started with a demo application is as simple as following just a few simple steps:
git clone https://github.com/singlestore-labs/elegance-sdk-app-books-chat.git
npm i
sh ./scripts/start.sh
If you’d prefer to start from scratch and build something on your own, you can get started with a simple npm install @singlestore/elegance-sdk and follow the steps from our package page on npmjs.com.
The business landscape is changing rapidly with the mainstreaming of AI and LLMs, causing nearly everyone to evaluate whether or not they should implement some form of AI. Many companies are already putting together POCs. These releases show that SingleStore is 100% focused on building a real-time analytics and AI database that gives you the tooling you need to build your applications quickly and efficiently—getting your AI and LLM projects to market faster.
That wraps up the AI innovations that emerged from SingleStore Now. In case you were unable to make the event in person, you can watch all of the sessions on demand.
Wes Kennedy is a principal evangelist at SingleStore, where he creates content, demo environments, and videos and dives into ways that we can meet customers where they are. He has a diverse background in tech covering everything from being a virtualization engineer, sales engineer, to technical marketing.
—
Generative AI Insights provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss the challenges and opportunities of generative artificial intelligence. The selection is wide-ranging, from technology deep dives to case studies to expert opinion, but also subjective, based on our judgment of which topics and treatments will best serve InfoWorld’s technically sophisticated audience. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Contact doug_dineley@foundryco.com.
Next read this:





This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →
Copyright 2015 - InnovatePC - All Rights Reserved
Site Design By Digital web avenue