
Dell Latitude E6410 Notebook| Quantity Available: 40+
This post is intended for businesses and other organizations interested... Read more →
Posted by Richy George on 8 March, 2024

Entity Framework Core is an object-relational mapper, or ORM, that isolates your application’s object model from the data model. That allows you to write code that performs CRUD operations without worrying about how the data is stored. In other words, you work with the data using familiar .NET objects.
In Entity Framework Core, the DbContext connects the domain classes to the database by acting as a bridge between them. You can take advantage of the DbContext to query data in your entities or save your entities to the underlying database.
I’ve discussed the basics of DbContext in a previous article. In this article we’ll dive into DbContext in a little more detail, discuss the DbContext lifetime, and offer some best practices for using DbContext in Entity Framework Core. EF Core allows you to instantiate a DbContext in several ways. We’ll examine some of the options.
To use the code examples provided in this article, you should have Visual Studio 2022 installed in your system. If you don’t already have a copy, you can download Visual Studio 2022 here.
To create an ASP.NET Core 8 Web API project in Visual Studio 2022, follow the steps outlined below.
We’ll use this ASP.NET Core Web API project to work with DbContext in the sections below.
When working with Entity Framework Core, the DbContext represents a connection session with the database. It works as a unit of work, enabling developers to monitor and control changes made to entities before saving them to the database. We use the DbContext to retrieve data for our entities or persist our entities in the database.
The DbContext class in EF Core adheres to the Unit of Work and Repository patterns. It provides a way to encapsulate database logic within the application, making it easier to work with the database and maintain code reusability and separation of concerns.
The DbContext in EF Core has a number of responsibilities:
The DbContext class in Entity Framework Core plays a crucial role in facilitating the connection between the application and the database, providing support for data access, change tracking, and transaction management. The lifetime of a DbContext instance starts when it is instantiated and ends when it is disposed.
Here is the sequence of events in a typical unit of work using EF Core:
A DbContext instance should be disposed when it is no longer needed to free up any unmanaged resources and prevent memory leaks. However, it is not a recommended practice to dispose off DbContext instances explicitly or to use DbContext within a using statement.
Here’s why you should not dispose of your DbContext instances:
Instead of using using blocks to dispose of the DbContext instances in your application, consider taking advantage of dependency injection to manage their lifetime. Using dependency injection will ensure that the DbContext is created and disposed of appropriately, depending on the life cycle of the application or the scope of the operation.
There is no specific rule for creating a DbContext instance. The requirements of your application should determine which approach you take. Each of the approaches illustrated below has its specific use cases—none of them is better than the others.
You can extend the DbContext class in EF Core to create your own DbContext class as shown below.
public class IDGDbContext : DbContext
{
public ApplicationDbContext(DbContextOptions<ApplicationDbContext> options)
: base(options)
{
}
}
Similarly, you could instantiate a DbContextOptionsBuilder class and then use this instance to create an instance of DbContextOptions. This DbContextOptions instance could then be passed to the DbContext constructor. This approach helps you explicitly create a DbContext instance.
Alternatively, you can create DbContext instances via dependency injection (DI) by configuring your DbContext instance using the AddDbContext method as shown below.
services.AddDbContext<IDGDbContext>(
options => options.UseSqlServer("name=ConnectionStrings:DefaultConnection"));
You can then take advantage of constructor injection in your controller to retrieve an instance of DbContext as shown below.
public class IDGController
{
private readonly IDGDbContext _dbContext;
public IDGController(IDGDbContext dbContext)
{
_dbContext = dbContext;
}
}
Typically, an HTTP request-response cycle represents a unit of work in web applications. With DI, we are able to create a DbContext instance for each request and dispose of it when that request terminates.
I prefer using a DI container to instantiate and configure DbContext because the DI container manages the DbContext instances and lifetimes for you, relieving you of the pain of managing these instances explicitly.
A third option is to create a DbContext instance by overriding the OnConfiguring method in your custom DbContext class. You can then take advantage of the DbContext constructor to pass configuration information, such as a connection string.
The code snippet below shows how you can initialize DbContext in the OnConfiguring method of your custom DbContext class.
public class IDGDbContext : DbContext
{
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder.UseSqlServer("Specify your database connection string here.");
}
}
You can also create an instance of DbContext using a factory. A factory comes in handy when your application needs to perform multiple units of work within a particular scope.
In this case, you can use the AddDbContextFactory method to register a factory and create your DbContext objects as shown in the code snippet given below.
services.AddDbContextFactory<IDGDbContext>(
options =>
options.UseSqlServer("Specify your database connection string here."));
You can then use constructor injection in your controller to construct DbContext instances as shown below.
private readonly IDbContextFactory<IDGDbContext> _dbContextFactory;
public IDGController(IDbContextFactory<IDGDbContext> dbContextFactory)
{
_dbContextFactory = dbContextFactory;
}
You can turn on sensitive data logging to include application data when exceptions are logged in your application. The following code snippet shows how this can be done.
optionsBuilder
.EnableSensitiveDataLogging()
.UseSqlServer("Specify your database connection string here.");
Finally, note that multiple parallel operations cannot be executed simultaneously on the same DbContext instance. This refers to both the parallel execution of async queries and any explicit use of multiple threads of the instance simultaneously. Therefore, it is recommended that parallel operations be performed using separate instances of the DbContext. Additionally, you should never share DbContext instances between threads because it is not thread-safe.
Next read this:
Posted by Richy George on 4 March, 2024

SQL, the Structured Query Language, remains one of the most widely used programming languages, coming in fourth in Stack Overflow’s research for 2023. Just over half (51.52%) of professional developers use SQL in their work, but only around a third (35.29%) of those learning to code use SQL.
For a language that has remained in use for decades, SQL has a mixed reputation among developers. Why does SQL remain in use when so many other languages have come and gone? And why does SQL have a bright future still?
One reason why SQL remains in use is because it is ubiquitous. Knowing SQL is a base-level skill for many developers, leading to a large pool of people with the skills available. In turn, this encourages more people to learn SQL, as they can see the demand for people with those skills and deliver career opportunities they can take advantage of.
Alongside this ubiquity, SQL is stable. It is an effective standard that developers can rely on and it won’t change from version to version. This makes SQL suitable for long-term support planning, and the teams involved can plan ahead around their data infrastructure. This also makes it simpler to transition projects between different developers as staff members change roles.
Following on from this, SQL makes it easier to meet compatibility requirements around data within applications. Using SQL as your approach to interrogating data in one data component makes it easier to transfer over to using another option if your needs change. For example, if you decide to switch from one database to another, you would not need to edit how your application logic works when using SQL terms, as these are the same everywhere.
Because SQL acts like a standard, one benefit is that it makes it easier to make your data portable. Rather than being tied to a specific database with its own language and way of storing data, SQL ensures that your data is yours and you can do what you want with it. Effectively, you no longer have to think specifically about your databases and what they can deliver. Instead, you can look at the tools that exist within the language as the point of control over your infrastructure planning process.
As an example, consider your choices around running a database like MySQL, and then wanting to change to another option like PostgreSQL. These databases would be different in how they operate and manage data over time. However, from a functional point of view, using SQL to interrogate that data would give you the same results.
Alongside the popularity of SQL as a language, it is also worth looking at what SQL delivers from a technology standpoint. On this front, the biggest benefit is that it is logical in its design. This means that, when you understand how it works, it can be used in elegant and clever ways.
As part of this, we do have to look at the link between SQL and relational databases. For many developers, SQL is tied very tightly to the relational database model, with all the strengths and failings that this might have. However, SQL as a language is separate from relational databases, and it is important not to conflate the two together.
Nowadays many non-relational databases have embraced a table-like model and SQL language. It’s been a long time since SQL and the relational model were synonymous, and with the rise of non-relational databases the boundaries have become more fluid. For example, some key-value stores and some document store databases have adopted a table-like structure for organizing their data, and some provide a subset of SQL or a SQL-like query language for enhanced accessibility and to make it easier for developers to work with their products.
Over the years, the relational model has proved to be an extremely effective one for database designs. The reason for this is that the model is based on solid mathematical theory that is very precise. These strong theoretical foundations are why relational databases have remained so popular in computer science and software engineering generally. SQL has made it easier to access that logical and computing power over time, and to keep those systems running in a uniform way that everyone can understand.
While I have mentioned that SQL is a de facto standard, like any other standard it has evolved over time and can be extended when planned well. The best example of this evolution is the change in the standard that allows database vendors to support different JSON formats in 2016.
For many years, developers who wanted to work with JSON had the option to use document-oriented databases like MongoDB for their data store, while other databases would be secondary options due to performance and ease of use. Today, that is not the case, as many relational databases like PostgreSQL have implemented JSON support that can work as fast or even faster than document-oriented databases for certain workloads. This support makes it easier for developers to design systems and infrastructure that directly supports their application goals, rather than being tied to a specific approach.
Another benefit of SQL is that it is a declarative language. Declarative programming works by describing what you want the program to do, rather than specifying the steps that you want the program to take to do it. For developers and databases, this makes creating queries easier, because you can concentrate on the result you want to achieve rather than putting together the whole calculation. In effect, SQL lets you describe the outcome, and leaves the complexity of executing the calculation to the database.
Like any powerful language, SQL has its critics. For example, one common complaint is that SQL optimizers are not very effective at improving performance. While you might want to improve your results and the speed of response, these tools are only as powerful as the amount of work that you put in at the start. We sometimes face a similar problem with language compilers. Although compilers usually succeed at turning the developer’s code into a smaller and faster binary, they have been known to fail badly on occasion, with the opposite result.
As a developer, you may need to assist the compiler or optimizer to achieve the right results. Sometimes this knowledge can be obscure! Like Spider-Man’s Uncle Ben said, great power comes with great responsibility. You should expect to optimize your SQL approach yourself as much as possible, rather than solely relying on tools to deliver improvements.
Another common criticism of SQL is due to its strong link to relational databases. How can something so deeply rooted in traditional database design be right for the modern world? Of course, the combination of SQL and relational databases continues to serve hundreds of use cases today, delivering scalability and performance that can meet application needs. The challenge is to design your approach based on understanding what SQL is good at delivering.
As the demand for software, the pace of software development, and the number of developers have increased, the challenge for SQL is that fewer developers have a deep understanding of how SQL operates from a theoretical perspective. While movements like devops and site reliability engineering concentrate on meeting the demands that businesses have around IT services, the roles involved tend to cover multiple parts of the IT stack rather than specific functions.
Although these roles theoretically focus on the total system, there is not enough focus on how to align the business logic, or what the customer wants to achieve, with the intricacies of the infrastructure. Why is this so important? Because a database architecture must not only meet functional requirements but also align with performance, scalability, and security objectives. Without both, you lack a solid foundation for successful software development.
When applications start to scale massively or when performance problems appear, knowing how SQL works can prove to be extremely useful. Understanding query design, such as how to cherry-pick data from a larger table rather than parsing data from the same table multiple times, can have a huge impact on performance. These data management skills effectively depend on understanding database theory. This takes time to understand and deploy in practice, but it is essential to deliver better results.
Learning any language can be difficult and time-consuming. Many of us don’t have the time to dig into the principles and then apply that knowledge across languages and applications. However, this does lead to problems such as poor performance, which then become harder to diagnose and treat effectively. Deploying the wrong kind of database can also affect the success of your project. You can be very happy with one database that is great for certain use cases, but it might not be right for everything. SQL makes it easier to abstract those requirements away from the underlying infrastructure. Even if you make a mistake with your database choice, SQL makes it easier to move to a better option.
SQL remains popular with many users, and it will remain popular because it solves some of the biggest challenges that exist around how to work with data. It may have a scary reputation for some, but that does not take away from the huge amount of information technology that relies on SQL every day to provide us with value. Long may we SELECT SQL and CREATE value with it.
Charly Batista is PostgreSQL technical lead at Percona.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
Next read this:
Posted by Richy George on 1 March, 2024

NoSQL document-oriented database provider Couchbase on Thursday said that it was working to add support for vector capabilities to its database offerings, including its Capella managed database-as-a-service (DBaaS).
The vector capabilities will include similarity search and retrieval-augmented generation (RAG), the company said, adding that the addition of these capabilities will also enhance the performance of the database as all search patterns can be supported within a single index to lower response latency.
Database vendors have been adding vector search capabilities to help enterprises build generative AI-based applications. Earlier in the day, Google Cloud said that it was adding vector support to all its database offerings, including Firestore, Bigtable, CloudSQL for MySQL, CloudSQL for PostgreSQL, and Spanner.
Last year, database vendors including MongoDB, DataStax, and Kinetica added vector search and other generative AI capabilities to their offerings.
Analysts believe that vector support will become table stakes for all databases by the end of 2026.
AWS and Microsoft too, according to Constellation Research’s principal analyst Doug Henschen, have added vector embedding and vector search capabilities to multiple database services.
“Oracle has signalled that they’re working on adding vector support for their database. It’s pretty clear that it’s not hard to add these capabilities and they will eventually be pervasively available,” Henschen added.
In addition to adding vector support to Couchbase Server and Capella, Couchbase is integrating LangChain and LlamaIndex—frameworks for developing generative AI-based applications—to boost developer productivity.
The new capabilities are expected to be available in Couchbase Server and Capella before May, the company said, adding that its mobile and edge database offerings will get the same capabilities in beta within the same time frame.
Next read this:
Posted by Richy George on 29 February, 2024

Google is integrating its Gemini 1.0 Pro large language model with its AI and machine learning platform, Vertex AI, to help enterprises unlock new capabilities of large language models (LLMs), including analysis of text, image and video.
The Gemini API, which has been made generally available, can also be used in Google’s data warehouse, BigQuery, to develop generative AI-based analytical applications.
“The Gemini 1.0 Pro model is designed for higher input-output scale and better result quality across a wide range of tasks like text summarization and sentiment analysis. You can now access it using simple SQL statements or BigQuery’s embedded DataFrame API from right inside the BigQuery console,” Gerrit Kazmaier, general manager of data analytics at Google Cloud, said in a statement.
The company is also expected to integrate the vision version of the Gemini Pro model in the coming months.
In addition, Google is extending Vertex AI’s document processing and speech-to-text APIs to BigQuery to help enterprises analyze unstructured data, such as documents and audio.
Earlier this month, the company announced the preview of BigQuery vector search, which when integrated with Vertex AI can enable vector similarity search on data inside BigQuery along with other features such as retrieval augmented generation (RAG), text clustering and summarization.
Hyoun Park, principal analyst at Amalgam Insights, sees RAG support as table stakes for data warehouse vendors these days.
“Retrieval augmented generation is a capability every data warehouse will need to support, as it refers to accessing data from a third party source when someone asks a question,” Park said. “For instance, if someone asks an HR question, the RAG would also ask the employee’s HR system for relevant and current data to contextualize the question. The relevant capability here is in accessing a real-time update of a specific table or data source when someone asks a question to an LLM.”
Other companies are moving in a similar direction. Steven Dickens, vice president and practice lead at The Futurum Group, said that warehouse stalwarts such as Teradata and Cloudera are also adding vector capabilities alongside players such as Oracle and Elastic.
Next read this:
Posted by Richy George on 29 February, 2024

Google Cloud on Thursday said it is adding vector support and integrating LangChain with all of its database offerings in an effort to outdo rival cloud service providers, such as Amazon Web Services (AWS), Microsoft, and Oracle.
Cloud service providers have been locked in a race to add generative AI and AI-related capabilities to their database offerings to have the first mover advantage in order to garner a bigger pie of the growing AI and generative AI market.
The new updates to database offerings include the addition of vector support for relational, key value, document, and in-memory databases such as CloudSQL, Spanner, Firestore, Bigtable, and Memorystore for Redis.
The vector capabilities added to the databases feature search capabilities including the approximate nearest neighbor search (ANN) and exact nearest neighbor search (KNN).
While ANN is used to optimize search, in other words, reduce latency, for large datasets, KNN is used to return more specific or precise search results on smaller datasets, said David Menninger, executive director at ISG’s Ventana Research.
“Support for ANN and KNN reflects that there isn’t a one-size-fits-all approach to vector search and that different use cases require different indexing algorithms to provide the required level of accuracy and performance,” Menninger explained, adding that this highlights that it is incumbent for developers to understand the nature of their data and application, and experiment with various databases to identify the capabilities that best fit the requirements of an individual project.
The other advantage from Google’s standpoint, according to Forrester’s principal analyst Noel Yuhanna, is that most database vendors don’t offer both ANN and KNN.
“Some vendors support KNN, while others support the ANN approach. ANN is more popular since it is scalable and performs well for large datasets and high-dimensional vectors,” Yuhanna said.
All the vector capabilities added to the database offerings are currently in preview. In July last year, Google launched support for the popular pgvector extension in AlloyDB and Cloud SQL to support building generative AI applications.
The addition of vector capabilities across multiple database offerings since July last year at regular intervals, seemingly, makes Google Cloud “more aggressive” than rival hyperscalers, according to Menninger.
However, he did point out that almost all database vendors are adding support for vector and vector search capabilities.
Microsoft, AWS, and Oracle, according to Yuhanna, have some level of vector support capabilities in the works in their respective database offerings.
The announcements by Google Cloud might just give it an edge over its rivals as it seems to be a bit further ahead in the journey than others in terms of making these capabilities generally available to enterprises, Yuhanna said.
Both analysts also pointed out that adding support for vector capabilities will soon become table stakes for data platform vendors to support the development of generative AI applications by complementing large language models (LLMs) with approved enterprise data to improve accuracy and trust.
ISG, according to Menninger, believes that almost all enterprises developing applications based on generative AI will explore the use of vector search and retrieval-augmented generation to complement foundation models with proprietary data and content by the end of 2026.
The addition of vector capabilities by hyperscalers and other database vendors to their offerings has resulted in a growing rivalry between vector databases and traditional databases, according to analysts.
While traditional databases have been adding vector capabilities to make their case to enterprises, vector databases have been capabilities to make their products more easily consumable by non-experts, they added.
However, ISG’s Menninger believes that more than 50% of enterprises will use traditional database offerings with vector support by 2026, given their reliance on these traditional databases.
Specialized vector databases will still continue to exist, though only for more complex and sophisticated use cases, Menninger said. Pinecone, Chroma, Weaviate, Milvus, and Qdrant are examples of specialized databases.
Explaining further, Menninger said that whether vector search is best performed using a specialist vector database or a general-purpose database will depend on a variety of factors, including the relative reliance of an enterprise on an existing database, developer skills, the size of the dataset, and specific application requirements.
Google Cloud is adding LangChain integrations for all of its databases. “We will support three LangChain Integrations that include vector stores, document loaders, and chat messages memory,” said Andi Gutmans, vice president of engineering for Google Cloud’s databases division.
LangChain is a framework for developing applications powered by LLMs and the integration into databases will allow developers built-in Retrieval Augmented Generation (RAG) workflows across their preferred data source, Gutmans added.
While the LangChain vector stores integration is available for AlloyDB, Cloud SQL for PostgreSQL, Cloud SQL for MySQL, Memorystore for Redis, and Spanner, the document loaders and chat messages memory integration is available for all databases, including Firestore, Bigtable, and SQL Server.
Analysts see the addition of LangChain integrations as an “assertive” move from Google.
“LangChain is currently the most popular framework for connecting LLMs to private sources of enterprise data, providing vendor-neutral integration with enterprise databases, as well as commercial machine learning development and deployment environments, such as SageMaker Studio and Vertex AI Studio,” Menninger explained.
Google has made its AlloyDB AI offering generally available. It can be used via AlloyDB and AlloyDB Omni.
AlloyDB AI, which was moved into preview last year in August, is a suite of integrated capabilities that allow developers to build generative AI-based applications using real-time data.
It builds on the basic vector support available with standard PostgreSQL and can introduce a simple PostgreSQL function to generate embeddings on data.
AlloyDB AI is an integral part of AlloyDB and AlloyDB Omni, and is available at no additional charge, the company said.
Next read this:
Posted by Richy George on 21 February, 2024

A non-binding proposal to acquire MariaDB, the provider of the relational database management system (RDBMS) of the same name—a fork of the open-source MySQL database, has sparked speculations about the company’s future and what the acquisition would mean for its enterprise customers.
The proposal was for MariaDB PLC, the firm that provides database services and SaaS offerings built on the core open-source database that is managed by the MariaDB Foundation.
Earlier this month, MariaDB PLC received a proposal of acquisition, to the tune of $37 million, from California-headquartered investment firm K1 Investment Management.
The proposal, which is non-binding and may not result in an actual offer for acquisition, puts a value of $0.55 for each share of MariaDB—a 189% premium over the database firm’s closing share price on February 5.
MariaDB PLC has been on a rocky ride for the past year, including laying off staffers, changing leadership, spinning off parts of its business, and filing cautionary statements with the US Securities and Exchange Commission (SEC).
The company’s path to financial difficulty began in December 2022 when it decided to go public via the special purpose acquisition company (SPAC) route with Angel Pond Holdings.
After going public, the company saw its market capitalization plummet from $445 million to just over $10 million by the end of 2023. The sharp drop in value can be attributed to the company’s poor quarterly performance and history of losses since the last quarter of 2022, according to statements filed with the SEC.
While the first quarter of 2023 saw the company lay off staffers, the second quarter saw it file cautionary statements about its financial health via a prospectus. The company said at the time that it was looking at attracting financial investments to keep the lights on.
This was followed by the New York Stock Exchange (NYSE) issuing a warning to the company in September. The stock exchange had warned MariaDB that it was failing to meet listing norms that make it necessary for listed firms to ensure that their market capitalization doesn’t drop below $50 million for a trading period of 30 days.
October brought in more woes for the database-as-a-service provider with the company being forced to lay off 28% of its workforce and shut down two of its products, MariaDB Xpand and MariaDB SkySQL. Three months later, Microsoft announced that Azure Database for MariaDB was scheduled for retirement by September 19, 2025.
In the meantime, the company received a takeover proposal from existing investor Runa Capital, which didn’t work out. Then an associate company of Runa Capital by the name of RP Ventures offered MariaDB a loan of $26.5 million at an interest of 10%.
The continued losses that forced layoffs, de-listing, and product shutdowns may have also ensured the ruin of MariaDB’s commercial business, experts said.
More enterprises have been switching from the MariaDB Enterprise Server edition to the MariaDB Community Server edition ever since Microsoft announced the end of life in 2025, according to Thomas Spoelstra, a database expert with Dutch database management services firm OptimaData.
OptimaData manages multiple database management systems including Microsoft SQL Server, Oracle Database, Sybase, MySQL, MariaDB, MongoDB, and PostgreSQL.
MariaDB Enterprise always has been less popular than the community edition, Spoelstra said, adding that most of OptimaData’s clients use the latter because technical support for MariaDB Enterprise is “very” expensive.
This results in most enterprises using the community edition along with MariaDB offerings such as the Galera Cluster, the expert explained.
Additionally, Spoelstra said that not only have the financial difficulties forced enterprise customers to look at other options but have forced cloud service providers to slowly steer away from MariaDB’s commercial offerings.
Samsung is one example of an enterprise customer who might face challenges due to the shuttering of MariaDB Xpand and eventually look at other options. This could pose a significant cost for the Korean giant, as the company uses 50 MariaDB Xpand nodes to operate a single database where it hosts data of its smartphone customers.
An email sent to Samsung seeking more details on their MariaDB investment went unanswered.
In addition, the Korean electronics giant’s cloud and technology services division, Samsung SDS, offers MariaDB as a managed database offering. A separate email seeking responses on the availability of the service and its planned continuity also went unanswered.
The discontinuation of offerings by MariaDB has forced enterprise customers to lose confidence in the company, said Tony Baer, principal analyst at dbInsight. These kinds of developments will make any customer enterprise insecure about whether their investments will be next for the chopping block, Baer added.
Although the decisions, such as laying off staffers or discontinuation of offerings, were taken by MariaDB to reduce costs, these decisions have impacted the profile of the company, according to Matt Aslett, director at Ventana Research, an arm of research and advisory firm ISG.
The impact has been profound, especially in relation to the company’s DBaaS and distributed SQL offerings, which were potential areas of long-term growth and innovation, Aslett explained.
Given the current plight of MariaDB’s commercial business, Baer said that he sees any acquisition activity as “nothing more than a Hail Mary pass to protect what are now stranded legacy customer investments.”
In fact, if Spoelstra is correct the acquisition by K1 or any other company will further accelerate the movement of customers from MariaDB to MySQL, ProxySQL, and other options.
Presently, MariaDB, according to data from 6Sense, has a 2.08% share of the relational database market category, which is 0.07% less than what the company had reported in April of last year.
For the quarter ended December, MariaDB PLC posted a net loss of $8.8 million, driven by interest expense, restructuring costs, and costs associated with the discontinuation of products.
Next read this:
Posted by Richy George on 21 February, 2024
A non-binding proposal to acquire MariaDB, the provider of the relational database management system (RDBMS) of the same name—a fork of the open-source MySQL database, has sparked speculations about the company’s future and what the acquisition would mean for its enterprise customers.
The proposal was for MariaDB PLC, the firm that provides database services and SaaS offerings built on the core open-source database that is managed by the MariaDB Foundation.
Earlier this month, MariaDB PLC received a proposal of acquisition, to the tune of $37 million, from California-headquartered investment firm K1 Investment Management.
The proposal, which is non-binding and may not result in an actual offer for acquisition, puts a value of $0.55 for each share of MariaDB—a 189% premium over the database firm’s closing share price on February 5.
MariaDB PLC has been on a rocky ride for the past year, including laying off staffers, changing leadership, spinning off parts of its business, and filing cautionary statements with the US Securities and Exchange Commission (SEC).
The company’s path to financial difficulty began in December 2022 when it decided to go public via the special purpose acquisition company (SPAC) route with Angel Pond Holdings.
After going public, the company saw its market capitalization plummet from $445 million to just over $10 million by the end of 2023. The sharp drop in value can be attributed to the company’s poor quarterly performance and history of losses since the last quarter of 2022, according to statements filed with the SEC.
While the first quarter of 2023 saw the company lay off staffers, the second quarter saw it file cautionary statements about its financial health via a prospectus. The company said at the time that it was looking at attracting financial investments to keep the lights on.
This was followed by the New York Stock Exchange (NYSE) issuing a warning to the company in September. The stock exchange had warned MariaDB that it was failing to meet listing norms that make it necessary for listed firms to ensure that their market capitalization doesn’t drop below $50 million for a trading period of 30 days.
October brought in more woes for the database-as-a-service provider with the company being forced to lay off 28% of its workforce and shut down two of its products, MariaDB Xpand and MariaDB SkySQL. Three months later, Microsoft announced that Azure Database for MariaDB was scheduled for retirement by September 19, 2025.
In the meantime, the company received a takeover proposal from existing investor Runa Capital, which didn’t work out. Then an associate company of Runa Capital by the name of RP Ventures offered MariaDB a loan of $26.5 million at an interest of 10%.
The continued losses that forced layoffs, de-listing, and product shutdowns may have also ensured the ruin of MariaDB’s commercial business, experts said.
More enterprises have been switching from the MariaDB Enterprise Server edition to the MariaDB Community Server edition ever since Microsoft announced the end of life in 2025, according to Thomas Spoelstra, a database expert with Dutch database management services firm OptimaData.
OptimaData manages multiple database management systems including Microsoft SQL Server, Oracle Database, Sybase, MySQL, MariaDB, MongoDB, and PostgreSQL.
MariaDB Enterprise always has been less popular than the community edition, Spoelstra said, adding that most of OptimaData’s clients use the latter because technical support for MariaDB Enterprise is “very” expensive.
This results in most enterprises using the community edition along with MariaDB offerings such as the Galera Cluster, the expert explained.
Additionally, Spoelstra said that not only have the financial difficulties forced enterprise customers to look at other options but have forced cloud service providers to slowly steer away from MariaDB’s commercial offerings.
Samsung is one example of an enterprise customer who might face challenges due to the shuttering of MariaDB Xpand and eventually look at other options. This could pose a significant cost for the Korean giant, as the company uses 50 MariaDB Xpand nodes to operate a single database where it hosts data of its smartphone customers.
An email sent to Samsung seeking more details on their MariaDB investment went unanswered.
In addition, the Korean electronics giant’s cloud and technology services division, Samsung SDS, offers MariaDB as a managed database offering. A separate email seeking responses on the availability of the service and its planned continuity also went unanswered.
The discontinuation of offerings by MariaDB has forced enterprise customers to lose confidence in the company, said Tony Baer, principal analyst at dbInsight. These kinds of developments will make any customer enterprise insecure about whether their investments will be next for the chopping block, Baer added.
Although the decisions, such as laying off staffers or discontinuation of offerings, were taken by MariaDB to reduce costs, these decisions have impacted the profile of the company, according to Matt Aslett, director at Ventana Research, an arm of research and advisory firm ISG.
The impact has been profound, especially in relation to the company’s DBaaS and distributed SQL offerings, which were potential areas of long-term growth and innovation, Aslett explained.
Given the current plight of MariaDB’s commercial business, Baer said that he sees any acquisition activity as “nothing more than a Hail Mary pass to protect what are now stranded legacy customer investments.”
In fact, if Spoelstra is correct the acquisition by K1 or any other company will further accelerate the movement of customers from MariaDB to MySQL, ProxySQL, and other options.
Presently, MariaDB, according to data from 6Sense, has a 2.08% share of the relational database market category, which is 0.07% less than what the company had reported in April of last year.
For the quarter ended December, MariaDB PLC posted a net loss of $8.8 million, driven by interest expense, restructuring costs, and costs associated with the discontinuation of products.
Next read this:
Posted by Richy George on 16 February, 2024

One of the things that has often driven me nuts with the rise of cloud computing is the assumption that the demise of the mainframe is a foregone conclusion. I’ve often written about the reality that not all applications and data sets belong on the cloud, especially ones that reside on mainframes.
Although I have often been laughed out of a meeting for this opinion, adoption patterns have proved me correct. It’s often spun as a pushback on cloud computing itself, but it’s just pragmatism.
The truth is that we’re going to find applications and data sets (more than you think), that are not viable to move to the cloud. I call this the point of saturation, when we’re done moving most of the applications to the cloud that are practical to relocate. I’ve had mainframe applications in mind when saying that, and for good reason.
Those who push back on this assertion quickly point out that some tools and technologies allow older mainframe applications to be ported to a cloud provider. These solid products set up emulators and code converters to run mainframe-based applications on public cloud providers.
Yes, you can go this route. But should you? The answer is often no. Consider the additional cost, risk, and the reality that these applications will have value for much longer than many predicted.
A survey from application modernization firm Advanced found that digital transformation is typically a priority. However, that often does not mean the end for the mainframe. Indeed, only 6% of respondents believed alternative technologies would replace the mainframe shortly.
More than half of the companies (52%) plan to maintain or grow their dependency on mainframes. Moreover, half of respondents said mainframes are their preferred platform for core applications (56%).
I’ve always seen an integration and coexistence policy as a better path, depending on how an enterprise uses the mainframe. Even with the explosive interest in generative AI where the mainframe won’t be a preferred platform (see the same report), mainframes become a primary server of training data. They sometimes have historical data that goes back 50 years. That’s invaluable for building large language models, which should learn from old as well as new data.
I don’t mean that we should prefer a mainframe platform over any other platform; it should be fairly considered—as all platform options should be. Sometimes the cloud will be a better host, sometimes edge computing, and in some cases, mainframes will continue to provide value. This “it depends” response drives everyone nuts, but it is usually the correct answer to these problems.
This approach creates a digital ecosystem of many different platforms, all of which are the best platforms for the specific use cases. Thus, we also need to improve at managing complexity and heterogeneity, which enterprises are not excelling at today. Enterprises are unable to find value in cloud deployment due to too much operational complexity and no finops oversight. Whether you use mainframes or not, you need to address that problem.
I’m not advocating for mainframe platforms. They come with issues, including the big one that mainframe developers and operators are retiring, and there is a shortage of mainframe talent. Many younger IT pros are not attracted to the mainframe space due to its lack of “coolness.”
However, those who understand mainframes and cloud-based platforms are in high demand, typically commanding salaries 20%-30% above their peers. Even cloud architects who know how to interact with mainframes are often paid a premium. Are you noticing a pattern?
I’m a pragmatist. We will use the platforms that can return the most value to the business. I don’t care what that is if it is the most optimized solution. That should be an architect’s main objective.
Next read this:
Posted by Richy George on 15 February, 2024

Oracle has updated its Autonomous Database offering in an effort to maintain its lead over competing cloud-based database services from rivals such as AWS, Google Cloud, IBM, and Snowflake. Oracle Autonomous Database is an Oracle Cloud Infrastructure (OCI) service.
Oracle Autonomous Database, which is based on Oracle’s proprietary relational database management system (RDBMS), currently Oracle Database 23c, supports both transactional and analytical workloads.
The key differentiator for Autonomous Database is that its underlying management system automates patching, upgrades, and tuning, handling all routine database maintenance tasks without any manual intervention.
Autonomous Database supports four distinct workloads, including transaction processing, analytics and data warehousing, transactions and analytics on JSON data, and APEX application development, which is a managed low-code application development platform for building and deploying data-driven applications.
The latest updates include support for conversations in Select AI, new spatial enhancement in Oracle Machine Learning, a no-code model monitoring interface, and a new interface for Autonomous Database Graph Studio.
Oracle has added support for conversations to Select AI. Select AI, which was introduced in September last year, allows enterprise users to analyze their data using natural language, and with the help of large language models (LLMs) accessed via the OCI Generative AI service.
However, prior to this update, Select AI didn’t have the ability to remember previous questions, or allow users to ask follow-up questions.
“Select AI now makes that chat history available to the LLM so that it can interpret the context of follow-up questions. Users can now have a ‘conversation’ with their database to explore and narrow down the answers they need,” George Lumpkin, vice president of product management at Oracle, wrote in a blog post.
Enterprise users also can ask Select AI to produce the generated SQL and a description of the query processing, Lumpkin said.
The new capabilities of Select AI, according to research and advisory firm ISG’s executive director David Menninger, will help to ease the burden on developers and improve productivity.
“Without the context of a previous query, it means an enterprise developer would have to repeat a problem or request, modifying it as appropriate. That would quickly become frustrating and defeat the whole purpose,” Menninger said, adding that previously Select AI could just generate a basic structure of the SQL query from a natural language input.
dbInsight’s principal analyst Tony Baer believes that the new update takes AI copilots, or AI systems for coding, to a new level. “In addition to generating code, the language model must also ‘understand’ the logical structure of the database plus the unstructured text that is descriptive metadata. It must have a thorough understanding of query optimization as well,” Baer said.
Although Oracle’s Select AI competes with a growing number of natural language query services, including Microsoft Copilot, Github Copilot, Amazon Q, Snowflake Copilot, and Databricks IQ, Baer believes that Select AI’s differentiator is that it can understand highly complex schemas that are typical of Oracle Database deployments.
Select AI is accessible to any SQL application and is available as an integrated feature within Autonomous Database, the company said.
In order to help enterprise staff handling machine learning operations (MLOps), Oracle also has added a new no-code interface for monitoring machine learning models.
The new model monitoring interface, according to Oracle’s Lumpkin, not only will allow enterprise users to monitor models but also tweak them if required.
“For developers, improvement in model performance has long been sought and is a top priority. Examples include climate and weather modeling and improving public safety responsiveness,” said Ron Westfall, research director at The Futurum Group.
“The new capability enables Oracle’s Autonomous Database to streamline the modeling process in relation to competing offers,” Westfall added.
In addition, the company has introduced a new spatial enhancement in Oracle Machine Learning for Python, included as part of the Autonomous Database offering, that enables enterprises to include location relationships in machine learning models for improved model accuracy.
“Data scientists can detect spatial patterns through a quantitative approach—such as spatial clustering, regression, classification, and anomaly detection—without moving the data outside the database or writing complex algorithms on their own,” Lumpkin wrote.
In order to help enterprises gain more insights from their data, the company has added a new user interface for Autonomous Database’s Graph Studio that will allow enterprise to create property graph views on resource description framework (RDF) knowledge graphs using a drag-and-drop method.
“RDF knowledge graphs help apply meaning to data relationships by capturing complex associations across data in institutional silos. Enterprises can get additional insights from the data within the knowledge graphs,” Lumpkin wrote.
The new updates, which are focused on managing data, generating insights from data, and speeding application development with the help of machine learning and AI, might give Oracle a leg up against rivals, according to ISG’s Menninger.
“Oracle made bold claims years ago when it introduced Autonomous Database. At the time it was probably ahead of itself in terms of what was realistic, but the technology is catching up and making more autonomous capabilities realistic. As a result of Oracle’s early investment, I think it’s safe to say they have established a lead in providing autonomous database capabilities,” Menninger said.
ISG’s executive director further said that any database that has the potential to offload administration and management drudgery would attract enterprises, as no one wants to spend their time in these activities. “As long as the features work and are priced appropriately, they make sense for all enterprises,” he added.
These features and updates also follow the trend of software providers building AI-based capabilities inside their database offerings, thereby curtailing the need for enterprises to move their data to a separate database or data platform to develop AI or generative AI-based applications.
“The next wave of disruption in the DBMS market will be the emergence of the data ecosystem as the overall data platform,” market research firm Gartner said in a report.
Westfall from The Futurum Group believes that Select AI has put Oracle’s Autonomous Database at the forefront of data platform innovations.
“With Select AI, I see that Oracle is breaking AI ground with a generally available capability for organizations to have a contextual dialogue with their private, proprietary data—intuitively. From the demos it is simple to use so that enterprises of all sizes can use it immediately,” the research director said.
Next read this:
Posted by Richy George on 8 February, 2024
We’ve seen how Steampipe can unify access to APIs, drive metasearch, enforce KPIs as code, and detect configuration drift. The enabling plugins were, until recently, tightly bound to the Steampipe binary and to the instance of Postgres that Steampipe launches and controls. That led members of Steampipe’s open-source community to ask, “Can we use the plugins in our own Postgres databases?” Now the answer is yes—and more. But let’s focus on Postgres first.
Visit Steampipe downloads to find the installer for your OS, and run it to acquire the Postgres foreign data wrapper (FDW) distribution of a plugin—in this case, the GitHub plugin.
$ sudo /bin/sh -c "$(curl -fsSL https://steampipe.io/install/postgres.sh)" Enter the plugin name: github Enter the version (latest): Discovered: - PostgreSQL version: 14 - PostgreSQL location: /usr/lib/postgresql/14 - Operating system: Linux - System architecture: x86_64 Based on the above, steampipe_postgres_github.pg14.linux_amd64.tar.gz will be downloaded, extracted and installed at: /usr/lib/postgresql/14 Proceed with installing Steampipe PostgreSQL FDW for version 14 at /usr/lib/postgresql/14? - Press 'y' to continue with the current version. - Press 'n' to customize your PostgreSQL installation directory and select a different version. (Y/n): Downloading steampipe_postgres_github.pg14.linux_amd64.tar.gz... ########################################################################################### 100.0% steampipe_postgres_github.pg14.linux_amd64/ steampipe_postgres_github.pg14.linux_amd64/steampipe_postgres_github.so steampipe_postgres_github.pg14.linux_amd64/steampipe_postgres_github.control steampipe_postgres_github.pg14.linux_amd64/steampipe_postgres_github--1.0.sql steampipe_postgres_github.pg14.linux_amd64/install.sh steampipe_postgres_github.pg14.linux_amd64/README.md Download and extraction completed. Installing steampipe_postgres_github in /usr/lib/postgresql/14... Successfully installed steampipe_postgres_github extension! Files have been copied to: - Library directory: /usr/lib/postgresql/14/lib - Extension directory: /usr/share/postgresql/14/extension/
Now connect to your server as usual, using psql or another client, most typically as the postgres user. Then run these commands which are typical for any Postgres foreign data wrapper. As with all Postgres extensions, you start like this:
CREATE EXTENSION steampipe_postgres_fdw_github;To use a foreign data wrapper, you first create a server:
CREATE SERVER steampipe_github FOREIGN DATA WRAPPER steampipe_postgres_github OPTIONS (config 'token="ghp_..."');Use OPTIONS to configure the extension to use your GitHub access token. (Alternatively, the standard environment variables used to configure a Steampipe plugin—it’s just GITHUB_TOKEN in this case—will work if you set them before starting your instance of Postgres.)
The tables provided by the extension will live in a schema, so define one:
CREATE SCHEMA github;Now import the schema defined by the foreign server into the local schema you just created:
IMPORT FOREIGN SCHEMA github FROM SERVER steampipe_github INTO github;Now run a query!
The foreign tables provided by the extension live in the github schema, so by default you’ll refer to tables like github.github_my_repository. If you set search_path = 'github', though, the schema becomes optional and you can write queries using unqualified table names.
select
count(*)
from
github_my_repository;
count
-------
468
If you have a lot of repos, the first run of that query will take a few seconds. The second run will return results instantly, though, because the extension includes a powerful and sophisticated cache.
And that’s all there is to it! Every Steampipe plugin is now also a foreign data wrapper that works exactly like this one. You can load multiple extensions in order to join across APIs. Of course you can join any of these API-sourced foreign tables with your own Postgres tables. And to save the results of any query, you can prepend create table NAME as or create materialized view NAME as to a query to persist results as a table or view.
Visit Steampipe downloads to find the installer for your OS, and run it to acquire the SQLite distribution of the same plugin.
$ sudo /bin/sh -c "$(curl -fsSL https://steampipe.io/install/sqlite.sh)" Enter the plugin name: github Enter version (latest): Enter location (current directory): Downloading steampipe_sqlite_github.linux_amd64.tar.gz... ############################################################################ 100.0% steampipe_sqlite_github.so steampipe_sqlite_github.linux_amd64.tar.gz downloaded and extracted successfully at /home/jon/steampipe-sqlite.
Here’s the setup. You can place this code in ~/.sqliterc if you want to run it every time you start sqlite.
.load /home/jon/steampipe-sqlite/steampipe_sqlite_github.so
select steampipe_configure_github('
token="ghp_..."
');
Now you can run the same query as above.
sqlite> select count(*) from github_my_repository;
count(*)
468
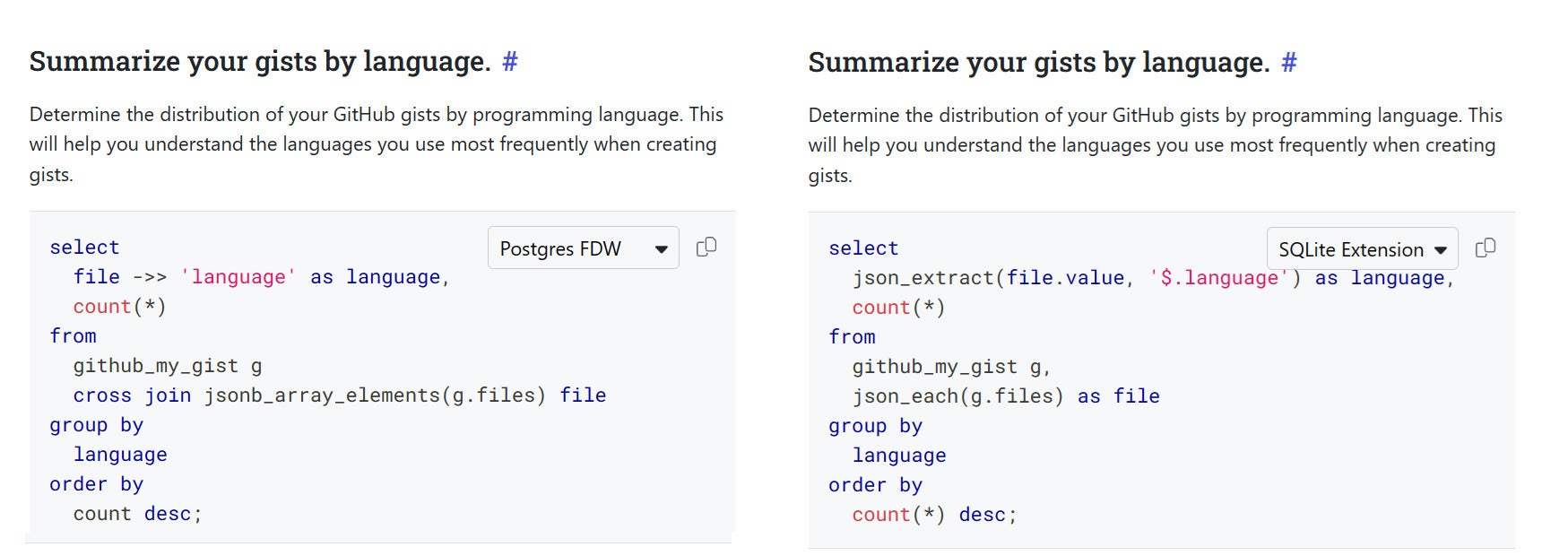
What about the differences between Postgres-flavored and SQLite-flavored SQL? The Steampipe hub is your friend! For example, here are variants of a query that accesses a field inside a JSON column in order to tabulate the languages associated with your gists.
Here too you can load multiple extensions in order to join across APIs. You can join any of these API-sourced foreign tables with your own SQLite tables. And you can prepend create table NAME as to a query to persist results as a table.
Visit Steampipe downloads to find the installer for your OS, and run it to acquire the export distribution of a plugin. Again, we’ll illustrate using the GitHub plugin.
$ sudo /bin/sh -c "$(curl -fsSL https://steampipe.io/install/export.sh)" Enter the plugin name: github Enter the version (latest): Enter location (/usr/local/bin): Created temporary directory at /tmp/tmp.48QsUo6CLF. Downloading steampipe_export_github.linux_amd64.tar.gz... ############################################################################## 100.0% Deflating downloaded archive steampipe_export_github Installing Applying necessary permissions Removing downloaded archive steampipe_export_github was installed successfully to /usr/local/bin
$ steampipe_export_github -h
Export data using the github plugin.
Find detailed usage information including table names, column names, and
examples at the Steampipe Hub: https://hub.steampipe.io/plugins/turbot/github
Usage:
steampipe_export_github TABLE_NAME [flags]
Flags:
--config string Config file data
-h, --help help for steampipe_export_github
--limit int Limit data
--output string Output format: csv, json or jsonl (default "csv")
--select strings Column data to display
--where stringArray where clause data
There’s no SQL engine in the picture here; this tool is purely an exporter. To export all your gists to a JSON file:
steampipe_export_github github_my_gist --output json > gists.json
To select only some columns and export to a CSV file:
steampipe_export_github github_my_gist --output csv --select "description,created_at,html_url" > gists.csv
You can use --limit to limit the rows returned, and --where to filter them, but mostly you’ll use this tool to quickly and easily grab data that you’ll massage elsewhere, for example in a spreadsheet.
Steampipe plugins aren’t just raw interfaces to underlying APIs. They use tables to model those APIs in useful ways. For example, the github_my_repository table exemplifies a design pattern that applies consistently across the suite of plugins. From the GitHub plugin’s documentation:
You can own repositories individually, or you can share ownership of repositories with other people in an organization. The
github_my_repositorytable will list repos that you own, that you collaborate on, or that belong to your organizations. To query ANY repository, including public repos, use thegithub_repositorytable.
Other plugins follow the same pattern. For example, the Microsoft 365 plugin provides both microsoft_my_mail_message and microsoft_mail_message, and the Google Workspace plugin provides googleworkspace_my_gmail_message and googleworkspace_gmail. Where possible, plugins consolidate views of resources from the perspective of an authenticated user.
While plugins typically provide tables with fixed schemas, that’s not always the case. Dynamic schemas, implemented by the Airtable, CSV, Kubernetes, and Salesforce plugins (among others), are another key pattern. Here’s a CSV example using a stand-alone Postgres FDW.
IMPORT FOREIGN SCHEMA csv FROM SERVER steampipe_csv INTO csv OPTIONS(config 'paths=["/home/jon/csv"]');
Now all the .csv files in /home/jon/csv will automagically be Postgres foreign tables. Suppose you keep track of valid owners of EC2 instances in a file called ec2_owner_tags. Here’s a query against the corresponding table.
select * from csv.ec2_owner_tags;
owner | _ctx
----------------+----------------------------
Pam Beesly | {"connection_name": "csv"}
Dwight Schrute | {"connection_name": "csv"}
You could join that table with the AWS plugin’s aws_ec2_instance table to report owner tags on EC2 instances that are (or are not) listed in the CSV file.
select
ec2.owner,
case
when csv.owner is null then 'false'
else 'true'
end as is_listed
from
(select distinct tags ->> 'owner' as owner from aws.aws_ec2_instance) ec2
left join
csv.ec2_owner_tags csv on ec2.owner = csv.owner;
owner | is_listed ----------------+----------- Dwight Schrute | true Michael Scott | false
Across the suite of plugins there are more than 2,300 pre-defined fixed-schema tables that you can use in these ways, plus an unlimited number of dynamic tables. And new plugins are constantly being added by Turbot and by Steampipe’s open-source community. You can tap into this ecosystem using Steampipe or Turbot Pipes, from your own Postgres or SQLite database, or directly from the command line.
Next read this:





This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →
Copyright 2015 - InnovatePC - All Rights Reserved
Site Design By Digital web avenue