

Dell Latitude E6410 Notebook| Quantity Available: 40+
This post is intended for businesses and other organizations interested... Read more →
Posted by Richy George on 5 February, 2024

NoSQL databases arose in response to the limitations of using SQL (Structured Query Language) for database queries. NoSQL databases store and manage data in ways that enable high operational speed and a level of flexibility not found in traditional relational database management systems (RDBMSs).
A recent report by Allied Market Research notes the demand for NoSQL databases is on the rise. In 2022, the worldwide NoSQL market generated $7.3 billion in sales, and is estimated to generate $86.3 billion by 2032—a compound annual growth rate of 28 percent for that period. Key factors driving global NoSQL market growth, according to the report, are the exploding demand for big data analytics, a need for more scalable and flexible enterprise database solutions, and the ubiquity of cloud computing platforms and technology.
If your enterprise is considering migrating to NoSQL, you may wonder how to choose the best NoSQL database for your data storage needs. With more than two dozen open source and commercial NoSQL databases available, you have plenty of options to choose from.
This article presents five questions to help guide your NoSQL database buying decision. See the end of the article for an overview of the leading NoSQL databases on the market today.
Before choosing a NoSQL database, it’s important to be certain that NoSQL is the best choice for your needs. Carl Olofson, research vice president at International Data Corp. (IDC), says “back office transaction processing, high-touch interactive application data management, and streaming data capture” are all good reasons for choosing NoSQL.
Even with these needs in mind, it is important to rule out the possibility that NoSQL is not the right fit for your enterprise, especially because there are tradeoffs to choosing NoSQL over a traditional RDBMS. “The first decision you need to make is why do you need a NoSQL database system,” says Craig Mullins, president and principal consultant at Mullins Consulting. “You need to first understand why an existing relational DBMS cannot fulfill your use case. Relational/SQL database systems are widely installed and most organizations have existing systems and applications deployed on RDBMS with skilled technicians to manage them.”
An alternative to replacing the RDBMS, says Mullins, is polyglot persistence—employing multiple data storage technologies within a single system so as to meet different data storage needs. Rather than “force-fitting everything into a relational mindset,” polyglot persistence lets developers and administrators “choose the appropriate data technology for each use case,” he says.
NoSQL’s core strength is likely its decentralized, scalable, fault-tolerant design, Mullins says. “Most NoSQL database technology is implemented to scale and survive outages,” he says. “Additionally, most NoSQL options are lightweight and require less overhead than a relational DBMS, in terms of CPU and support.”
The four main types of NoSQL data models are key-value, document, column store, and graph. Each one fits a different use case. Mullins summarized the strengths of each type as follows:
“Choosing the right model is essential,” says Noel Yuhanna, vice president and principal analyst at Forrester Research. “The document model is the most popular, including the ability to store JSON documents optimally. The graph model focuses on interconnected data, while the key-value model focuses on a simple key-value pair retrieval, which is not as widely used.”
What data will be stored and how it will be accessed are essential in deciding which data model to choose, Yuhanna says. “Also, some vendor products support all models, which is the multi-model database, offering the flexibility of having multiple models.”
Is the latency requirement millisecond, subsecond, seconds, minutes, or more?
“If the latency requirement is extremely small, as for a streaming data capture or real-time data-sharing application, one should look at a key-value store,” Olofson says. “Likewise if the data is a simple list or matrix.”
If the data is highly changeable in form and includes defined fields, a JSON document database might be more appropriate, Olofson says. This is also true for a high-touch interactive application, which is typically changed frequently to adjust for shifting requirements of the application and user.
“If the latency requirement is not so great and complex combinations must be supported, including bill-of-materials structures or complex groups of interrelated data, then one might consider a graph DBMS,” Olofson says.
NoSQL databases can break down data into segments—or shards—which can be useful for large deployments running hundreds of terabytes, Yuhanna says.
“Sharding is an essential capability for NoSQL to scale databases,” Yuhanna says. “Customers often look for NoSQL solutions that can automatically expand and shrink nodes in horizontally scaled clusters, allowing applications to scale dynamically.”
Unlike relational databases, which focus on ensuring data consistency for every transaction using ACID compliance, with NoSQL, “you can choose data consistency to be eventually consistent or even relaxed,” Yuhanna says. “With eventual consistency, you can scale quickly and deliver high performance.”
Some NoSQL databases can run on-premises, some only in the cloud, while others in a hybrid cloud environment, Yuhanna says.
“Also, some NoSQL has native integration with cloud architectures, such as running on serverless and Kubernetes environments,” Yuhanna says. “We have seen serverless as an essential factor for customers, especially those who want to deliver good performance and scale for their applications, but also want to simplify infrastructure management through automation.”
Asking yourself and your organization the five questions introduced here will help you choose the right NoSQL database for your needs. Now, let’s look at some of the leading NoSQL databases on the market today.
Aerospike is an open source distributed, real-time, high-performance NoSQL database designed for applications that cannot tolerate downtime and need high read and write throughput.
Aerospike is a multi-model NoSQL and graph database that supports simultaneous data models, has unlimited scale, and enables organizations to act in real-time across billions of transactions. According to the product documentation, Aerospike uses massive parallelism and a unified storage model to ensure the smallest possible server footprint.
The platform ingests and acts on streaming data at the edge and can combine edge data with data from systems of record, third-party sources, data warehouses, or data lakes for operational, transactional, or analytical workloads. Aerospike can run on premises or as a cloud-managed service.
Amazon DynamoDB is a serverless, NoSQL, fully managed database service that provides single-digit millisecond response times at any scale. A strong selling point of this database is that it enables organizations to develop and run applications while only paying for what they use.
This cloud-based service offers encryption at rest to protect sensitive data. It also enables users to create database tables that can store and retrieve any amount of data and serve any level of request traffic. Users can scale a table’s throughput capacity up or down without downtime or performance degradation, according to AWS. Developers and admins can use the AWS Management Console to monitor resource utilization and performance metrics.
DynamoDB also provides on-demand backup capability, allowing users to create full backups of tables for long-term retention and for regulatory compliance needs.
Couchbase Server, distributed by Couchbase Inc., is a multi-model JSON document support database platform. It’s an open source NoSQL key-value and document database with built-in cache. It’s suitable for enterprises that need a database that can deliver performance, multi-model, scale, and automation.
Organizations use the platform to support social media and mobile applications, content and metadata stores, e-commerce transactions, and other applications. It provides full support for documents, flexible data model, indexing, full-text search, and MapReduce for real-time analytics.
DataStax Astra DB is a fully managed, cloud-native, database-as-a-service built on Apache Cassandra. It scales dynamically and accelerates application development via a range of APIs and programming language options, so developers can build real-time applications fast and scale them without limits, according to the company.
Developers can readily ensure data security with Astra DB’s built-in security mechanisms such as Private Link, IP access controls, single sign-on, application tokens, and data encryption. Astra DB’s serverless architecture (built on microservices and API-first principles) scales automatically based on demand.
Bigtable from Google is an enterprise-grade NoSQL database service with low single-digit millisecond latency, limitless scale, and 99.999% availability, according to the company. It supports multi-tenant, mixed operational, and real-time analytical workloads.
Google says Bigtable is a key-value and wide-column store, ideal for fast access to structured, semi-structured, or unstructured data. Latency-sensitive workloads such as personalization are also a good fit for the platform. Bigtable automatically scales resources to adapt to server traffic, handling the associated sharding, replication, and query processing as needed.
MarkLogic Server is a multi-model database that combines document, semantic graph, geospatial, and relational models into a single, scalable, operational database, according to MarkLogic. It provides native storage for JSON, XML, text, RDF triples, geospatial, and binaries, with unified search-and-query interface capabilities.
The database has a search engine built into its core, providing a single platform to load data from silos and search across all the data. As such, it does not require a bolt-on search engine for full-text search. MarkLogic Server also offers enterprise data security controls such as data loss prevention.
Azure Cosmos DB is a Microsoft Azure database service that supports multiple NoSQL models and a variety of data formats including JSON and binary data. Microsoft says the database is also fully managed, with Microsoft Azure handling all the underlying infrastructure so that developers can focus on their applications and data.
Azure Cosmos DB offers security tools such as data encryption and data access controls. It features automatic and instant scalability, and open source APIs for MongoDB, Cassandra, and other NoSQL engines.
MongoDB, maintained by MongoDB Inc. and published under a combination of the Gnu Affero General Public License and the Apache License, is a free and open source, cross-platform, document-oriented database.
It uses JSON-like documents with schemas, and incorporates operational best practices learned from optimizing thousands of deployments at organizations of all sizes. The cloud-based offering can handle database management, setup and configuration, software patching, monitoring, and backups. It operates as a distributed database cluster. Key features and capabilities include fully managed backup, point-in-time recovery, a real-time performance panel, and customizable alerting.
Redis Enterprise, sponsored by Redis Labs, is an open source, key-value NoSQL in-memory database that supports both relaxed and strong consistency, a flexible schema-less model, high availability, and ease of deployment.
The platform supports key-value; a variety of data structures such as lists, sets, bitmaps, and hashes; and a variety of models through pluggable modules such as search, graph, JSON, and XML. Redis Enterprise includes a real-time indexing, querying, and full-text search engine available on-premises and as a managed service in the cloud.
Next read this:
Posted by Richy George on 5 February, 2024

Developers of a certain age are used to beginning their application development journey by choosing an operating system. Younger developers, by contrast, might start by picking a cloud. One of the most respected voices in tech suggests a different starting point, one that focuses the attention on arguably the most important component of the application stack: the database. As luminary Kelsey Hightower writes, “Early on I made the mistake of only focusing on operating systems and ignored what I now consider the most important element of computing: data.”
He’s not alone. Gatsby.js Founder Kyle Mathews has reached similar conclusions: “I’ve shifted 100% to [database]-first when prototyping.” In a world where data is the heart of the user experience, it makes sense to take a data-first approach rather than picking a language framework, for example, and taking whichever databases come with it. This approach may be easier said than done for some, however, which makes cloud API platforms like Neurelo a nice on-ramp for developers who want to put the database first but may not know how.
The big news from all the recent cloud earnings calls is AI and how it drives consumption of cloud services. (See all the mentions of AI in Microsoft’s latest earnings call.) At the heart of AI, of course, is data. Lots and lots of data. Ever since we started calling it “big data,” data has driven cloud adoption and usage.
This is true no matter what we call it or which technologies we use to store and process it. As recent O’Reilly trends show, even as technologies such as Apache Hadoop, Apache Spark, and data warehouses show declines in interest (being “legacy” technologies), interest in data just keeps booming. Interestingly, O’Reilly sees specialized databases like stand-alone vector databases as remaining relatively niche, even as more general-purpose databases such as MySQL add vector capabilities and continue to grow.
This flux in data technologies makes it even harder for developers to keep pace, constantly having to learn new technologies or new ways to use old technologies. Yet developers like Hightower suggest it’s time to make data the first choice in the technology stack, not an afterthought.
For Hightower, one way to remove the complexity from a database focus is to start simple with SQLite, rather than a more complicated database like MySQL. As he says, he’d rather “learn the fundamentals of data and how to manage it.” In other words, “I’d rather spend time learning SQL, not how to administrate a database server, which is a useful skill, but presents a huge barrier to entry.” The ease of SQLite, concurs developer Simon Willison, is that “you don’t have to run a server and you don’t need to figure out authentication.”
That’s one approach for developers new to databases, but it’s not the only one. So-called NoSQL databases can be more accessible to developers. One of the reasons developers love MongoDB is that it maps closely to the object-oriented programming that developers already know, rather than making them use ORMs (object-relational mappers) to nudge their data into a relational model. (Disclosure: I work for MongoDB.) Another option is Supabase, which provides managed PostgreSQL to enable developers to spend less time worrying about database operations.
What if you don’t want to think about the database at all, or much? Well, Neurelo might be your answer.
Neurelo offers a database abstraction platform that allows developers to work with a database without having to construct complicated SQL queries to create, retrieve, update, or delete (CRUD) records in relational databases like PostgreSQL or MySQL or to build queries using the MongoDB Query API for MongoDB. Instead, Neurelo auto-generates APIs that create both REST and GraphQL endpoints directly from the developers’ data models and schemas.
This is the heart of how Neurelo fights against the “necessary evil” of ORMs that developers have assumed they had to embrace, as Neurelo cofounder and CEO Chirag Shah says in an interview. “It’s an uphill battle” working with an ORM, he explains. “You have to go through a bunch of things, and you have to create those harnesses, and you have to maintain it, because any time your schema changes or your requirement changes you have to recalibrate the whole thing.”
It’s a pain. But there’s hope.
Traditional ORMs obscure the SQL layer, but Neurelo gives full query visibility, as the company notes on its site. Developers can inspect and improve database interactions as their comfort level with the database grows. Neurelo also helps resolve an ORM’s “N+1” problem, whereby the database makes queries in a loop, unnecessarily multiplying the number of database round trips. Neurelo combats this by using eager loading, which retrieves related data in a single query using joins. This minimizes the number of queries hitting the database and improves performance. Neurelo also goes beyond basic CRUD operations to offer advanced join read/write tasks that go across multiple entities.
In these and other ways, Neurelo allows developers—whether new to databases or experienced—to spend less time figuring out how to work with their database and more time writing their application. “You virtually get everything instantly,” Shah argues, “and you don’t have to raise a finger.” Instead of hours or weeks, “you go from zero to writing your code in minutes.”
This brings us back to Hightower’s assessment that data should be a developer’s first concern. If he’s right, tools like Neurelo can make that first concern less…concerning, without all the trade-offs that ORMs impose or the hardwiring of code that using a database driver might create. It’s a way to keep data at the heart of an application and much more approachable for developers.
Next read this:
Posted by Richy George on 31 January, 2024

San Francisco-based Zilliz has released a new version of its database-as-a-service (DBaaS) offering, Zilliz Cloud. The company claims the new version offers better performance while reducing cost of ownership compared to its previous version.
Zilliz Cloud is built atop the open source Milvus vector database management system. Zilliz was founded by engineers who had helped develop the Milvus vector database.
The new version of Zilliz Cloud, according to the company, offers 10x better performance than the original Milvus vector database. This is achieved by using the Hierarchical Navigable Small World (HNSW) graph index in combination with an improved filtered search.
HNSW, however, is table stakes for most vector databases, including those of rivals Weaviate and Pinecone. It is one of the most popular graph indexes for building vector databases.
“HNSW is increasingly a must-have capability, so Zilliz would be at a disadvantage without it being supported by its DBMS,” said Doug Henschen, principal analyst at Constellation Research.
The reason behind the popularity of graph-based indexes can be attributed to their fundamental quality of being able to find the approximate nearest neighbors in high-dimensional data while being memory efficient. This quality results in an increase in performance and reduction in cost of ownership.
Another example of a graph-based index is Vamana. Other types of indexes used in vector databases include the Inverted File Index (IVF).
Additional features of the Zilliz Cloud update include the cosine similarity metric, range search, and upsert.
The cosine similarity metric is often used for text processing, where the direction of the embedding vectors is important but the distance between them is not.
A range search is used in a vector database to narrow search results based on the distance between a query vector and database vectors.
The upsert function, in a vector database, is used to either add a new vector to the index or update one if a vector with the same ID exists.
In addition to providing a unified Milvus Client that Zilliz claims will improve the developer experience, the new version of Zilliz Cloud can be integrated with data analytics, machine learning, and streaming platforms like Apache Spark, Apache Kafka, and Airbyte.
Despite the advantages of the new version, Constellation Research’s Henschen believes that many enterprises will turn to mainstream databases they already use for capabilities such as vector embeddings and vector search.
“The challenge for vendors like Zilliz is that they don’t have the transactional data of the enterprise with them typically,” said Holger Mueller, another principal analyst at Constellation Research.
“Either they have to provide the ease of use of getting transactional data in them or they need to have a solution that helps enterprises update vectors from their system of record. Failure to do so will force enterprises to look at their existing databases, such as the ones from Oracle, AWS, IBM, and Microsoft,” Mueller added.
The competition is even stiffer for Zilliz as rivals such as Pinecone also offer their products as cloud-based services, Henschen added.
However, the analyst said that dedicated AI teams and AI developers may find performance and cost advantages in using a dedicated vector database product or service, assuming it provides all of the features they need for supporting their use cases.
Next read this:
Posted by Richy George on 29 January, 2024
Generative AI has had an immediate and enormous impact on software development. Software developers have embraced generative AI tools that help with coding, and they are working feverishly to build generative AI applications themselves. Databases can help—especially fast, scalable, multi-model databases like SingleStore.
At the inaugural SingleStore Now conference, SingleStore announced several AI-focused innovations with developers in mind. These include SingleStore hybrid search, compute service, Notebooks, and the Elegance SDK. Given the impact that AI and LLMs are having on developers, it makes sense to dive into the ways that these innovations make developing AI applications easier.
If you’ve been working with AI or LLMs in any way, you know that vector databases have become much more popular because of their ability to help you search for the nearest n representations of the data you’re working with. You can then use those search results to provide additional context to your LLM to make the responses more accurate. SingleStoreDB has supported vector functions and vector search for a number of years now, but generative AI applications require you to search among millions or billions of vector embeddings in milliseconds—which gets difficult using k-Nearest Neighbor (kNN) across huge data sets.
Hybrid search adds Approximate Nearest Neighbor (ANN) search as an additional option to the already existing k-Nearest Neighbor (kNN) search. The primary difference between ANN and kNN is in the name: approximate vs. nearest. Initial testing shows ANN to be orders of magnitude faster for vector search, taking your AI use cases from fast to real time. Real-time vector search ensures that your applications respond instantly to queries, even when that data has just been written to the database.
Hybrid search uses a number of techniques to make your search functions more performant, namely inverted file (IVF) with product quantization (PQ). With IVF with PQ, you can lower the build times of your index while improving the compression ratios and memory footprint of your vector searches. Beyond IVF with PQ, hybrid search adds the hierarchical navigable small world (HNSW) approach to allow for high-performance vector index searches using high dimensionality.
With hybrid search, you can combine all of these new indexing approaches, along with full-text search, to combine hybrid semantic (vector similarity) and lexical/keyword search in one query.
Below you can see an example of using hybrid search. To view the code in its broader context, check out the full notebook on SingleStore Spaces.
hyb_query = 'Articles about Aussie captures'
hyb_embedding = model.encode(hyb_query)
# Create the SQL statement.
hyb_statement = sa.text('''
SELECT
title,
description,
genre,
DOT_PRODUCT(embedding, :embedding) AS semantic_score,
MATCH(title, description) AGAINST (:query) AS keyword_score,
(semantic_score + keyword_score) / 2 AS combined_score
FROM news.news_articles
ORDER BY combined_score DESC
LIMIT 10
''')
# Execute the SQL statement.
hyb_results = pd.DataFrame(conn.execute(hyb_statement, dict(embedding=hyb_embedding, query=hyb_query)))
hyb_results
The above query finds the average scores of semantic and keyword searches, combines them, and sorts the news articles by this calculated score. By removing the extra complexity of performing lexical/keyword and semantic searches separately, hybrid search simplifies the code for your application.
SingleStore’s implementation of these new indexing strategies also allows us to quickly incorporate new strategies as they become available, ensuring that your application will always perform its best when backed by SingleStoreDB.
When you’re working with extremely large data sets, one of the best things you can do to keep your performance and cost in check is to perform the compute work as close to the data as possible. SingleStore compute service enables you to deploy compute resources (CPUs and GPUs) for AI, machine learning, or ETL (extract, transform, load) workloads alongside your data. With compute service, SingleStore customers can use these new compute resources to run their own machine learning models or other software in a way that allows them to have the full context of their enterprise data, without worrying about egress performance and cost.
Coupling compute service with job service (private preview), you can schedule SQL and Python jobs from within SingleStore Notebooks to process their data, train or fine-tune a machine learning model, or do other complex data transformation work. If your company often updates the fine-tuning of your AI model or LLM, you can now do so in a scheduled manner—using optimized compute platforms that live next to your data.
Many engineers and data scientists are comfortable working with Jupyter Notebooks, hosted, interactive, shareable documents in which you can write and execute code blocks, interspersed with documentation, and visualize data. What is often missing in a Jupyter environment are native connections to your databases and SQL functionality.
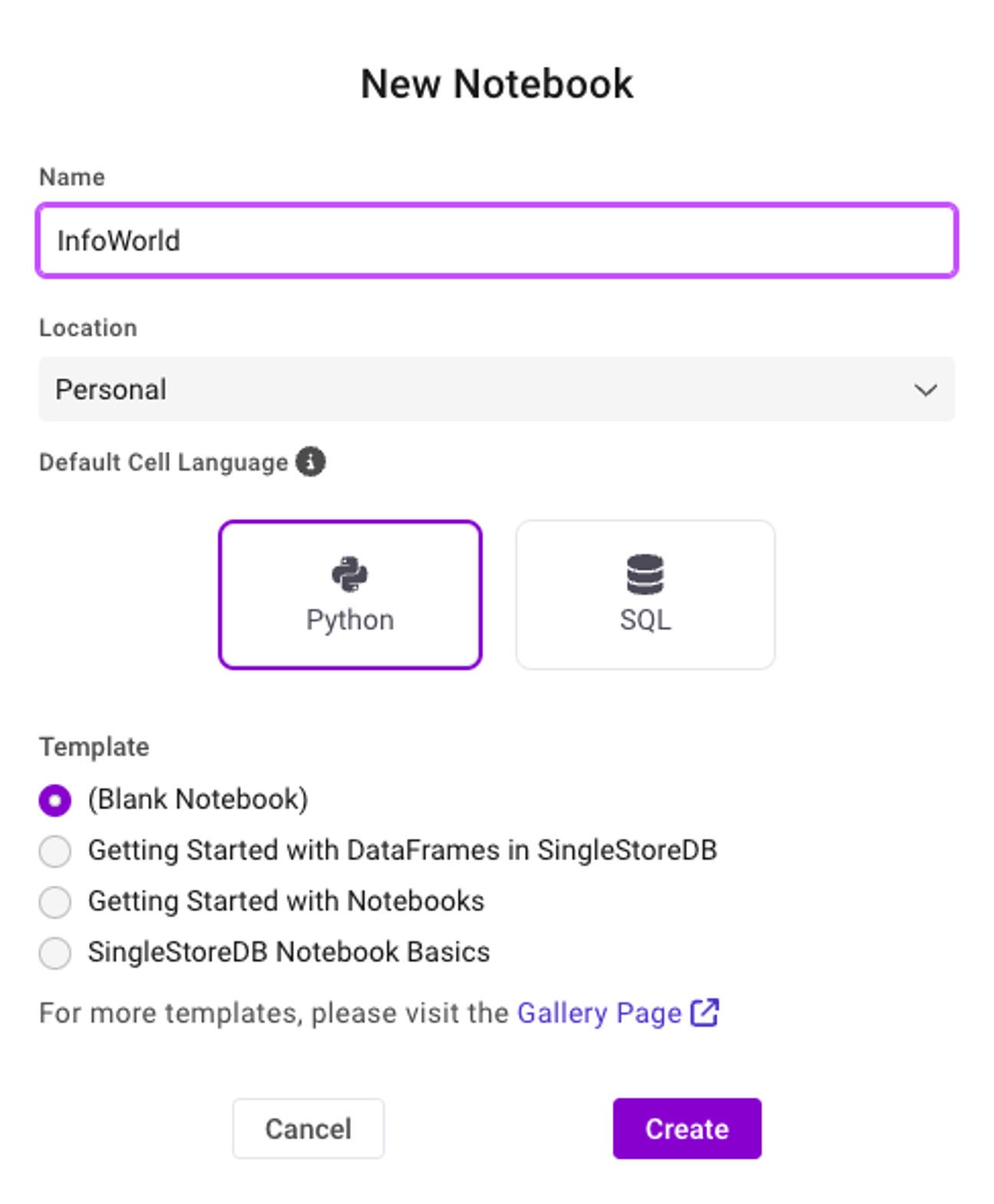
With the announcement of general availability of SingleStore Notebooks, SingleStore makes it easy for you to explore, visualize, and collaborate with your data and peers in real time. Getting started with SingleStore Notebooks is extremely simple:
In the navigation pane on the left, you’ll see Notebooks. Click the plus sign next to Notebooks and fill out the details. If you intend on sharing this notebook with your colleagues, ensure that you choose Shared under Location. Set the Default Cell Language to the language you will primarily use in the notebook, then click create.
Note: You can also choose one of the templates or select from the gallery, if you’d like to see how a Notebook can look.
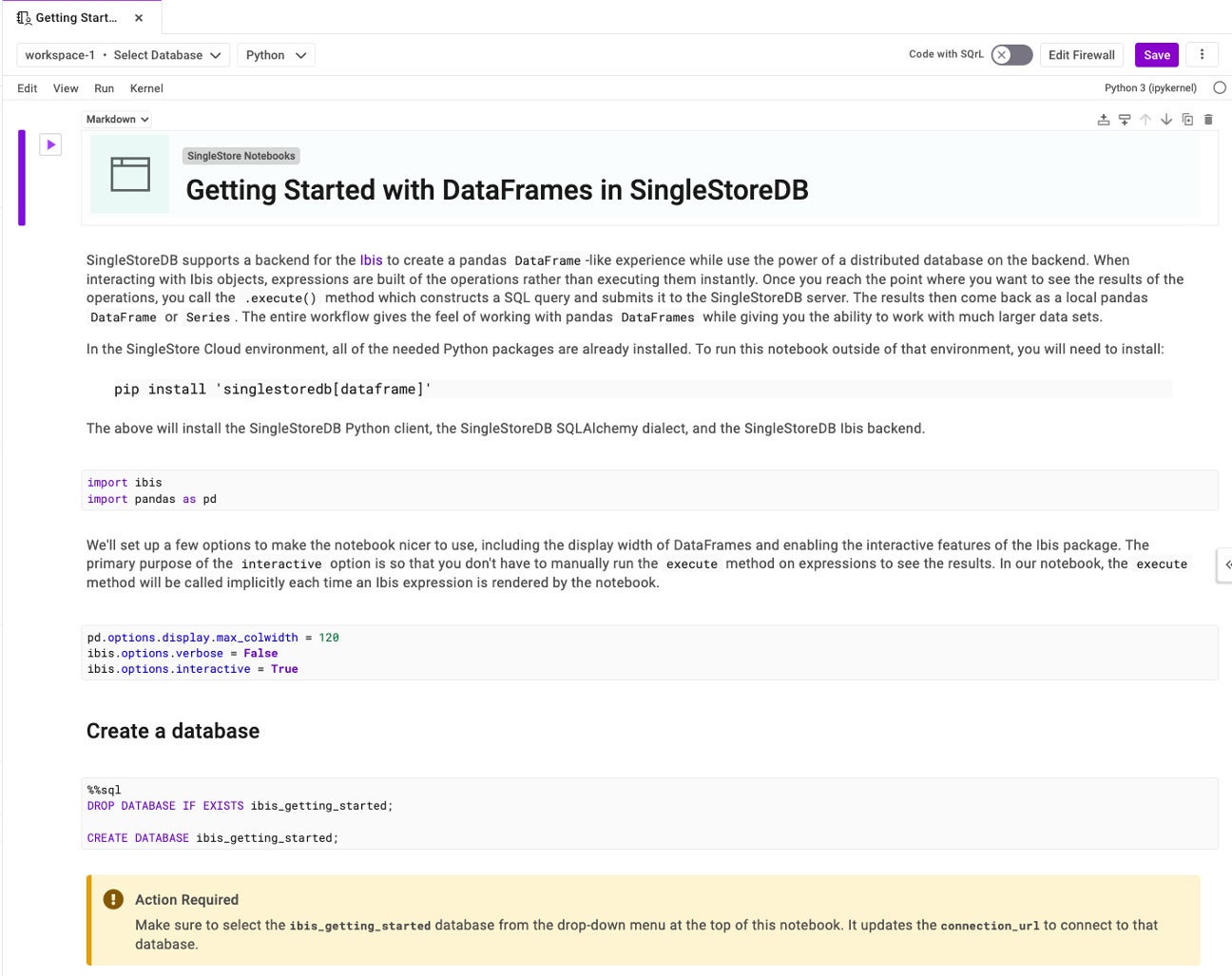
For a handy example, I have imported a notebook from the gallery called “Getting Started with DataFrames in SingleStoreDB.” This notebook walks you through the process of using pandas DataFrames to better take advantage of the distributed nature of SingleStoreDB.
When you select the Workspace and Database at the top of the notebook, it will update the connection_url variable so you can quickly and easily connect to and work with your data.
In this notebook, we use a simple command, conn = ibis.singlestoredb.connect(), to create a connection to the database. No more worrying about putting together the connection string, removing one more thing from the complex process of prototyping something using your data.
In Notebooks, you simply select the Play button next to each cell to run that code block. In the screenshot above, we’re importing packages ibis and pandas.
SingleStore Notebooks is an extremely powerful platform that will allow you to prototype applications, perform data analysis, and quickly repeat tasks that you may need to perform using your data living inside of SingleStoreDB. This rapid prototyping is an extremely effective way to see how you could implement AI, LLMs, or other big data methods into your business.
Be sure to check out SingleStore Spaces to see a large sample of Notebooks that showcase anything from image matching to building LLM apps that use retrieval-augmented generation (RAG) on your own data.
SingleStore Elegance is an NPM package designed to help React developers rapidly build applications on top of SingleStoreDB using SingleStore Kai or MySQL connections to the database. With the release of Elegance, there has never been a better time to develop an AI application that is backed by SingleStoreDB.
Elegance offers a powerful SDK covering a number of features:
Getting started with a demo application is as simple as following just a few simple steps:
git clone https://github.com/singlestore-labs/elegance-sdk-app-books-chat.git
npm i
sh ./scripts/start.sh
If you’d prefer to start from scratch and build something on your own, you can get started with a simple npm install @singlestore/elegance-sdk and follow the steps from our package page on npmjs.com.
The business landscape is changing rapidly with the mainstreaming of AI and LLMs, causing nearly everyone to evaluate whether or not they should implement some form of AI. Many companies are already putting together POCs. These releases show that SingleStore is 100% focused on building a real-time analytics and AI database that gives you the tooling you need to build your applications quickly and efficiently—getting your AI and LLM projects to market faster.
That wraps up the AI innovations that emerged from SingleStore Now. In case you were unable to make the event in person, you can watch all of the sessions on demand.
Wes Kennedy is a principal evangelist at SingleStore, where he creates content, demo environments, and videos and dives into ways that we can meet customers where they are. He has a diverse background in tech covering everything from being a virtualization engineer, sales engineer, to technical marketing.
—
Generative AI Insights provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss the challenges and opportunities of generative artificial intelligence. The selection is wide-ranging, from technology deep dives to case studies to expert opinion, but also subjective, based on our judgment of which topics and treatments will best serve InfoWorld’s technically sophisticated audience. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Contact doug_dineley@foundryco.com.
Next read this:
Posted by Richy George on 29 January, 2024
Generative AI has had an immediate and enormous impact on software development. Software developers have embraced generative AI tools that help with coding, and they are working feverishly to build generative AI applications themselves. Databases can help—especially fast, scalable, multi-model databases like SingleStore.
At the inaugural SingleStore Now conference, SingleStore announced several AI-focused innovations with developers in mind. These include SingleStore Scope, Aura, Notebooks, and the Elegance SDK. Given the impact that AI and LLMs are having on developers, it makes sense to dive into the ways that these innovations make developing AI applications easier.
If you’ve been working with AI or LLMs in any way, you know that vector databases have become much more popular because of their ability to help you search for the nearest n representations of the data you’re working with. You can then use those search results to provide additional context to your LLM to make the responses more accurate. SingleStoreDB has supported vector functions and vector search for a number of years now, but generative AI applications require you to search among millions or billions of vector embeddings in milliseconds—which gets difficult using k-Nearest Neighbor (kNN) across huge data sets.
Scope adds Approximate Nearest Neighbor (ANN) search as an additional option to the already existing k-Nearest Neighbor (kNN) search. The primary difference between ANN and kNN is in the name: approximate vs. nearest. Initial testing shows ANN to be orders of magnitude faster for vector search, taking your AI use cases from fast to real time. Real-time vector search ensures that your applications respond instantly to queries, even when that data has just been written to the database.
Scope uses a number of techniques to make your search functions more performant, namely inverted file (IVF) with product quantization (PQ). With IVF with PQ, you can lower the build times of your index while improving the compression ratios and memory footprint of your vector searches. Beyond IVF with PQ, Scope adds the hierarchical navigable small world (HNSW) approach to allow for high-performance vector index searches using high dimensionality.
With Scope, you can combine all of these new indexing approaches, along with full-text search, to combine hybrid semantic (vector similarity) and lexical/keyword search in one query.
Below you can see an example of using hybrid search. To view the code in its broader context, check out the full notebook on SingleStore Spaces.
hyb_query = 'Articles about Aussie captures'
hyb_embedding = model.encode(hyb_query)
# Create the SQL statement.
hyb_statement = sa.text('''
SELECT
title,
description,
genre,
DOT_PRODUCT(embedding, :embedding) AS semantic_score,
MATCH(title, description) AGAINST (:query) AS keyword_score,
(semantic_score + keyword_score) / 2 AS combined_score
FROM news.news_articles
ORDER BY combined_score DESC
LIMIT 10
''')
# Execute the SQL statement.
hyb_results = pd.DataFrame(conn.execute(hyb_statement, dict(embedding=hyb_embedding, query=hyb_query)))
hyb_results
The above query finds the average scores of semantic and keyword searches, combines them, and sorts the news articles by this calculated score. By removing the extra complexity of performing lexical/keyword and semantic searches separately, hybrid search simplifies the code for your application.
SingleStore’s implementation of these new indexing strategies also allows us to quickly incorporate new strategies as they become available, ensuring that your application will always perform its best when backed by SingleStoreDB.
When you’re working with extremely large data sets, one of the best things you can do to keep your performance and cost in check is to perform the compute work as close to the data as possible. SingleStore Aura enables you to deploy compute resources (CPUs and GPUs) for AI, machine learning, or ETL (extract, transform, load) workloads alongside your data. With Aura, SingleStore customers can use these new compute resources to run their own machine learning models or other software in a way that allows them to have the full context of their enterprise data, without worrying about egress performance and cost.
Coupling Aura with Aura Job Service (private preview), you can schedule SQL and Python jobs from within SingleStore Notebooks to process their data, train or fine-tune a machine learning model, or do other complex data transformation work. If your company often updates the fine-tuning of your AI model or LLM, you can now do so in a scheduled manner—using optimized compute platforms that live next to your data.
Many engineers and data scientists are comfortable working with Jupyter Notebooks, hosted, interactive, shareable documents in which you can write and execute code blocks, interspersed with documentation, and visualize data. What is often missing in a Jupyter environment are native connections to your databases and SQL functionality.
With the announcement of general availability of SingleStore Notebooks, SingleStore makes it easy for you to explore, visualize, and collaborate with your data and peers in real time. Getting started with SingleStore Notebooks is extremely simple:
In the navigation pane on the left, you’ll see Notebooks. Click the plus sign next to Notebooks and fill out the details. If you intend on sharing this notebook with your colleagues, ensure that you choose Shared under Location. Set the Default Cell Language to the language you will primarily use in the notebook, then click create.
Note: You can also choose one of the templates or select from the gallery, if you’d like to see how a Notebook can look.
For a handy example, I have imported a notebook from the gallery called “Getting Started with DataFrames in SingleStoreDB.” This notebook walks you through the process of using pandas DataFrames to better take advantage of the distributed nature of SingleStoreDB.
When you select the Workspace and Database at the top of the notebook, it will update the connection_url variable so you can quickly and easily connect to and work with your data.
In this notebook, we use a simple command, conn = ibis.singlestoredb.connect(), to create a connection to the database. No more worrying about putting together the connection string, removing one more thing from the complex process of prototyping something using your data.
In Notebooks, you simply select the Play button next to each cell to run that code block. In the screenshot above, we’re importing packages ibis and pandas.
SingleStore Notebooks is an extremely powerful platform that will allow you to prototype applications, perform data analysis, and quickly repeat tasks that you may need to perform using your data living inside of SingleStoreDB. This rapid prototyping is an extremely effective way to see how you could implement AI, LLMs, or other big data methods into your business.
Be sure to check out SingleStore Spaces to see a large sample of Notebooks that showcase anything from image matching to building LLM apps that use retrieval-augmented generation (RAG) on your own data.
SingleStore Elegance is an NPM package designed to help React developers rapidly build applications on top of SingleStoreDB using SingleStore Kai or MySQL connections to the database. With the release of Elegance, there has never been a better time to develop an AI application that is backed by SingleStoreDB.
Elegance offers a powerful SDK covering a number of features:
Getting started with a demo application is as simple as following just a few simple steps:
git clone https://github.com/singlestore-labs/elegance-sdk-app-books-chat.git
npm i
sh ./scripts/start.sh
If you’d prefer to start from scratch and build something on your own, you can get started with a simple npm install @singlestore/elegance-sdk and follow the steps from our package page on npmjs.com.
The business landscape is changing rapidly with the mainstreaming of AI and LLMs, causing nearly everyone to evaluate whether or not they should implement some form of AI. Many companies are already putting together POCs. These releases show that SingleStore is 100% focused on building a real-time analytics and AI database that gives you the tooling you need to build your applications quickly and efficiently—getting your AI and LLM projects to market faster.
That wraps up the AI innovations that emerged from SingleStore Now. In case you were unable to make the event in person, you can watch all of the sessions on demand.
Wes Kennedy is a principal evangelist at SingleStore, where he creates content, demo environments, and videos and dives into ways that we can meet customers where they are. He has a diverse background in tech covering everything from being a virtualization engineer, sales engineer, to technical marketing.
—
Generative AI Insights provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss the challenges and opportunities of generative artificial intelligence. The selection is wide-ranging, from technology deep dives to case studies to expert opinion, but also subjective, based on our judgment of which topics and treatments will best serve InfoWorld’s technically sophisticated audience. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Contact doug_dineley@foundryco.com.
Next read this:
Posted by Richy George on 18 January, 2024

Systems management and security software provider Quest Software is shipping Toad Data Studio, a platform for streamlining database management in heterogeneous relational and NoSQL database environments.
Announced January 17, Toad Data Studio allows users to manage nearly any database platform in their environment including cloud and on-premises sources and relational, NoSQL, and data warehouse sources, Quest Software said. A free trial is offered.
Toad Data Studio features an advanced SQL editor, SQL and DDL generation, and the ability to edit JSON and XML fields directly within table fields or in their own separate editing window. Users can compare data results across different queries or between different environments, either on the fly or through automated workflows, and develop desktop automations for routine tasks.
Database engineers, developers, and other databases professionals can visually profile and sample datasets for patterns, duplicates, and other attributes from a single pane of glass. Other capabilities of Toad Data Studio include letting data stewards and developers compare data schema and develop sync scripts, and moving data between systems when needed, for data professionals.
Next read this:
Posted by Richy George on 17 January, 2024

There might be few takers for Pinecone’s new serverless vector database, dubbed Pinecone Serverless, analysts believe.
“Why set up and administer a separate database—even one with the advantages of serverless scalability—if you can get the same functionality from the database you are already using and in which you are already managing your data?”, said Doug Henschen, principal analyst at Constellation Research.
Other than mainstream vector databases, such as Milvus, Weaviate, and Chroma, vector embedding and search features have either already been added or are coming soon to database service providers, including MongoDB, Couchbase, Snowflake, and Google BigQuery, among others.
“The addition of vector embeddings and search make it harder for fledgling, vector-only databases to develop a big market,” Henschen said.
Vector databases and vector search, according to experts, are two technologies that developers use to convert unstructured information into vectors, now more commonly called embeddings.
These embeddings, in turn, make storing, searching, and comparing the information easier, faster, and significantly more scalable for large datasets.
The scalability advantage of vector search has also helped it win favor among developers who are building applications based on generative AI as more data you can feed to a large language model (LLM), as and when required, the more accurate responses the model can generate, in turn making the top layer application more efficient.
However, the principal analyst said that he was not convinced that vector databases, such as Pinecone, with more bells and whistles eyeing developers and data scientists working on AI would force enterprises to pay for an additional database service that’s only used for development of AI-based applications.
Moreover, the launch of Pinecone Serverless comes at a time when IT budgets of enterprises continue to remain flat.
“While there is a lot of interest in generative AI, budgets are not yet spiking accordingly,” said Tony Baer, principal analyst at dbInsight.
“The flat budgets can be attributed to the immaturity of the field; choices of everything from tooling to foundation models to runtime services are just in their infancy, and aside from copilots and natural language query, enterprises are still on the learning curve for identifying winning use cases,” Baer added.
Along with feeding demand for generative AI, Pinecone expects the new serverless database to help enterprises reduce cost and the need to manage infrastructure.
The cost reduction is made possible by separating reads, writes, and storage, the company said, adding that the database aims to reduce latency by adopting an architecture, under which vector clustering sits on top of blob storage.
The database, according to the company, comes with new indexing and retrieval algorithms to enable fast and memory-efficient vector search from blob storage without sacrificing retrieval quality.
The new vector indexing, according to Baer, gives Pinecone an advantage over other vector and operational databases. Pinecone supports almost a dozen index types, the analyst said.
The serverless atrribute of the database, too, Baer says, is the need of the hour.
“The nature of retrieval augmented generation (RAG) workloads is that they will have the characteristics of any query-driven workload (think analytics), which are spikey in nature. Without serverless, customers must provision “just-in-case” capacity that is likely to often sit silent,” Baer explained.
A secondary reason for Pinecone taking the serverless route is to help ease developer complexity as it eliminates the need to provision servers.
Next read this:
Posted by Richy George on 15 January, 2024
AWS researchers are working on developing a large language model-based debugger for databases in an effort to help enterprises solve performance issues in such systems.
Dubbed Panda, the new debugging framework has been designed to work in a manner that is similar to a database engineer (DBE), the company wrote in a blog post, adding that troubleshooting performance issues in a database can be “notoriously hard.”
Unlike database administrators, who are tasked with managing multiple databases, database engineers are tasked with designing, developing, and maintaining databases.
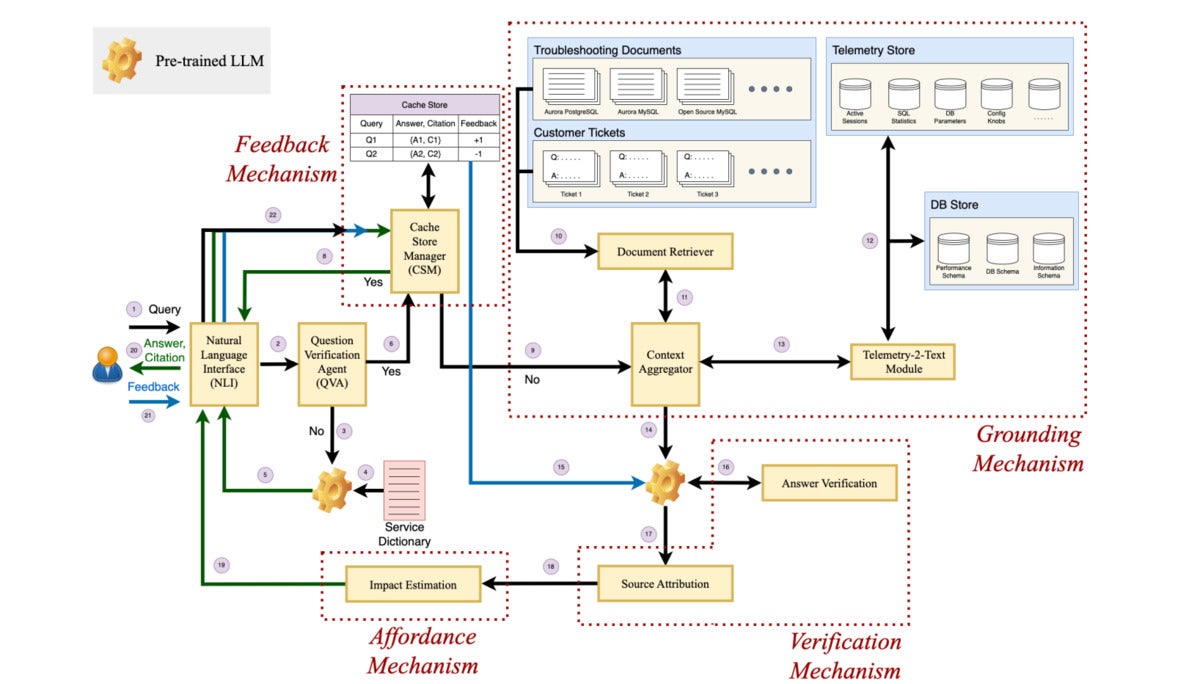
Panda, effectively, is a framework that provides context grounding to pre-trained LLMs in order to generate more “useful” and “in-context” troubleshooting recommendations, the researchers explained.
The framework includes four key components, grounding, verification, affordance, and feedback.
Researchers describe verification as the ability of the model to be able to verify the generated answer using relevant sources and produce the citation along with its output so the end user can verify it.
On the other hand, affordance can be described as the ability of the framework to inform the user about the consequences of the recommended action suggested by an LLM while explicitly highlighting high-risk action, such as DROP or DELETE, the researchers said.
Panda’s feedback component, according to the researchers, allows the LLM-based debugger to accept feedback from the user and account for those when generating responses.
These four components in turn make up the debugger’s architecture, which includes the question verification agent (QVA), the grounding mechanism, the verification mechanism, the feedback mechanism, and the affordance mechanism.
While the QVA identifies and filters out the irrelevant queries, the grounding mechanism comprises a document retriever, Telemetry-2-text, and a context aggregator to provide more context to a prompt or query.
The verification mechanism comprises the answer verification and source attribution, the researchers said, adding that all these mechanisms along with the feedback and affordance mechanism work in the background of a natural language (NL) interface which the enterprise user interacts with.
Researchers working at AWS also pitched Panda against OpenAI’s GPT-4 model, which currently underlines ChatGPT.
“…prompting ChatGPT with database performance queries often results in ‘technically correct’ but highly ‘vague’ or ‘generic’ recommendations typically rendered useless and untrustworthy by experienced database engineers (DBEs),” the researchers wrote while showcasing a result while troubleshooting an Aurora PostgreSQL database.
For the experiment, AWS researchers had gathered a group of DBEs with three different competency levels and most of them sided in favor of Panda, the paper showed.
In addition, researchers claimed that Panda, although used on cloud databases in their experiment, can be extended to any database system.
Next read this:
Posted by Richy George on 15 January, 2024
AWS researchers are working on developing a large language model-based debugger for databases in an effort to help enterprises solve performance issues in such systems.
Dubbed Panda, the new debugging framework has been designed to work in a manner that is similar to a database engineer (DBE), the company wrote in a blog post, adding that troubleshooting performance issues in a database can be “notoriously hard.”
Unlike database administrators, who are tasked with managing multiple databases, database engineers are tasked with designing, developing, and maintaining databases.
Panda, effectively, is a framework that provides context grounding to pre-trained LLMs in order to generate more “useful” and “in-context” troubleshooting recommendations, the researchers explained.
The framework includes four key components, grounding, verification, affordance, and feedback.
Researchers describe verification as the ability of the model to be able to verify the generated answer using relevant sources and produce the citation along with its output so the end user can verify it.
On the other hand, affordance can be described as the ability of the framework to inform the user about the consequences of the recommended action suggested by an LLM while explicitly highlighting high-risk action, such as DROP or DELETE, the researchers said.
Panda’s feedback component, according to the researchers, allows the LLM-based debugger to accept feedback from the user and account for those when generating responses.
These four components in turn make up the debugger’s architecture, which includes the question verification agent (QVA), the grounding mechanism, the verification mechanism, the feedback mechanism, and the affordance mechanism.
While the QVA identifies and filters out the irrelevant queries, the grounding mechanism comprises a document retriever, Telemetry-2-text, and a context aggregator to provide more context to a prompt or query.
The verification mechanism comprises the answer verification and source attribution, the researchers said, adding that all these mechanisms along with the feedback and affordance mechanism work in the background of a natural language (NL) interface which the enterprise user interacts with.
Researchers working at AWS also pitched Panda against OpenAI’s GPT-4 model, which currently underlines ChatGPT.
“…prompting ChatGPT with database performance queries often results in ‘technically correct’ but highly ‘vague’ or ‘generic’ recommendations typically rendered useless and untrustworthy by experienced database engineers (DBEs),” the researchers wrote while showcasing a result while troubleshooting an Aurora PostgreSQL database.
For the experiment, AWS researchers had gathered a group of DBEs with three different competency levels and most of them sided in favor of Panda, the paper showed.
In addition, researchers claimed that Panda, although used on cloud databases in their experiment, can be extended to any database system.
Next read this:
Posted by Richy George on 3 January, 2024

Oracle has introduced JavaScript support in the MySQL database, allowing developers to write JavaScript stored programs, i.e. JavaScript functions and procedures, in the MySQL database server.
The capability was announced on December 15, 2023. The JavaScript stored programs will be run with the GraalVM, which provides an ECMAScript-compliant runtime to execute JavaScript programs. Developers can access this MySQL-JavaScript capability in a preview in MySQL Enterprise Edition, which can be downloaded via Oracle Technology Network (OTN). MySQL-JavaScript also is offered in the MySQL Heatwave cloud service in Oracle Cloud Infrastructure (OCI), AWS, and Microsoft Azure.
Oracle said that JavaScript provides a simple syntax, support for modern language features, and a rich ecosystem of reusable code modules, while open source MySQL will be a “natural choice” of database for JavaScript developers. Support for JavaScript stored programs will improve MySQL developer productivity by leveraging an ecosystem with more developers able to write stored programs. These programs offer an advantage by minimizing data movement between the database server and applications.
MySQL-JavaScript unlocks opportunities in application design that once were constrained by a tradeoff, Oracle said. JavaScript stored programs let developers sidestep data movement and implement advanced data processing logic inside the database. Oracle cited use cases such as data extraction, data formatting, data validation, data compression and encoding, and data transformation, such as converting a column of strings into a sparse-matrix representation.
Next read this:





This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →
Copyright 2015 - InnovatePC - All Rights Reserved
Site Design By Digital web avenue