
Dell Latitude E6410 Notebook| Quantity Available: 40+
This post is intended for businesses and other organizations interested... Read more →
Posted by Richy George on 30 October, 2023
Spatiotemporal data, which comes from sources as diverse as cell phones, climate sensors, financial market transactions, and sensors in vehicles and containers, represents the largest and most rapidly expanding data category. IDC estimates that data generated from connected IoT devices will total 73.1 ZB by 2025, growing at a 26% CAGR from 18.3 ZB in 2019.
According to a recent report from MIT Technology Review Insights, IoT data (often tagged with location) is growing faster than other structured and semi-structured data (see figure below). Yet IoT data remains largely untapped by most organizations due to challenges associated with its complex integration and meaningful utilization.
The convergence of two groundbreaking technological advancements is poised to bring unprecedented efficiency and accessibility to the realms of geospatial and time-series data analysis. The first is GPU-accelerated databases, which bring previously unattainable levels of performance and precision to time-series and spatial workloads. The second is generative AI, which eliminates the need for individuals who possess both GIS expertise and advanced programming acumen.
These developments, both individually groundbreaking, have intertwined to democratize complex spatial and time-series analysis, making it accessible to a broader spectrum of data professionals than ever before. In this article, I explore how these advancements will reshape the landscape of spatiotemporal databases and usher in a new era of data-driven insights and innovation.
Originally designed to accelerate computer graphics and rendering, the GPU has recently driven innovation in other domains requiring massive parallel calculations, including the neural networks powering today’s most powerful generative AI models. Similarly, the complexity and range of spatiotemporal analysis has often been constrained by the scale of compute. But modern databases able to leverage GPU acceleration have unlocked new levels of performance to drive new insights. Here I will highlight two specific areas of spatiotemporal analysis accelerated by GPUs.
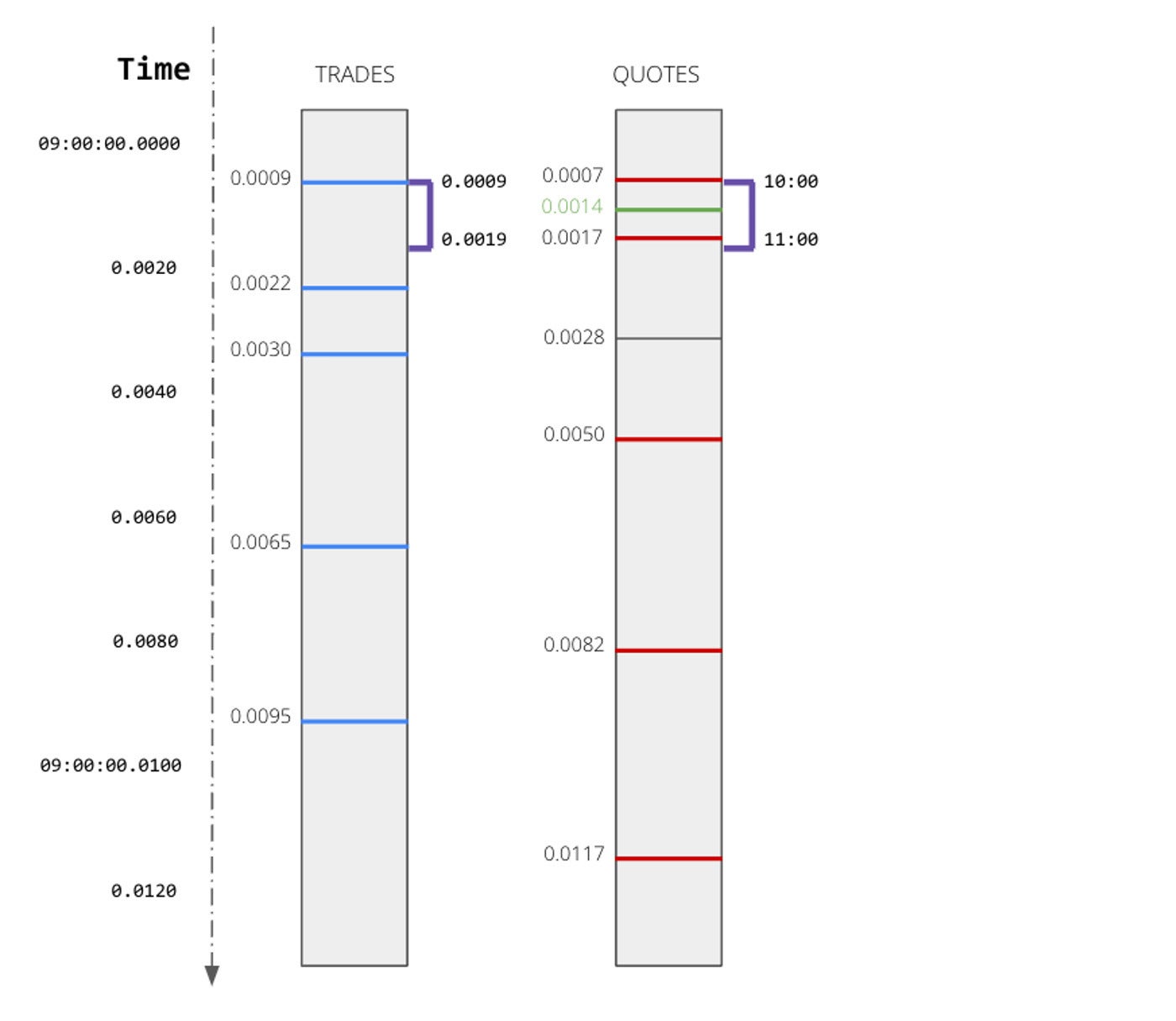
When analyzing disparate streams of time-series data, timestamps are rarely perfectly aligned. Even when devices rely on precise clocks or GPS, sensors may generate readings on different intervals or deliver metrics with different latencies. Or, in the case of stock trades and stock quotes, you may have interleaving timestamps that do not perfectly align.
To gain a common operational picture of the state of your machine data at any given time, you will need to join these different data sets (for instance, to understand the actual sensor values of your vehicles at any point along a route, or to reconcile financial trades against the most recent quotes). Unlike customer data, where you can join on a fixed customer ID, here you will need to perform an inexact join to correlate different streams based on time.
Rather than trying to build complicated data engineering pipelines to correlate time series, we can leverage the processing power of the GPU to do the heavy lifting. For instance, with Kinetica you can leverage the GPU accelerated ASOF join, which allows you to join one time-series dataset to another using a specified interval and whether the minimum or maximum value within that interval should be returned.
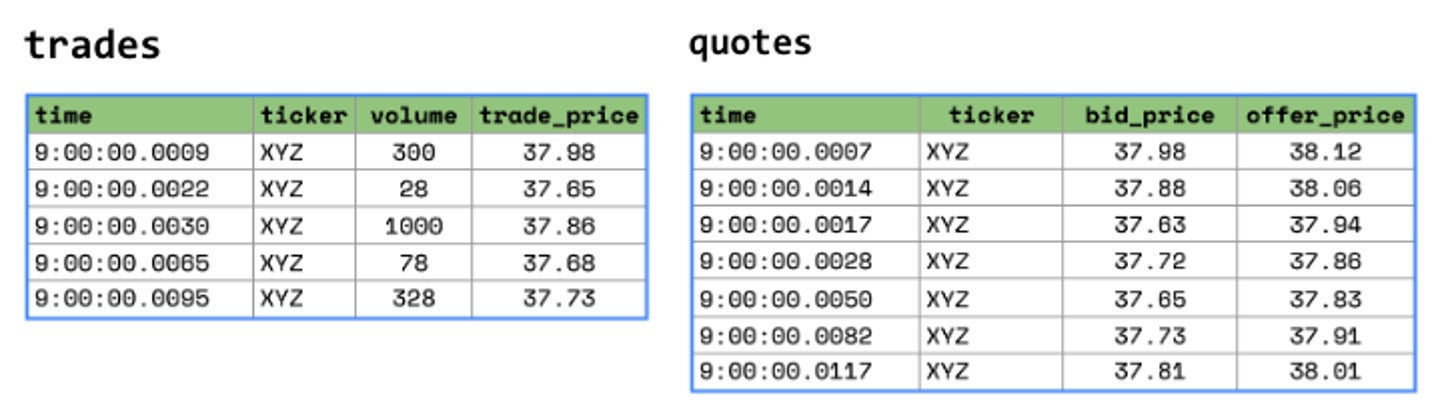
For instance, in the following scenario, trades and quotes arrive on different intervals.
If I wanted to analyze Apple trades and their corresponding quotes, I could use Kinetica’s ASOF join to immediately find corresponding quotes that occurred within a certain interval of each Apple trade.
SELECT * FROM trades t LEFT JOIN quotes q ON t.symbol = q.symbol AND ASOF(t.time, q.timestamp, INTERVAL '0' SECOND, INTERVAL '5' SECOND, MIN) WHERE t.symbol = 'AAPL'
There you have it. One line of SQL and the power of the GPU to replace the implementation cost and processing latency of complex data engineering pipelines for spatiotemporal data. This query will find for each trade the quote that was closest to that trade, within a window of five seconds after the trade. These types of inexact joins on time-series or spatial datasets are a critical tool to help harness the flood of spatiotemporal data.
Often, the first step to exploring or analyzing spatiotemporal IoT data is visualization. Especially with geospatial data, rendering the data against a reference map will be the easiest way to perform a visual inspection of the data, checking for coverage issues, data quality issues, or other anomalies. For instance, it’s infinitely quicker to visually scan a map and confirm that your vehicles’ GPS tracks are actually following the road network versus developing other algorithms or processes to validate your GPS signal quality. Or, if you see spurious data around Null Island in the Gulf of Guinea, you can quickly identify and isolate invalid GPS data sources that are sending 0 degrees for latitude and 0 degrees for longitude.
However, analyzing large geospatial datasets at scale using conventional technologies often requires compromises. Conventional client-side rendering technologies typically can handle tens of thousands of points or geospatial features before rendering bogs down and the interactive exploration experience completely degrades. Exploring a subset of the data, for instance for a limited time window or a very limited geographic region, could reduce the volume of data to a more manageable quantity. However, as soon as you start sampling the data, you risk discarding data that would show specific data quality issues, trends, or anomalies that could have been easily discovered through visual analysis.
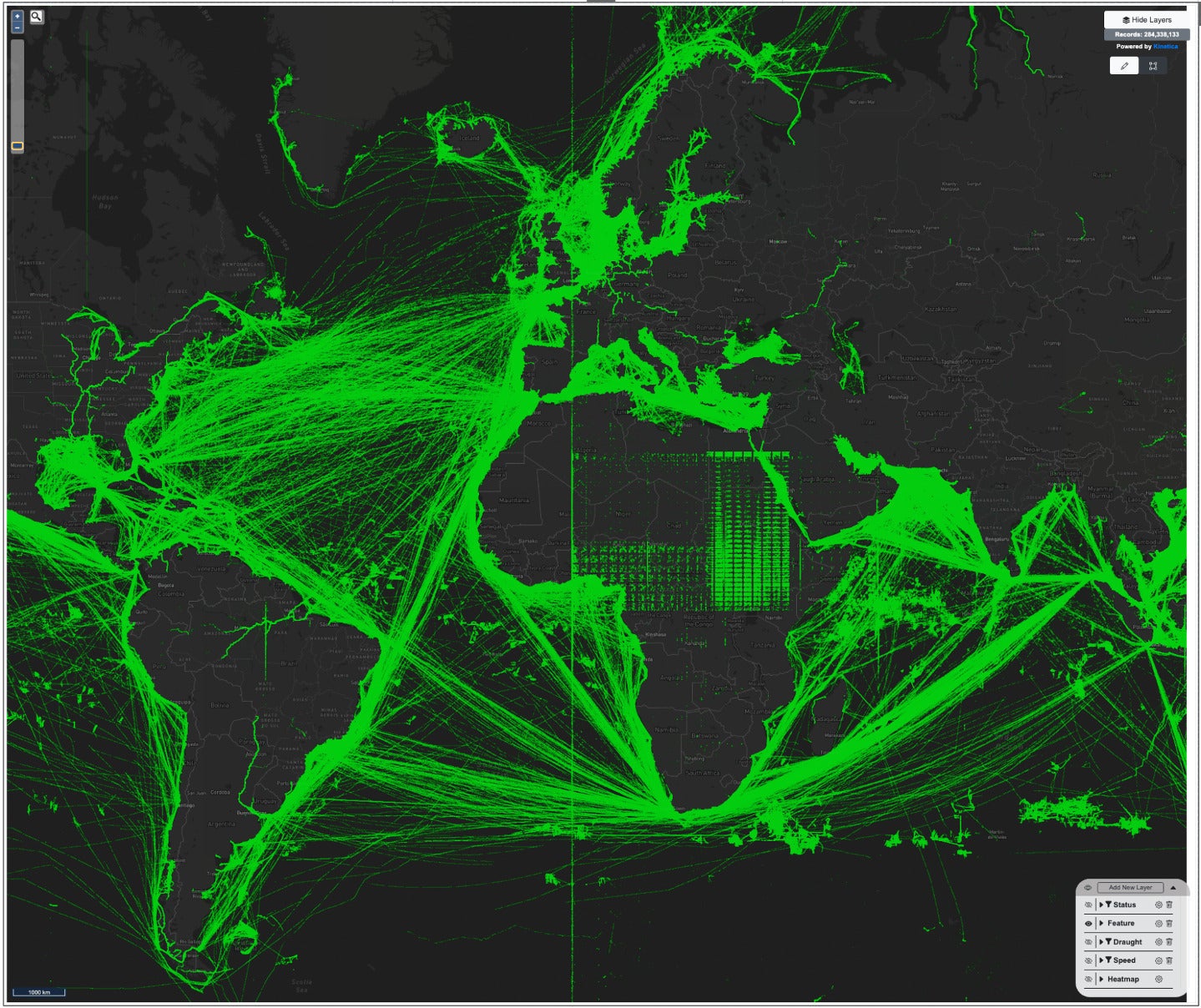
Visual inspection of nearly 300 million data points from shipping traffic can quickly reveal data quality issues, such as the anomalous data in Africa, or the band at the Prime Meridian.
Fortunately, the GPU excels at accelerating visualizations. Modern database platforms with server-side GPU rendering capabilities such as Kinetica can facilitate exploration and visualization of millions or even billions of geospatial points and features in real time. This massive acceleration enables you to visualize all of your geospatial data instantly without downsampling, aggregation, or any reduction in data fidelity. The instant rendering provides a fluid visualization experience as you pan and zoom, encouraging exploration and discovery. Additional aggregations such as heat maps or binning can be selectively enabled to perform further analysis on the complete data corpus.
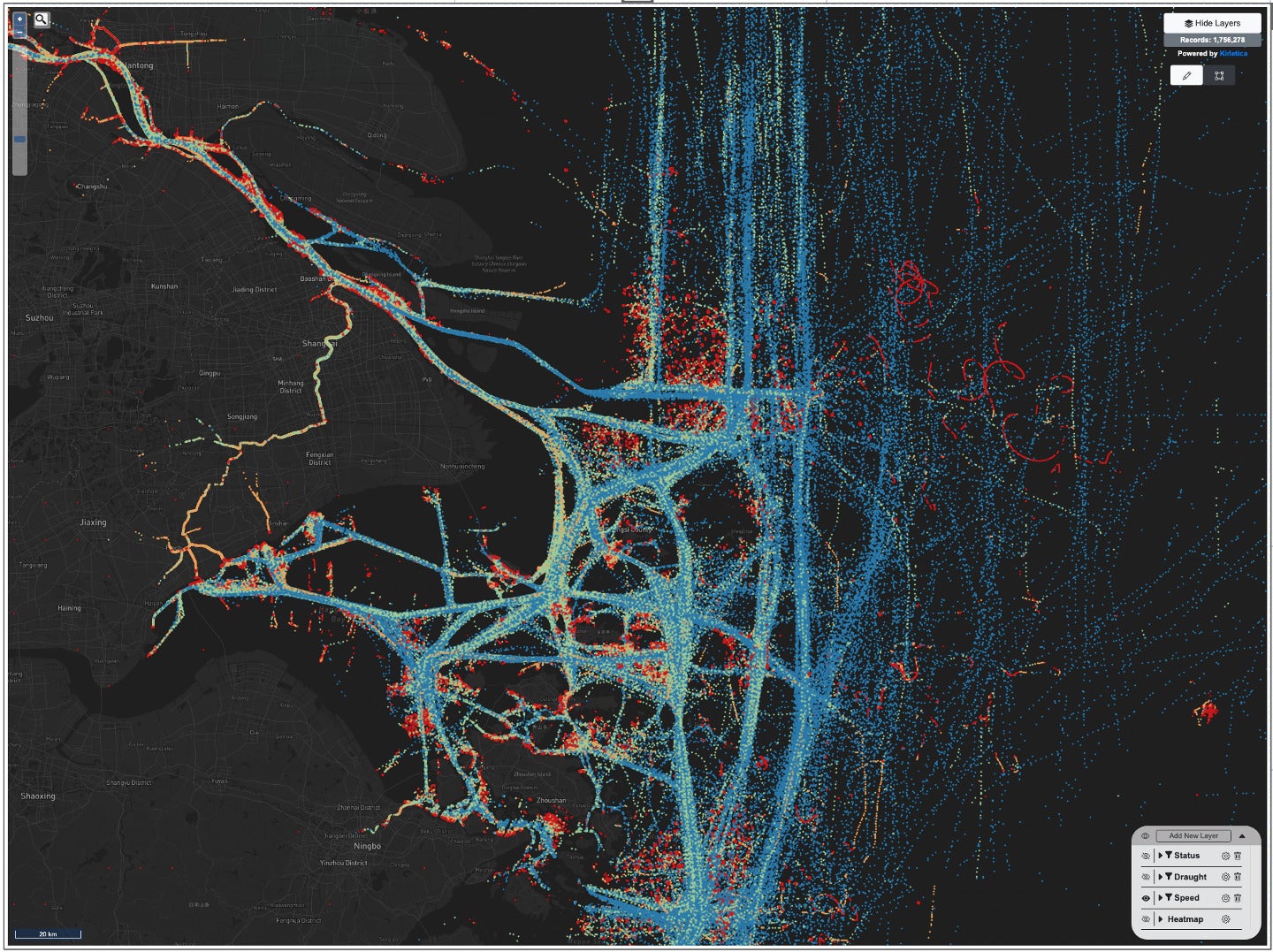
Zooming in to analyze shipping traffic patterns and vessel speed in the East China Sea.
Spatiotemporal questions, which pertain to the relationship between space and time in data, often resonate intuitively with laymen because they mirror real-world experiences. People might wonder about the journey of an item from the moment of order placement to its successful delivery. However, translating these seemingly straightforward inquiries into functional code poses a formidable challenge, even for seasoned programmers.
For instance, determining the optimal route for a delivery truck that minimizes travel time while factoring in traffic conditions, road closures, and delivery windows requires intricate algorithms and real-time data integration. Similarly, tracking the spread of a disease through both time and geography, considering various influencing factors, demands complex modeling and analysis that can baffle even experienced data scientists.
These examples highlight how spatio-temporal questions, though conceptually accessible, often hide layers of complexity that make their coding a daunting task. Understanding the optimal mathematical operations and then the corresponding SQL function syntax may challenge even the most seasoned SQL experts.
Thankfully, the latest generation of large language models (LLMs) are proficient at generating correct and efficient code, including SQL. And fine-tuned versions of those models that have been trained on the nuances of spatiotemporal analysis, such as Kinetica’s native LLM for SQL-GPT, can now unlock these domains of analysis for a whole new class of users.
For instance, let’s say I wanted to analyze the canonical New York City taxi data set and pose questions related to space and time. I start by providing the LLM with some basic context about the tables I intend to analyze. In Kinetica Cloud, I can use the UI or basic SQL commands to define the context for my analysis, including references to the specific tables. The column names and definitions for those tables are shared with the LLM, but not any data from those tables. Optionally, I can include additional comments, rules, or sample query results in the context to further improve the accuracy of my SQL.
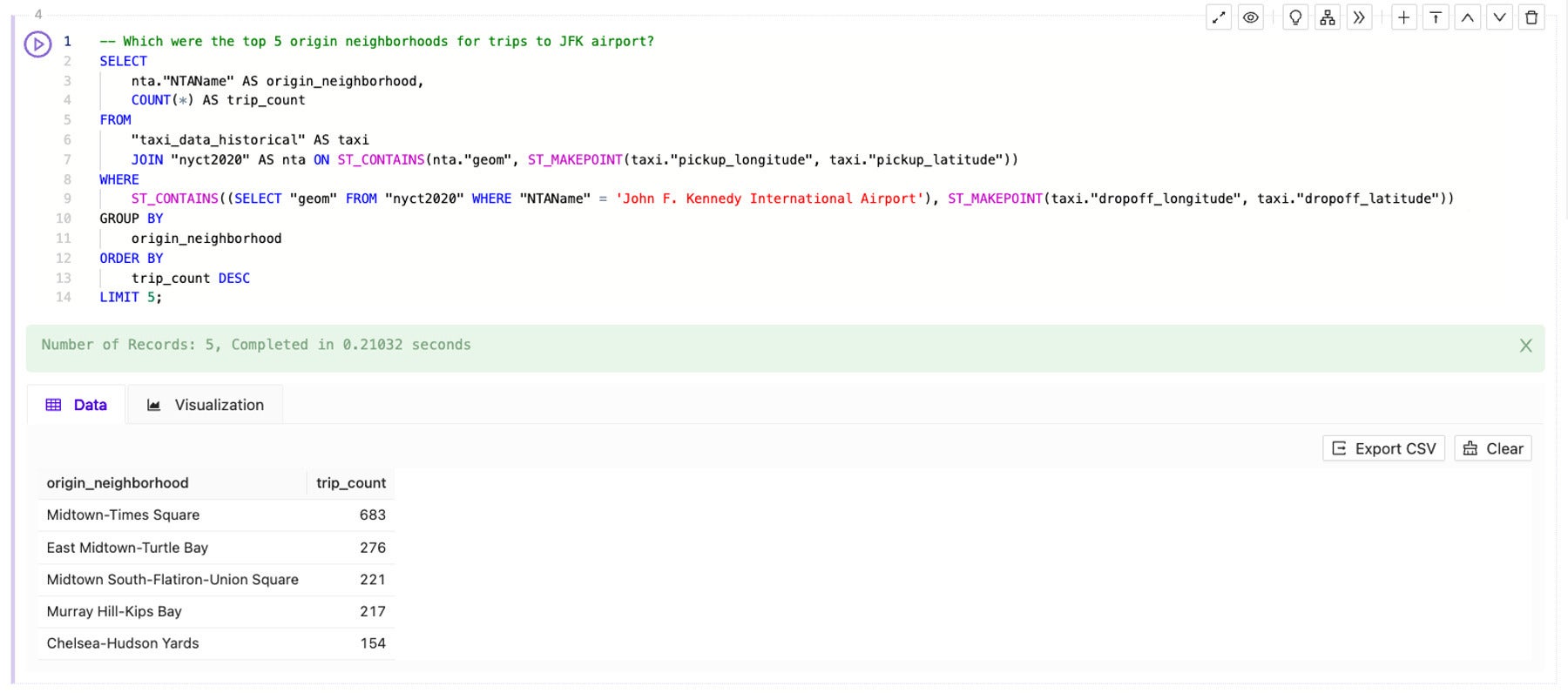
Once I have set up the initial context, I can use SQL-GPT in Kinetica Cloud to ask “Which were the top 5 origin neighborhoods for trips to JFK airport?” The fine-tuned LLM instantly generates the following SQL:
-- Which were the top 5 origin neighborhoods for trips to JFK airport? SELECT nta."NTAName" AS origin_neighborhood, COUNT(*) AS trip_count FROM "taxi_data_historical" AS taxi JOIN "nyct2020" AS nta ON ST_CONTAINS(nta."geom", ST_MAKEPOINT(taxi."pickup_longitude", taxi."pickup_latitude")) WHERE ST_CONTAINS(( SELECT "geom" FROM "nyct2020" WHERE "NTAName" = 'John F. Kennedy International Airport' ), ST_MAKEPOINT(taxi."dropoff_longitude", taxi."dropoff_latitude")) GROUP BY origin_neighborhood ORDER BY trip_count DESC LIMIT 5;
Within seconds, the fine-tuned LLM helped me to:
SELECT statement, referencing the right target tables and columns, setting up the JOIN and using COUNT(*), GROUP BY, ORDER BY, and LIMIT. For those less proficient in SQL, even that basic query construction is a tremendous accelerant.ST_MAKEPOINT() to create a point from a latitude and longitude and ST_CONTAINS() to find geographic areas that contain the specified point. By helping me to choose the right functions and syntax, the LLM can help jump-start spatial analysis for those new to the field.Now I run the query to answer my initial question:
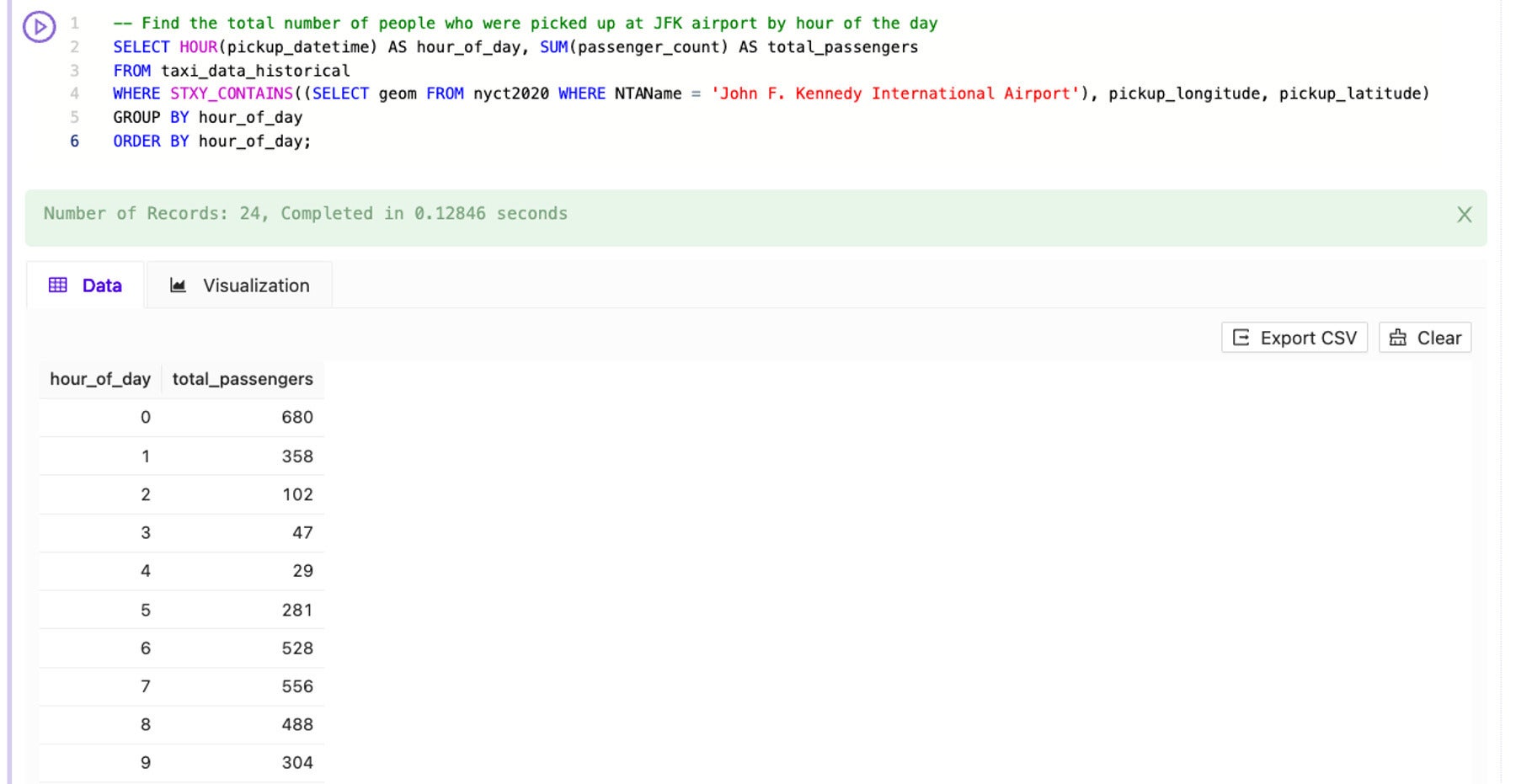
Similarly, if I ask Kinetica SQL-GPT to help me “Find the total number of people who were picked up at JFK airport by hour of the day,” it generates the following SQL:
-- Find the total number of people who were picked up at JFK airport by hour of the day SELECT HOUR(pickup_datetime) AS hour_of_day, SUM(passenger_count) AS total_passengers FROM taxi_data_historical WHERE STXY_CONTAINS((SELECT geom FROM nyct2020 WHERE NTAName = 'John F. Kennedy International Airport'), pickup_longitude, pickup_latitude) GROUP BY hour_of_day ORDER BY hour_of_day;
This query incorporated additional complexity around summing the number of passengers in each taxi and bucketing the data by hour of day. But the LLM handled the complexity and instantly generated proper SQL.
For more sophisticated users, the LLM can also handle more advanced spatiotemporal processing. For instance, in the next example, I would like to analyze a fleet of trucks out for deliveries in the Washington DC area and I want to understand which trucks are currently close to a set of geofences (in this case, buffers around famous DC landmarks).
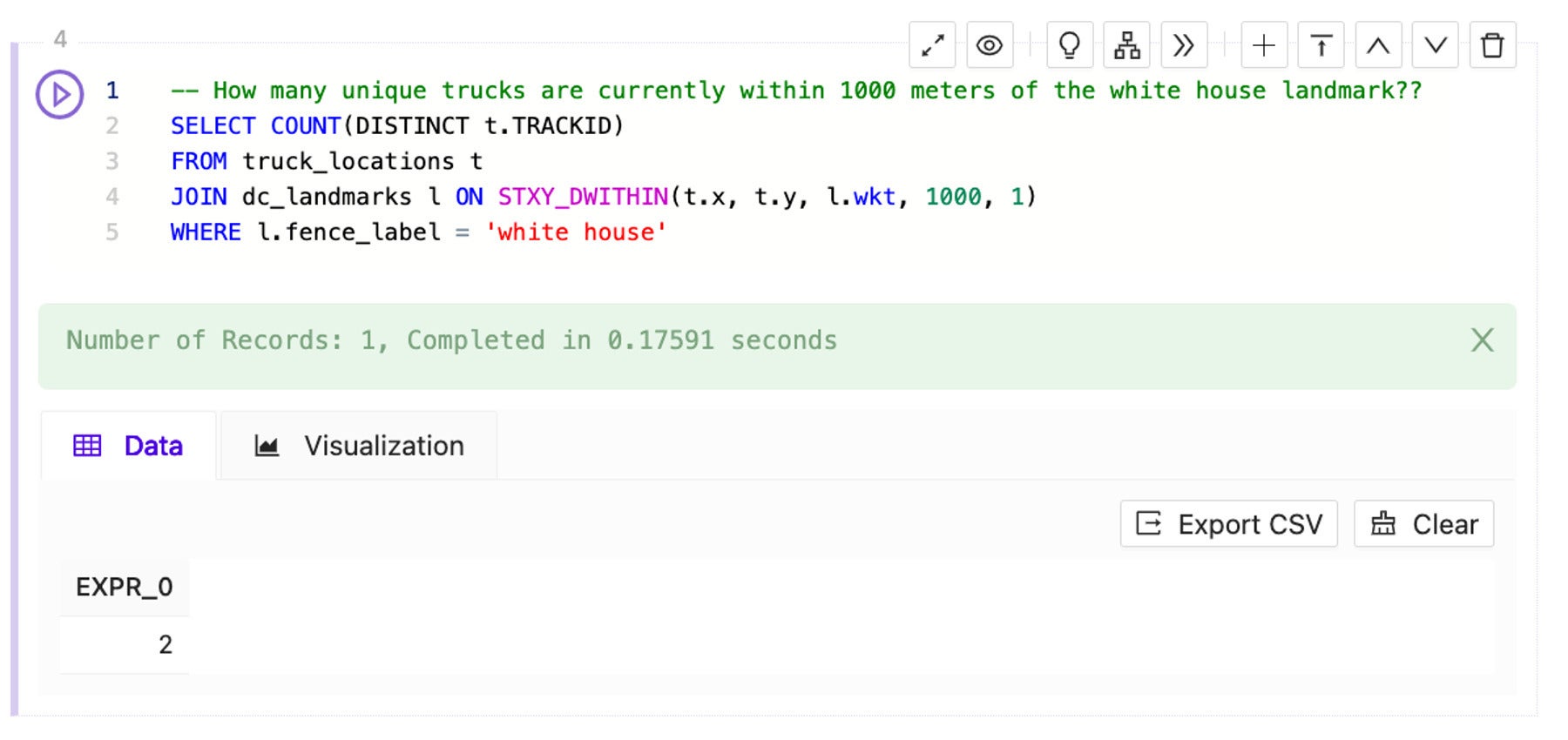
I could start with a basic question around proximity to a specific geofence, such as “How many unique trucks are currently within 1000 meters of the white house landmark?” and use Kinetica SQL-GPT to generate the following SQL:
-- How many unique trucks are currently within 1000 meters of the white house landmark? SELECT COUNT(DISTINCT r.TRACKID) FROM recent_locations r JOIN dc_landmarks d ON STXY_DWITHIN(r.x, r.y, d.wkt, 1000, 1) WHERE d.fence_label = 'white house'
But if I want to have a constantly refreshing view of which trucks are near my geofences, I can get the LLM to help me create a materialized view.
Starting with the prompt “Which trucks came within 200 meters of a landmark in Washington DC in the last 5 mins? Keep all the columns and create a materialized view called landmark_trucks that refreshes every 10 seconds to store the results,” Kinetica SQL-GPT and the LLM are able to generate the SQL to create and refresh the materialized view:
-- Which trucks came within 200 meters of a landmark in Washington DC in the last 5 mins? Keep all the columns and create a materialized view called landmark_trucks that refreshes every 10 seconds to store the results. CREATE OR REPLACE MATERIALIZED VIEW landmark_trucks REFRESH EVERY 10 SECONDS AS SELECT * FROM truck_locations t JOIN dc_landmarks d ON STXY_DWITHIN(t.x, t.y, d.wkt, 200, 1) WHERE t."TIMESTAMP" >= NOW() - INTERVAL '5' MINUTE;
To harness the ever-increasing volume of spatiotemporal data, enterprises will need to modernize their data platforms to handle the scale of analysis and deliver the insights and optimizations their business depends on. Fortunately, recent advancements in GPUs and generative AI are ready to transform the world of spatiotemporal analysis.
GPU accelerated databases dramatically simplify the processing and exploration of spatiotemporal data at scale. With the latest advancements in large language models that are fine-tuned for natural language to SQL, the techniques of spatiotemporal analysis can be democratized further in the organization, beyond the traditional domains of GIS analysts and SQL experts. The rapid innovation in GPUs and generative AI will surely make this an exciting space to watch.
Philip Darringer is vice president of product management for Kinetica, where he guides the development of the company’s real-time, analytic database for time series and spatiotemporal workloads. He has more than 15 years of experience in enterprise product management with a focus on data analytics, machine learning, and location intelligence.
—
Generative AI Insights provides a venue for technology leaders to explore and discuss the challenges and opportunities of generative artificial intelligence. The selection is wide-ranging, from technology deep dives to case studies to expert opinion, but also subjective, based on our judgment of which topics and treatments will best serve InfoWorld’s technically sophisticated audience. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Contact doug_dineley@foundryco.com.
Next read this:





This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →
Copyright 2015 - InnovatePC - All Rights Reserved
Site Design By Digital web avenue