 Alluxio
Alluxio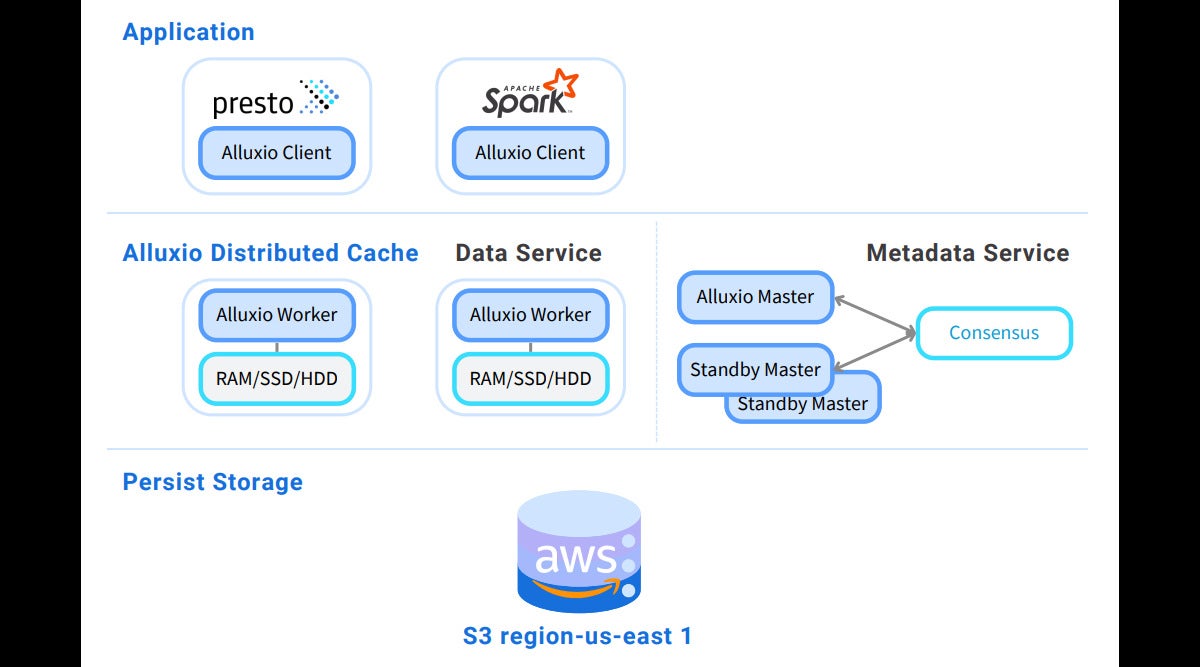 Alluxio
Alluxio IDG
IDG IDG
IDG IDG
IDG IDG
IDG IDG
IDG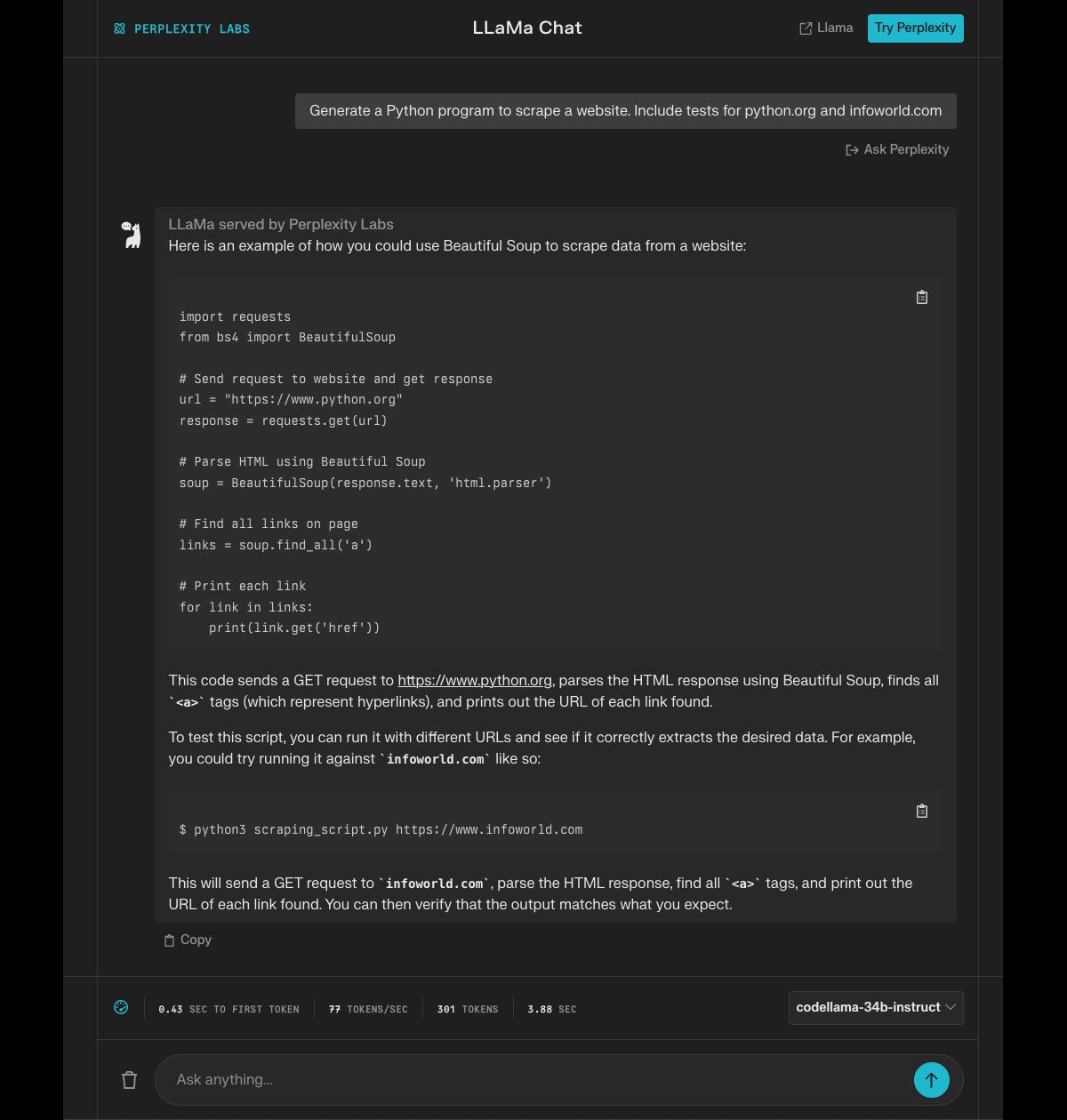 IDG
IDG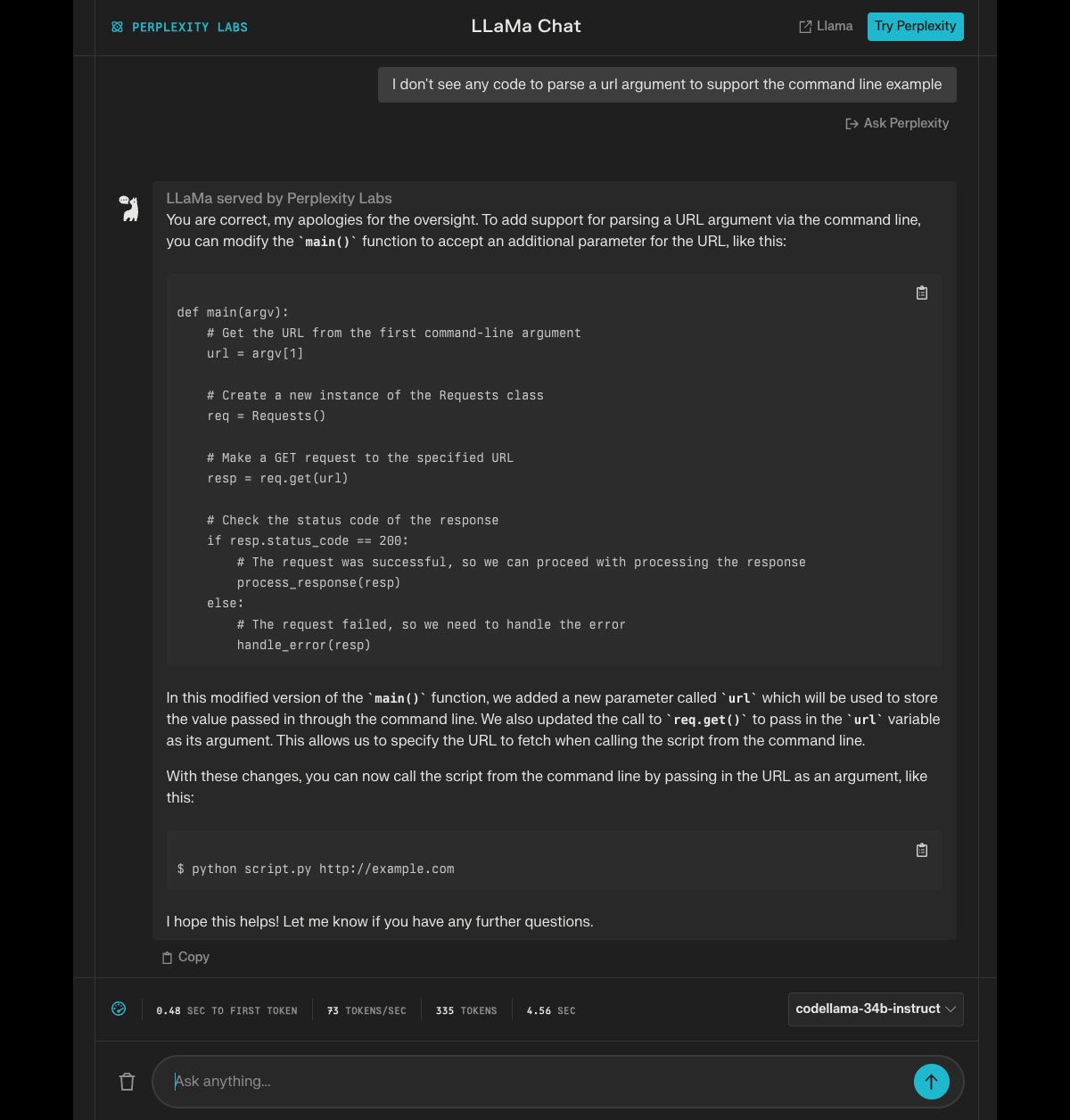 IDG
IDG IDG
IDG
Dell Latitude E6410 Notebook| Quantity Available: 40+
This post is intended for businesses and other organizations interested... Read more →
Posted by Richy George on 27 September, 2023

After adding vector search to its NoSQL Atlas database-as-a-service (DBaaS) in June, MongoDB is adding new generative AI features to a few tools in order to further boost developer productivity.
The new features have been added to MongoDB’s Relational Migrator, Compass, Atlas Charts tools, and its Documentation interface.
In its Documentation interface, MongoDB is adding an AI-powered chatbot that will allow developers to ask questions and receive answers about MongoDB’s products and services, in addition to providing troubleshooting support during software development.
The chatbot inside MongoDB Documentation—which has been made generally available — is an open source project that uses MongoDB Atlas Vector Search for AI-powered information retrieval of curated data to answer questions with context, MongoDB said.
Developers would be able to use the project code to build and deploy their own version of chatbots for a variety of use cases.
In order to accelerate application modernization MongoDB has integrated AI capabilities — such as intelligent data schema and code recommendations — into its Relational Migrator.
The Relational Migration can automatically convert SQL queries and stored procedures in legacy applications to MongoDB Query API syntax, the company said, adding that the automatic conversion feature eliminates the need for developers to have knowledge of MongoDB syntax.
Further, the company is adding a natural language processing capability to MongoDB Compass, which is an interface for querying, aggregating, and analyzing data stored in MongoDB.
The natural language prompt included in Compass has the ability to generate executable MongoDB Query API syntax, the company said.
A similar natural language capability has also been added to MongoDB Atlas Charts, which is a data visualization tool that allows developers to easily create, share, and embed visualizations using data stored in MongoDB Atlas.
“With new AI-powered capabilities, developers can build data visualizations, create graphics, and generate dashboards within MongoDB Atlas Charts using natural language,” the company said in a statement.
The new AI-powered features in MongoBD Relational Migrator, MongoDB Compass, and MongoDB Atlas Charts are currently in preview.
In addition to these updates, the company has also released a new set of capabilities to help developers deploy MongoDB at the edge in order to garner more real-time data and help build AI-powered applications at the edge location.
Dubbed MongoDB Atlas for the Edge, these capabilities will allow enterprises to run applications on MongoDB using a wide variety of infrastructure, including self-managed on-premises servers and edge infrastructure managed by major cloud providers, including Amazon Web Services (AWS), Google Cloud, and Microsoft Azure, the company said.
Next read this:
Posted by Richy George on 26 September, 2023

The serverless database continues to gain traction across the industry, generating a lot of hype along the way. And why not?
The idea that an application developer starting on a new project can provision a database, not worry about sizing compute and storage, or fine-tuning database configurations, and really only needs a general sense of workload pattern and transaction volume to approximate cost is a very enticing proposition. Plus, some might even see very strong potential to reduce the TCO of the database system.
As the theme around cloud cost management continues to percolate, the elastic pay-as-you-go model makes serverless even more attractive—if the app and customers behave.
The serverless database model can be a great solution for unpredictable, spiky workloads. It can even be a fit for predictable, but not constant workloads, e.g., ecommerce on holiday weekends. It’s ideal for the application development team that may not have deep database tuning expertise, or may not quite understand their app usage patterns yet. Or, for teams that may prioritize availability and performance and care less about control of their database system and aggressive margin optimization.
I do not mean to suggest that serveless is a runaway budget-burning machine. Paying strictly for what you consume has huge potential to keep costs down and avoid waste, but it also requires you to understand how your application behaves and how users interact with it. Huge spikes in workload, especially those that the application should have been more efficient with, can also be very costly. You’re paying for what you use, but you may not always use what you expected to.
As you consider a serverless database option, you will also want to consider where your organization or company policy lies in a shared responsibility model. For example, serverless is not going to be entirely suitable for highly regulated workloads with strong governance policies over database configuration changes.
To really reap the benefits of a serverless database means accepting that you are relinquishing even more control of your database to the provider than you would with even a traditional database-as-a-service (DBaaS) solution, which those highly regulated industries would not necessarily accommodate without the same strict governance policies they have in place today.
Serverless is not just about scaling system resources instantaneously. It’s also about ensuring the database is properly tuned for the type of workloads it is processing to honor those guarantees to the customer, while also optimizing utilization rates of the system resources it is consuming.
While the consumer may not have to worry about managing the cost of cloud infrastructure in a serverless model, the provider still does, and it is in their best interest to ensure that the database system is optimally tuned for their customer’s workloads, and that the underlying systems are at optimal utilization rates.
It also means the provider is going to leverage multi-tenancy models wherever possible to pack as many database clusters on their servers as possible. This maximizes utilization rates and optimizes margins—for the provider. In a multi-tenant architecture, you must be sure that your provider will have the level of predictability in your workload, along with any number of other customers on those same servers. This would ensure there’s enough idle resources available to meet any increases in workload, especially the unpredictable ones.
Ultimately, serverless databases are a great technology, but one that is still in its infancy and that presents challenges for both the consumer and the provider. A serverless database should not be viewed as the end all be all. It is a very powerful option that app teams should consider when selecting their database solutions among numerous other options.
Jozef de Vries is chief product engineering officer at EDB.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
Next read this:
Posted by Richy George on 22 September, 2023

In line with Oracle co-founder CTO Larry Ellison’s notion that generative AI is one of the most important technological innovations ever, the company at its annual CloudWorld conference released a range of products and updates centered around the next generation of artificial intelligence.
The last few months have witnessed rival technology vendors, such as AWS, Google, Microsoft, Salesforce and IBM, adopting a similar strategy, under which each of them integrated generative AI into their offerings or released new offerings to support generative AI use cases.
Oracle, which posted its first quarter earnings for fiscal year 2024 last week, has been betting heavily on high demand from enterprises, driven by generative AI related workloads, to boost revenue in upcoming quarters as enterprises look to adopt the technology for productivity and efficiency.
In order to cater to this demand, the company has introduced products based on its three-tier generative AI strategy. Here are some key takeaways:
Oracle has taken the covers off its new API-led generative AI service, which is a managed service that will allow enterprises to integrate large language model (LLM) interfaces in their applications via an API. The API-led service is also designed in a manner that allows enterprises to refine Cohere’s LLMs using their own data to enable more accurate results via a process dubbed Retrieval Augmented Generation (RAG).
It has also updated several AI-based offerings, including the Oracle Digital Assistant, OCI Language Healthcare NLP, OCI Language Document Translation, OCI Vision, OCI Speech, and OCI Data Science.
Oracle is updating its Database 23c offering with a bundle of features dubbed AI Vector Search. These features and capabilities include a new vector data type, vector indexes, and vector search SQL operators that enable the Oracle Database to store the semantic content of documents, images, and other unstructured data as vectors, and use these to run fast similarity queries.
The addition of vector search capabilities to Database 23c will allow enterprises to add an LLM-based natural language interface inside applications built on the Oracle Database and its Autonomous Database.
Other updates to Oracle’s database offerings include the general availability of Database 23c, the next generation of Exadata Exascale, and updates to its Autonomous Database service and GoldenGate 23c.
In order to allow enterprises to operate its data analytics cloud service, dubbed MySQL HeatWave, the company has added a new Vector Store along with some generative AI features.
The new Vector Store, which is also in private preview, can ingest documents in a variety of formats and store them as embeddings generated via an encoder model in order to process queries faster, the company said, adding that the generative AI features added include a large language model-driven interface that allows enterprise users to interact with different aspects of the service — including searching for different files — in natural language.
Other updates to the service include updates to AutoML and MySQL Autopilot components within the service along with support for JavaScript and a bulk ingest feature.
Nearly all of Oracle’s Fusion Cloud suites — including Cloud Customer Experience (CX), Human Capital Management (HCM), Enterprise Resource Planning (ERP), and Supply Chain Management (SCM) — have been updated with the company’s Oracle Cloud Infrastructure (OCI) generative AI service.
For healthcare providers, Oracle will offer a version of its generative AI-powered assistant, which is based on OCI generative AI service, called Oracle Clinical Digital Assistant.
Oracle has updated several applications within its various Fusion Cloud suites in order to align them toward supporting use cases for its healthcare enterprise customers. These updates, which include changes to multiple applications within ERP, HCM, EPM, and SCM Fusion Clouds, are expected to help healthcare enterprises unify operations and improve patient care.
Oracle also continued to expand its distributed cloud offerings, including Oracle Database@Azure and MySQL HeatWave Lakehouse on AWS.
As part of Database@Azure, the company is collocating its Oracle database hardware (including Oracle Exadata) and software in Microsoft Azure data centers, giving customers direct access to Oracle database services running on Oracle Cloud Infrastructure (OCI) via Azure.
Oracle Alloy, which serves as a cloud infrastructure platform for service providers, integrators, ISVs, and others who want to roll out their own cloud services to customers, has also been made generally available.
Next read this:
Posted by Richy George on 20 September, 2023

Oracle is adding a Vector Store and new generative AI features to its data analytics cloud service MySQL HeatWave, the company said at its annual CloudWorld conference.
MySQL HeatWave combines OLAP (online analytical processing), OLTP (online transaction processing), machine learning, and AI-driven automation in a single MySQL database.
The generative AI features added to the data analytics cloud service include a large language model-driven interface that allows enterprise users to interact with different aspects of the service — including searching for different files — in natural language.
The new Vector Store, which is also in private preview, can ingest documents in a variety of formats and store them as embeddings generated via an encoder model in order to process queries faster, the company said.
“For a given user query, the Vector Store identifies the most similar documents by performing a similarity search over the stored embeddings and the embedded query,” an Oracle spokesperson said. These documents can be later used to augment the prompt given to the LLM-driven interface so that it returns a more contextual answer.
Oracle’s MySQL HeatWave Lakehouse, which was released last year in October, has been updated to support AutoML.
HeatWave’s AutoML, which is a machine learning component or feature within the service, supports training, inference, and explanations on data in object storage in addition to data in the MySQL database, the company said.
Other updates to AutoML include support for text columns, an enhanced recommender system, and a training progress monitor.
Support for text columns, according to the company, will now allow enterprises to run various machine learning tasks — including anomaly detection, forecasting, classification, and regression — on data stored in these columns.
In March, Oracle added several new machine-learning features to MySQL HeatWave including AutoML and MySQL Autopilot.
Oracle’s recommender system — a recommendation engine within AutoML — has also been updated to support wider feedback, including implicit feedback, such as past purchases and browsing history, and explicit feedback, such as ratings and likes, in order to generate more accurate personalized recommendations.
A separate component, dubbed the Training Progress Monitor, has also been added to AutoML in order to allow enterprises to monitor the progress of their models being trained with HeatWave.
Oracle has also updated its MySQL Autopilot component within HeatWave to support automatic indexing.
The new feature, which is currently in limited availability, is targeted at helping enterprises to eliminate the need to create optimal indexes for their OLTP workloads and maintain them as workloads evolve.
“MySQL Autopilot automatically determines the indexes customers should create or drop from their tables to optimize their OLTP throughput, using machine learning to make a prediction based on individual application workloads,” the company said in a statement.
Another feature, dubbed auto compression, has also been added to Autopilot. Auto compression helps enterprises determine the optimal compression algorithm for each column, which improves load, and query performance and reduces cost.
The other updates in Autopilot include adaptive query execution and auto load and unload.
Adaptive query execution, as the name suggests, helps enterprises optimize the execution plan of a query in order to improve performance by using information obtained from the partial execution of the query to adjust data structures and system resources.
Separately, auto load and unload improve performance by automatically loading columns that are in use to HeatWave and unloading columns that are never in use.
“This feature automatically unloads tables that were never or rarely queried. This helps free up memory and reduce costs for customers, without having to manually perform this task,” the company said.
Oracle is also adding support for JavaScript to MySQL HeatWave. This ability, which is currently in limited availability, will allow developers to write stored procedures and functions in JavaScript and later execute them in the data analytics cloud service.
Other updates include JSON acceleration, new analytic operators for migrating more workloads into HeatWave, and a bulk ingest feature into MySQL HeatWave.
The bulk ingest feature adds support for parallel building of index sub-tress while loading data from CSV files. This provides a performance increase in data ingestion, thereby allowing newly loaded data to be queried sooner, the company said.
Next read this:
Posted by Richy George on 20 September, 2023

Oracle is planning to add vector search capabilities to its database offering, dubbed Database 23c, the company announced at its ongoing annual CloudWorld conference.
These capabilities, dubbed AI Vector Search, include a new vector data type, vector indexes, and vector search SQL operators that enable the Oracle Database to store the semantic content of documents, images, and other unstructured data as vectors, and use these to run fast similarity queries, the company said.
AI Vector Search in Database 23c also supports Retrieval Augmented Generation (RAG), which is a generative AI technique that combines large language models (LLMs) and private business data to deliver responses to natural language questions, it added.
The addition of vector search capabilities to the Oracle database offering will allow enterprises to add an LLM-based natural language interface inside applications built on the Oracle Database and Autonomous Database.
The natural language-based interface, according to the company, enables users of the applications to ask questions about their data without having to write any code.
“Autonomous Database takes an open, flexible API approach to integrating LLMs so that developers can select the best LLM from Oracle or third parties to generate SQL queries to respond to these questions,” Oracle said in a statement.
The company said it will also add generative AI capabilities to Oracle Database tools such as APEX and SQL Developer. These enhancements will allow developers to use natural language to generate applications or generate code for SQL queries.
Additionally, a new integrated workflow and process automation capability has been added to APEX that will allow developers to add different functions to applications, such as invoking actions, triggering approvals, and sending emails.
However, Oracle did not announce the pricing and availability details for any of the new capabilities.
Other updates to Oracle’s database offerings include the general availability of Database 23c, the next generation of Exadata Exascale, and updates to its Autonomous Database service and GoldenGate 23c.
The next generation of Oracle’s Exadata Exascale, which is system software for databases, according to the company, lowers the cost of running Exadata for cloud databases for developers using smaller configurations.
Updates to Oracle’s Autonomous Database include Oracle’s Globally Distributed Autonomous Database and Elastic Resource Pools.
While the fully managed Globally Distributed Autonomous Database service helps enterprises simplify the development and deployment of shared or distributed application architectures for mission-critical applications, Elastic Resource Pools is designed to enable enterprises to consolidate database instances without any downtime to reduce cost.
For enterprises using Oracle hardware to run databases, the company has introduced Oracle Database Appliance X10.
“The latest release of this database-optimized engineered system provides enhanced end-to-end automation, and up to 50% more performance than the previous generation,” the company said in a statement.
Next read this:
Posted by Richy George on 19 September, 2023

DataStax on Tuesday said that it was releasing a new JSON API in order to help JavaScript developers leverage its serverless, NoSQL Astra DB as a vector database for their large language model (LLMs), AI assistant, and real-time generative AI projects.
Vector search, or vectorization, especially in the wake of generative AI proliferation, is seen as a key capability by database vendors as it can reduce the time required to train AI models by cutting down the need to structure data — a practice prevalent with current search technologies. In contrast, vector searches can read the required or necessary property attribute of a data point that is being queried.
The addition of the new JSON API will eliminate the need for developers trained in JavaScript to have a deep understanding of Cassandra Query Language (CQL) in order to work with Astra DB as the database is based on Apache Cassandra, the company said.
This means that these developers can continue to write code in the language that they are familiar with, thereby reducing the time required to develop AI-based applications which are in demand presently, it added.
Further, the new API, which can be accessed via DataStax’s open source API gateway, dubbed Stargate, will also provide compatibility with Mongoose — one of the most popular open source object data modeling library for MongoDB.
In October last year, DataStax launched the second version of its open-source data API gateway, dubbed Stargate V2, just months after making its managed Astra Streaming service generally available.
In June this year, the company partnered with Google to bring vector search to Astra DB.
Next read this:
Posted by Richy George on 19 September, 2023
Presto is a popular, open source, distributed SQL engine that enables organizations to run interactive analytic queries on multiple data sources at a large scale. Caching is a typical optimization technique for improving Presto query performance. It provides significant performance and efficiency improvements for Presto platforms.
Caching avoids expensive disk or network trips to refetch data by storing frequently accessed data in memory or on fast local storage, speeding up overall query execution. In this article, we provide a deep dive into Presto’s caching mechanisms and how you can use them to boost query speeds and reduce costs.
Caching provides three key advantages. By implementing caching in Presto, you can:
Overall, caching can boost performance and efficiency of Presto queries, providing significant value and ROI for Presto-based analytics platforms.
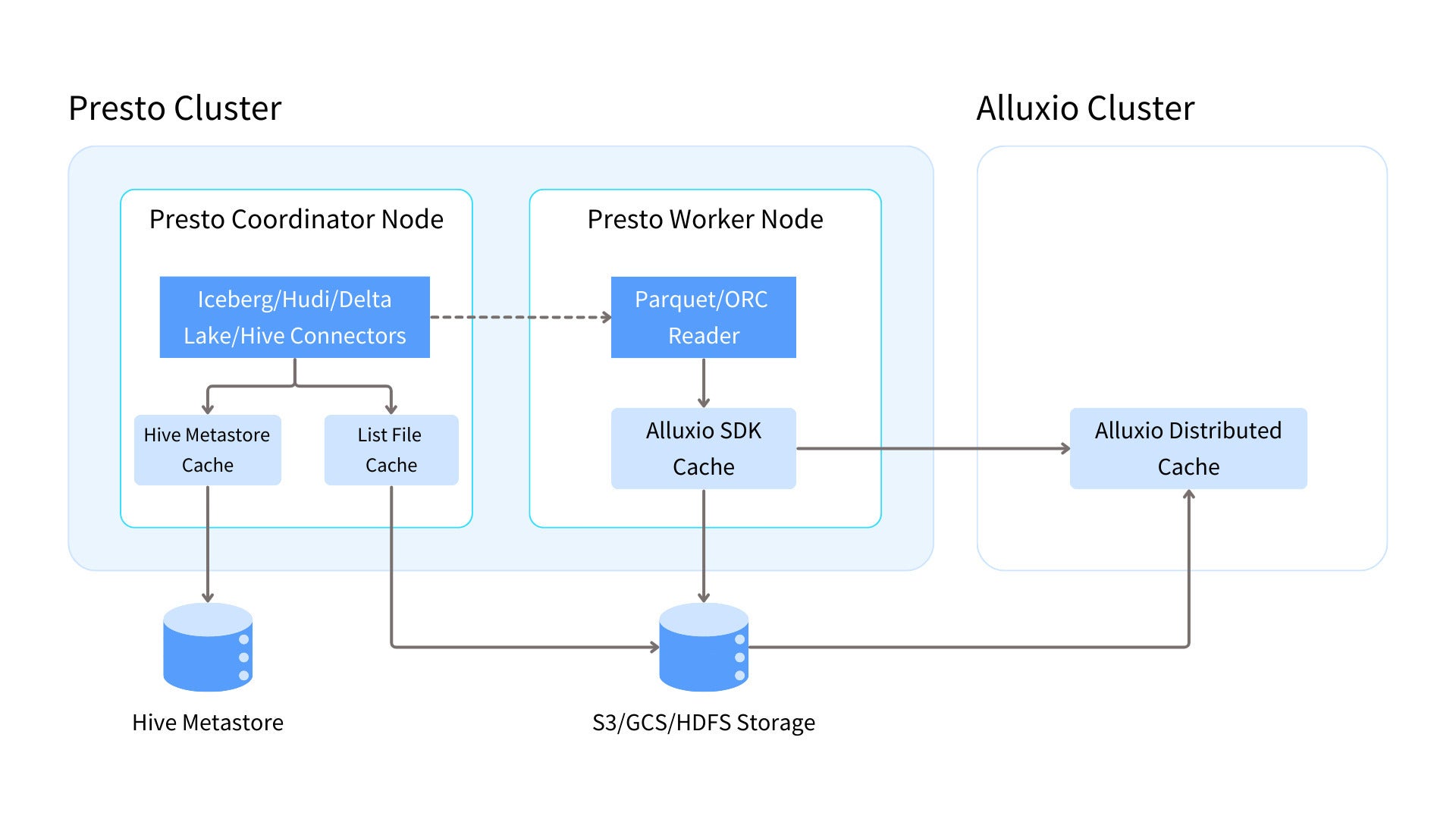
There are two types of caches in Presto, the built-in cache and third-party caches. The built-in cache includes the metastore cache, file list cache, and Alluxio SDK cache. It uses the memory and SSD resources of the Presto cluster, running within the same process as Presto for optimal performance.
The main benefits of built-in caches are very low latency and no network overhead because data is cached locally within the Presto cluster. However, built-in cache capacity is constrained by worker node resources.
Third-party caches, such as the Alluxio distributed cache, are independently deployable and offer better scalability and increased cache capacity. They are particularly advantageous for large-scale analytics workloads, cross-region/cloud deployments, and reducing API and egress costs for cloud storage.
The diagram above and table below summarizes the different cache types, their corresponding resource types, locations.
|
Type of cache |
Cache location |
Resource type |
|
Metastore cache |
Presto coordinator |
Memory |
|
List file cache |
Presto coordinator |
Memory |
|
Alluxio SDK cache |
Presto workers |
Memory/SSD |
|
Alluxio distributed cache |
Alluxio workers |
Memory/SSD/HDD |
None of Presto’s caches are enabled by default. You will need to modify Presto’s configuration to activate them. We will explain the different caching types in more detail and how to enable them via configuration properties in the following sections.
Presto’s metastore cache stores Hive metastore query results in memory for faster access. This reduces planning time and metastore requests.
The metastore cache is highly beneficial when the Hive metastore is overloaded. For large partitioned tables, the cache stores partition metadata locally, enabling faster access and fewer repeated queries. This decreases the overall load on the Hive metastore.
To enable metastore cache, use the following settings:
hive.partition-versioning-enabled=true hive.metastore-cache-scope=ALL hive.metastore-cache-ttl=1d hive.metastore-refresh-interval=1d hive.metastore-cache-maximum-size=10000000
Note that, if tables are frequently updated, you should configure a shorter TTL or refresh interval for the metastore versioned cache. A shorter cache refresh interval ensures only current metadata is stored, reducing the risk of outdated metadata in query execution. This prevents Presto from using stale data.
The list file cache stores file paths and attributes to avoid repeated retrievals from the namenode or object store.
The list file cache substantially improves query latency when the HDFS namenode is overloaded or object stores have poor file listing performance. List file calls can bottleneck HDFS, overwhelming the name node, and increase costs for S3 storage. When the list file status cache is enabled, the Presto coordinator caches file lists in memory for faster access to frequently used data, reducing lengthy remote listFile calls.
To configure list file status caching, use the following settings:
hive.file-status-cache-expire-time=1h hive.file-status-cache-size=10000000 hive.file-status-cache-tables=*
Note that the list file status cache can be applied only to sealed directories, as Presto skips caching open partitions to ensure data freshness.
The Alluxio SDK cache is a Presto built-in cache that reduces table scan latency. Because Presto is a storage-agnostic engine, its performance is often bottlenecked by storage. Caching data locally on Presto worker SSDs enables fast query access and execution. By minimizing repeated network requests, the Alluxio cache also reduces cloud egress fees and storage API costs for remote data.
The Alluxio SDK cache is particularly beneficial for querying remote data like cross-region or hybrid cloud object stores. This significantly decreases query latency and associated cloud storage egress costs and API costs.
Enable the Alluxio SDK cache with the settings below:
cache.enabled=true cache.type=ALLUXIO cache.base-directory=file:///tmp/alluxio cache.alluxio.max-cache-size=100MB
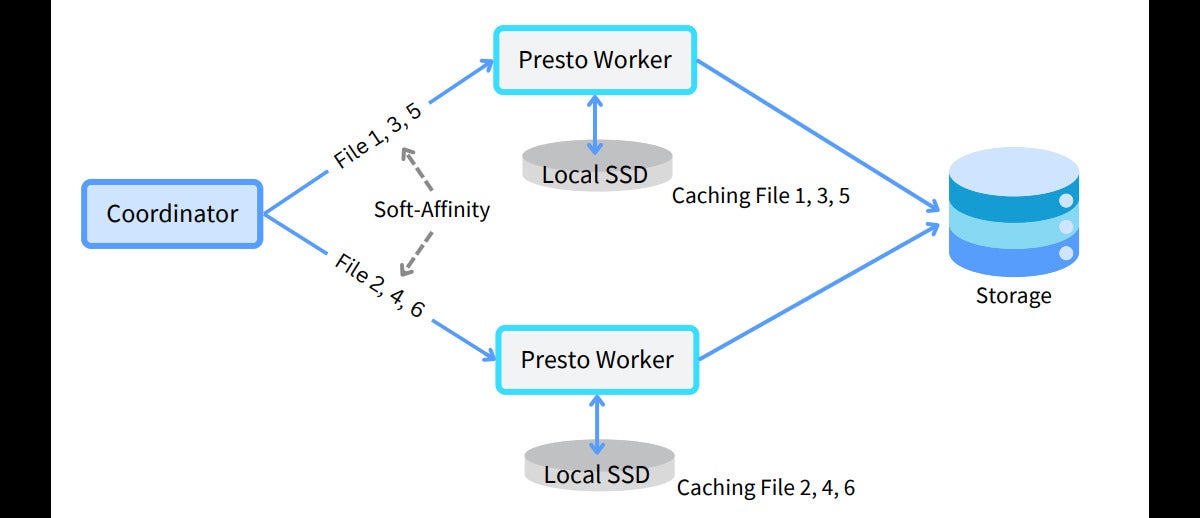
To achieve the best cache hit rate, change the node selection strategy to soft affinity:
hive.node-selection-strategy=SOFT_AFFINITY
The diagram above shows the soft-affinity node selection architecture. Soft-affinity scheduling attempts to send requests to workers based on file paths, maximizing cache hits by locating data in worker caches. Soft affinity is “soft” because it is not a strict rule—if the preferred worker is busy, the split is sent to another available worker rather than waiting.
If you encounter errors such as “Unsupported Under FileSystem,” download the latest Alluxio client JAR from the Maven repository and place it in the {$presto_root_path}/plugin/hive-hadoop2/ directory.
You can view the full documentation here.
If Presto memory or storage is insufficient for large datasets, using a third-party caching solution provides expansive caching for frequent data access. A third-party cache can deliver several optimizations for Presto:
The Alluxio distributed cache is one example of a third-party cache. As you can see in the diagram below, the Alluxio distributed cache is deployed between Presto and storage like S3. Alluxio uses a master-worker architecture where the master manages metadata and workers manage cached data on local storage (memory, SSD, HDD). On a cache hit, the Alluxio worker returns data to the Presto worker. Otherwise, the Alluxio worker retrieves data from persistent storage and caches data for future use. Presto workers process the cached data and the coordinator returns results to the user.
Here are the steps to deploy Alluxio distributed caching with Presto.
In order for Presto to be able to communicate with the Alluxio servers, the Alluxio client jar must be in the classpath of Presto servers. Put the Alluxio client JAR /<PATH_TO_ALLUXIO>/client/alluxio-2.9.3-client.jar into the directory ${PRESTO_HOME}/plugin/hive-hadoop2/ on all Presto servers. Restart the Presto workers and coordinator using the command below:
$ ${PRESTO_HOME}/bin/launcher restart
You can add Alluxio’s properties to the HDFS configuration files such as core-site.xml and hdfs-site.xml, and then use the Presto property hive.config.resources in the file ${PRESTO_HOME}/etc/catalog/hive.properties to point to the locations of HDFS configuration files on every Presto worker.
hive.config.resources=/<PATH_TO_CONF>/core-site.xml,/<PATH_TO_CONF>/hdfs-site.xml
Then, add the property to the HDFS core-site.xml configuration, which is linked by hive.config.resources in Presto’s property.
<configuration> <property> <name>alluxio.master.rpc.addresses</name> <value>master_hostname_1:19998,master_hostname_2:19998,master_hostname_3:19998</value> </property> </configuration>
Based on the configuration above, Presto is able to locate the Alluxio cluster and forward the data access to it.
To learn more about Alluxio distributed cache for Presto, follow this documentation.
Caching is a powerful way to improve Presto query performance. In this article, we have introduced different caching mechanisms in Presto, including the metastore cache, the list file status cache, the Alluxio SDK cache, and the Alluxio distributed cache. As summarized in the table below, you can use these caches to accelerate data access based on your use case.
|
Type of cache |
When to use |
|
Metastore cache |
Slow planning time |
|
List file status cache |
Overloaded HDFS namenode |
|
Alluxio SDK cache |
Slow or unstable external storage |
|
Alluxio distributed cache |
Cross-region, multicloud, hybrid cloud |
The Presto and Alluxio open-source communities work continuously to improve the existing caching features and to develop new capabilities to enhance query speeds, optimize efficiency, and improve the system’s scalability and reliability.
References:
Beinan Wang is senior staff engineer at Alluxio. He has 15 years of experience in performance optimization and large-scale data processing. He is a PrestoDB committer and contributes to the Trino project. He previously led Twitter’s Presto team. Beinen earned his Ph.D. in computer engineering from Syracuse University, specializing in distributed systems.
Hope Wang is developer advocate at Alluxio. She has a decade of experience in data, AI, and cloud. An open source contributor to Presto, Trino, and Alluxio, she also holds AWS Certified Solutions Architect – Professional status. Hope earned a BS in computer science, a BA in economics, and an MEng in software engineering from Peking University and an MBA from USC.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
Next read this:
Posted by Richy George on 18 September, 2023

Citing privacy and security concerns over public large language models, Kinetica is adding a self-developed LLM for generating SQL queries from natural language prompts to its relational database for online analytical processing (OLAP) and real-time analytics.
The company, which derives more than half of its revenue from US defense organizations such as NORAD and the Air Force, claims that the native LLM is more secure, tailored to the database management system syntax, and is contained within the customer’s network perimeter.
With the release of its LLM, Kinetica joins the ranks of all the major LLM or generative AI services providers — including IBM, AWS, Oracle, Microsoft, Google, and Salesforce — that claim that they keep enterprise data to within their respective containers or servers. These providers also claim that customer data is not used to train any large language model.
In May, Kinetica, which offers its database in multiple flavors including hosted, SaaS and on-premises, had said that it would integrate OpenAI’s ChatGPT to let developers use natural language processing to do SQL queries.
Further, the company said that it was working to add more LLMs to its database offerings, including Nvidia’s NeMo model.
The new LLM from Kinetica also gives enterprise users the capability to handle other tasks such as querying time-series graph and spatial queries for better decision making, the company said in a statement.
The native LLM is immediately available to customers in a containerized, secure environment either on-premises or in the cloud without any additional cost, it added.
Next read this:
Posted by Richy George on 14 September, 2023

Today, the PostgreSQL Global Development Group shared the release of PostgreSQL 16. With this latest update, Postgres sets new standards for database management, data replication, system monitoring, and performance optimization, marking a significant milestone for the community, developers, and EDB as the leading contributor to PostgreSQL code.
With PostgreSQL 16 comes a plethora of new features and enhancements. Let’s take a look at a few of the highlights.
One of the standout changes in PostgreSQL 16 is the overhaul of privilege administration. Previous versions often required a superuser account for many administrative tasks, which could be impractical in larger organizations with multiple administrators. PostgreSQL 16 addresses this issue by allowing users to grant privileges in roles only if they possess the ADMIN OPTION for those roles. This shift empowers administrators to define more specific roles and assign privileges accordingly, streamlining the management of permissions. This change not only enhances security but also simplifies the overall user management experience.
Logical replication has been a flexible solution for data replication and distribution since it was first included with PostgreSQL 10 nearly six years ago, enabling various use cases. There have been enhancements to logical replication in every Postgres release since, and Postgres 16 is no different. This release not only includes necessary under-the-hood improvements for performance and reliability but also the enablement of new and more complex architectures.
With Postgres 16, logical replication from physical replication standbys is now supported. Along with helping reduce the load on the primary, which receives all the writes in the cluster, easier geo-distribution architectures are now possible. The primary might have a replica in another region, which can send data to a third system in that region rather than replicating the data twice from one region to another. The new pg_log_standby_snapshot() function makes this possible.
Other logical replication enhancements include initial table synchronization in binary format, replication without a primary key, and improved security by requiring subscription owners to have SET ROLE permissions on all tables in the replication set or be a superuser.
PostgreSQL 16 doesn’t hold back when it comes to performance improvements. Enhanced query execution capabilities allow for parallel execution of FULL and RIGHT JOINs, as well as the string_agg and array_agg aggregate functions. SELECT DISTINCT queries benefit from incremental sorts, resulting in better performance. The concurrent bulk loading of data using COPY has also seen substantial performance enhancements, with reported improvements of up to 300%.
This release also introduces features like caching RANGE and LIST partition lookups, which help with bulk data loading in partitioned tables and better control of shared buffer usage by VACUUM and ANALYZE, ensuring your database runs more efficiently than ever.
Monitoring PostgreSQL databases has never been more detailed or comprehensive. PostgreSQL 16 introduces the pg_stat_io view, allowing for better insight into the I/O activity of your Postgres system. System-wide IO statistics are now only a query away, allowing you to see read, write, and extend (back-end resizing of data files) activity by different back-end types, such as VACUUM and regular client back ends.
PostgreSQL 16 records statistics on the last sequential and index scans on tables, adds speculative lock information to the pg_locks view, and makes several improvements to wait events that make monitoring of PostgreSQL more comprehensive than ever.
What makes PostgreSQL 16 truly exceptional is its potential to impact not just PostgreSQL users, but the entire industry. EDB’s commitment to the community and customers has culminated in a robust, secure, and user-centric database system that promises innovation and productivity across sectors. That’s why EDB builds enterprise-ready capabilities on top of Postgres in EDB Postgres Advanced Server, with features such as Privilege Analysis and new options for Transparent Data Encryption coming out this November.
Additionally, PostgreSQL 16 debuts on EDB BigAnimal next month. This cloud-ready, enterprise-grade database-as-a-service platform is available to organizations worldwide, enabling them to harness the full power of PostgreSQL 16 in their preferred public cloud environments.
Adam Wright is the product manager of core database, extensions, and backup/restore at EDB.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
Next read this:
Posted by Richy George on 12 September, 2023
A funny thing happened when I was playing with Poe, a chatbot aggregator from Quora. I selected the recently released free almost-open-source Llama 2 70B Chat model from Meta and gave it the prompt “Generate a Python program to scrape a website. Include tests for python.org and infoworld.com.” That’s a shorter version of a prompt I used to test CodeWhisperer, Bard, and Copilot X in June. None of those three models generated a working program.
To my utter surprise, Llama 2 70B Chat aced this test:
The bot went on to suggest some follow-up questions:
Tell me more. Can you explain how the BeautifulSoup library works for parsing HTML content? Are there any other libraries or tools commonly used for web scraping in Python? What are some best practices for web scraping to ensure compliance with website terms of service?
The generated code looked good to me, so I copied it into Visual Studio Code, saved it, and ran it. It ran perfectly:
% /usr/local/bin/python3 /Users/martinheller/Code/Llama/scrapesite.py martinheller@Martins-M1-MBP Code % /usr/local/bin/python3 /Users/martinheller/Code/Llama/scrapesite.py Title: Welcome to Python.org Link: #content Link: #python-network Link: / Link: https://www.python.org/psf/ Link: https://docs.python.org Link: https://pypi.org/ Link: /jobs/ Link: /community-landing/ Link: #top Link: / Link: https://psfmember.org/civicrm/contribute/transact?reset=1&id=2 Link: #site-map Link: # Link: javascript:; Link: javascript:; Link: javascript:; Link: # Link: https://www.facebook.com/pythonlang?fref=ts Link: https://twitter.com/ThePSF Link: /community/irc/ Link: /about/ Link: /about/apps/ Link: /about/quotes/ Link: /about/gettingstarted/ Link: /about/help/ Link: http://brochure.getpython.info/ Link: /downloads/ Link: /downloads/ Link: /downloads/source/ Link: /downloads/windows/ Link: /downloads/macos/ Link: /download/other/ Link: https://docs.python.org/3/license.html Link: /download/alternatives Link: /doc/ …
Comparing the Llama-generated code with the CodeWhisperer-generated code, the major difference is that Llama used the html.parser model for Beautiful Soup, which worked, while CodeWhisperer used the lxml model, which choked.
I also asked Llama 2 70B Chat to explain the same sample program I had given to CodeWhisperer, Bard, and Copilot X. CodeWhisperer doesn’t currently have a chat window, so it doesn’t do code explanations, but Bard did a great job on this task and Copilot X did a good job.
Llama’s explanation (shown above) is as good, or possibly better, than what Bard generated. I don’t completely understand why Llama stopped in item 12, but I suspect that it may have hit a token limit, unless I accidentally hit the “stop” button in Poe and didn’t notice.
For more about Llama 2 in general, including discussion of its potential copyright violations and whether it’s open source or not, see “What is Llama 2? Meta’s large language model explained.”
A couple of days after I finished working with Llama 2, Meta AI released several Code Llama models. A few days after that, at Google Cloud Next 2023, Google announced that they were hosting Code Llama models (among many others) in the new Vertex AI Model Garden. Additionally, Perplexity made one of the Code Llama models available online, along with three sizes of Llama 2 Chat.
So there were several ways to run Code Llama at the time I was writing this article. It’s likely that there will be several more, and several code editor integrations, in the next months.
Poe didn’t host any Code Llama models when I first tried it, but during the course of writing this article Quora added Code Llama 7B, 13B, and 34B to Poe’s repertoire. Unfortunately, all three models gave me the dreaded “Unable to reach Poe” error message, which I interpret to mean that the model’s endpoint is busy or not yet connected. The following day, Poe updated, and running the Code Llama 34B model worked:
As you can see from the screenshot, Code Llama 34B went one better than Llama 2 and generated programs using both Beautiful Soup and Scrapy.
Perplexity is website that hosts a Code Llama model, as well as several other generative AI models from various companies. I tried the Code Llama 34B Instruct model, optimized for multi-turn code generation, on the Python code-generation task for website scraping:
As far as it went, this wasn’t a bad response. I know that the requests.get() method and bs4 with the html.parser engine work for the two sites I suggested for tests, and finding all the links and printing their HREF tags is a good start on processing. A very quick code inspection suggested something obvious was missing, however:
Now this looks more like a command-line utility, but different functionality is now missing. I would have preferred a functional form, but I said “program” rather than “function” when I made the request, so I’ll give the model a pass. On the other hand, the program as it stands will report undefined functions when compiled.
Returning JSON wasn’t really what I had in mind, but for the purposes of testing the model I’ve probably gone far enough.
At Google Cloud Next 2023, Google Cloud announced that new additions to Google Cloud Vertex AI’s Model Garden include Llama 2 and Code Llama from Meta, and published a Colab Enterprise notebook that lets you deploy pre-trained Code Llama models with vLLM with the best available serving throughput.
If you need to use a Llama 2 or Code Llama model for less than a day, you can do so for free, and even run it on a GPU. Use Colab. If you know how, it’s easy. If you don’t, search for “run code llama on colab” and you’ll see a full page of explanations, including lots of YouTube videos and blog posts on the subject. Note that while Colab is free but time-limited and resource-limited, Colab Enterprise costs money but isn’t limited.
If you want to create a website for running LLMs, you can use the same vLLM library as used in the Google Cloud Colab Notebook to set up an API. Ideally, you’ll set it up on a server with a GPU big enough to hold the model you want to use, but that isn’t totally necessary: You can get by with something like a M1 or M2 Macintosh as long as it has enough RAM to run your model. You can also use LangChain for this, at the cost of writing or copying a few lines of code.
If you are using an Arm-based Macintosh as your workstation, you can run Llama models locally as a command-line utility. The invaluable Sharon Machlis explains how to use Ollama; it’s easy, although if you don’t have enough RAM memory for the model it’ll use virtual memory (i.e. SSD or, heaven forfend, spinning disk) and run really slow. (Linux and Windows support is planned for Ollama.)
I tried out Ollama with several models (of the many it supports) on my M1 MacBook Pro, which unfortunately has only 8GB of RAM. I started with my standard Python web-scraping code generation task using Llama 2, apparently one of the smaller models (7B?). The result is similar to what I got from the Llama 2 70B model running on Poe, although not as well-structured. Note that Ollama only downloads the model the first time it needs it.
martinheller@Martins-M1-MBP ~ % ollama run llama2
pulling manifest
pulling 8daa9615cce3... 100% |███████████████| (3.8/3.8 GB, 51 MB/s)
pulling 8c17c2ebb0ea... 100% |██████████████████| (7.0/7.0 kB, 39 MB/s)
pulling 7c23fb36d801... 100% |█████████████████| (4.8/4.8 kB, 5.0 MB/s)
pulling 578a2e81f706... 100% |████████████████████| (95/95 B, 129 kB/s)
pulling e35ab70a78c7... 100% |████████████████████| (90/90 B, 550 kB/s)
pulling 96862bb35d77... 100% |██████████████████| (447/447 B, 2.8 MB/s)
verifying sha256 digest
writing manifest
success
>>> Generate a Python program to scrape a website. Include tests for python.org and infoworld.com
Sure! Here is an example of how you can use the `requests` and `BeautifulSoup` libraries in Python to scrape a website:
```
import requests
from bs4 import BeautifulSoup
# Example website to scrape
url = "https://www.python.org"
# Send a request to the website and get the HTML response
response = requests.get(url)
# Parse the HTML content using Beautiful Soup
soup = BeautifulSoup(response.content, 'html.parser')
# Find the specific information you want to scrape on the website
title = soup.find('h1', class_='main-title').text
print(title) # Output: "Python.org"
# Find all the links on the page
links = soup.find_all('a')
for link in links:
print(link.get('href')) # Output: ["/python", "/docs", "/learn", etc.]
# Test the code with different websites
url2 = "https://www.infoworld.com"
response2 = requests.get(url2)
soup2 = BeautifulSoup(response2.content, 'html.parser')
title2 = soup2.find('h1', class_='main-title').text
print(title2) # Output: "Infoworld"
# Find all the links on the page
links2 = soup2.find_all('a')
for link in links2:
print(link.get('href')) # Output: ["/news", "/features", "/opinions", etc.]
```
This code sends a request to the specified website, parses the HTML content using Beautiful Soup, and then finds specific information on the page (in this case, the title and all the links). You can modify the `url` variable at the top of the script to specify the website you want to scrape.
For example, if you want to scrape the Python documentation, you can set `url = "https://www.python.org/doc/` and then use the same code as before to find the title and links on the page.
To test the code with different websites, you can modify the `url2` variable at the top of the script to specify a different website. For example, you can set `url2 = "https://www.infoworld.com"` to scrape that website, or any other website you want to test.
Note: Make sure you have the necessary permissions and legal rights to scrape a website. Web scraping can be illegal in some cases, so be sure to check the terms of service for the website you're scraping and respect their rules.
With that baseline established, I tried the same prompt using Code Llama. Again, I didn’t specify the model size, but it looks like it is 7B.
martinheller@Martins-M1-MBP ~ % ollama run codellama
pulling manifest
pulling 8268242df6f0... 100% |████████████████████████████████████████████| (3.8/3.8 GB, 50 MB/s)
pulling 2c8743bdc4ad... 100% |███████████████████████████████████████████████| (7.0/7.0 kB, 40 MB/s)
pulling 38fa20ee7daa... 100% |███████████████████████████████████████████████| (4.8/4.8 kB, 28 MB/s)
pulling 578a2e81f706... 100% |█████████████████████████████████████████████████| (95/95 B, 993 kB/s)
pulling 404e21afdc6a... 100% |█████████████████████████████████████████████████| (30/30 B, 187 kB/s)
pulling 86b68a7bb45d... 100% |███████████████████████████████████████████████| (507/507 B, 4.0 MB/s)
verifying sha256 digest
writing manifest
success
>>> Generate a Python program to scrape a website. Include tests for python.org and infoworld.com
To write a Python program that scrapes a website, you will need to use a library such as BeautifulSoup or Scrapy. These libraries allow you to navigate and parse the HTML structure of a webpage, and extract specific data from it.
Here is an example of how you might use BeautifulSoup to scrape the Python website at python.org:
```
import requests
from bs4 import BeautifulSoup
# Send a request to the Python website
url = 'https://www.python.org'
response = requests.get(url)
# Parse the HTML content using Beautiful Soup
soup = BeautifulSoup(response.content, 'html.parser')
# Find all links on the page
links = soup.find_all('a')
# Print each link to the console
for link in links:
print(link.get('href'))
```
To write tests for this program, you can use a testing framework such as unittest or pytest. These frameworks allow you to define test functions that can be run automatically to verify that your code is working correctly.
Here is an example of how you might write tests using the unittest module:
```
import unittest
from bs4 import BeautifulSoup
class TestPythonOrg(unittest.TestCase):
def setUp(self):
# Send a request to the Python website
url = 'https://www.python.org'
response = requests.get(url)
# Parse the HTML content using Beautiful Soup
soup = BeautifulSoup(response.content, 'html.parser')
self.soup = soup
def test_title(self):
title = self.soup.find('title').text
self.assertEqual(title, 'Python Documentation - Python v3.10')
def test_description(self):
description = self.soup.find('meta', {'name': 'description'})['content']
self.assertIn('The official homepage for the Python Programming Language', description)
def tearDown(self):
pass
if __name__ == '__main__':
unittest.main()
```
This test program sends a request to the Python website, parses the HTML content using Beautiful Soup, and then runs two separate tests: one that verifies that the page title is correct, and another that verifies that the page description contains certain keywords.
You can run this test program by saving it to a file (e.g. `test_python_org.py`), opening a terminal or command prompt, and then running the following command:
```
python test_python_org.py
```
This will run all of the test functions in the program, and print a message indicating whether each test passed or failed.
Page 2
This model took my request for tests a little more seriously, and demonstrated how to use the Python Unit Test module.
I wondered how different the output of the Python-tuned Code Llama 7B model would be:
martinheller@Martins-M1-MBP ~ % ollama run codellama:7b-python
pulling manifest
pulling 1dd2448f61e7... 100% |████████████████████████████████████████████| (3.8/3.8 GB, 48 MB/s)
pulling 2c8743bdc4ad... 100% |███████████████████████████████████████████████| (7.0/7.0 kB, 52 MB/s)
pulling 38fa20ee7daa... 100% |███████████████████████████████████████████████| (4.8/4.8 kB, 64 MB/s)
pulling b507b9c2f6ca... 100% |██████████████████████████████████████████████████| (13/13 B, 60 kB/s)
pulling 404e21afdc6a... 100% |█████████████████████████████████████████████████| (30/30 B, 240 kB/s)
pulling b413591f8542... 100% |███████████████████████████████████████████████| (507/507 B, 3.2 MB/s)
verifying sha256 digest
writing manifest
success
>>> Generate a Python program to scrape a website. Include tests for python.org and infoworld.com
"""
import urllib.request, html.parser
class Website(object):
"""
Class used to store the data scraped from the website
:param str title: Title of article/page
:param str author: Author of article/page
:param str date: Date that the article was published on
:param str content: Body text of article
"""
def __init__(self, title=None, author=None, date=None, content=None):
self.title = title #title of post/article
self.author = author #author of the post or article
self.date = date #date that the article was published on
self.content = content #the body text of the post/article
class Article(object):
"""
Class used to store data scraped from an infowars article
:param str title: Title of article/page
:param str author: Author of article/page
:param str date: Date that the article was published on
:param str content: Body text of article
"""
def __init__(self, title=None, author=None, date=None, content=None):
self.title = title #title of post/article
self.author = author #author of the post or article
self.date = date #date that the article was published on
self.content = content #the body text of the post/article
def scrape(website_url, htmlparser=html.parser):
"""
Function used to gather all the data from a website and return it in a form for use later
:param str url: The URL of the website you are scraping from
:param object parser: Defaults to the built-in html.parser but can be changed depending on the website's code style
"""
#create website object and assign it to a variable called 'website'
website = Website()
#open url using urlopen function from urllib.request module
with urllib.request.urlopen(website_url) as url:
#use read function to get the contents of the page and store it in a variable called 'content'
content = url.read()
#use decode_content=True argument for html parsing module to be able to parse the url content
parsed_content = htmlparser(markup=content, convert_charrefs=True, decode_entities=False, decode_content=True)
print("n")
#search through content of webpage and find all instances where a tag is used to bold/italicize text in the article body text
title = parsed_content.find("h1", {"class": "entry-title"})
author = parsed_content.find("div", {"class": "author-info"}).text
date = parsed_content.find("span", {"class": "updated"}).text
content = parsed_content.findAll("p")[3].text + 'n' + parsed_content.findAll("p")[4].text + 'n' + parsed_content.findAll("p")[5].text
#store all the data gathered from the website into variables in the 'website' object created earlier
website.title = title.text
website.author = author
website.date = date
website.content = content
return website
All of a sudden, we see Python classes and a function that uses them. This run forgot to generate the unit tests. Let’s try the same prompt and model again and see if we get different output.
martinheller@Martins-M1-MBP ~ % ollama run codellama:7b-python
>>> Generate a Python program to scrape a website. Include tests for python.org and infoworld.com
.
#Python program to scrap data from website#
import requests
from bs4 import BeautifulSoup as soup
url_1 = 'http://python.org/'
reqs_1 = requests.get(url_1)
url_2 = 'https://www.infoworld.com/article/3067955/programming-language/python-the-best-programming-language.html'
reqs_2 = requests.get(url_2)
#HTML parsing from website python.org#
page_1 = reqs_1.text
#HTML parsing from website infoworld.com#
page_2 = reqs_2.text
#BeautifulSoup object for website python.org#
soup_1 = soup(page_1, 'html.parser')
#BeautifulSoup object for website infoworld.com#
soup_2 = soup(page_2,'html.parser')
def scrape():
#Dictionary to store data from both websites python.org and infoworld.com#
website_data = {}
#Scraping all the text from headings of a website#
headlines = soup_1.find_all('div',{'class':'headline'})
for line in headlines:
data = line.text
if "Python" in data or 'Programming' in data:
website_data['headlines'] = [data]
#Scraping all the text from paragraphs of a website#
paragrphs = soup_1.find_all('p')
for line in paragrphs:
data = line.text
if "Python" in data or 'Programming' in data:
website_data['paras'] = [data]
#Scraping all the text from headings of a website#
headlines2 = soup_2.find_all('p')
for line in headlines2:
data = line.text
if "Python" in data or 'Programming' in data:
website_data['headlines'] = [data]
#Scraping all the text from paragraphs of a website#
paragrphs2 = soup_1.find_all('p')
for line in paragrphs2:
data = line.text
if "Python" in data or 'Programming' in data:
website_data['paras'] = [data]
#Return the dictionary of all text scraped from both websites python.org and infoworld.com#
return website_data
This time the model generated code in a functional style instead of an object-oriented style. It did something ugly, though: Instead of using the home page of infoworld.com for its second test, it used the URL of an article about the Python programming language. Alas, that page does not currently exist, so we may have either bumped up against old content in the model, or the model had a hallucination.
As you’ve seen, Llama 2 Chat can generate and explain Python code quite well, right out of the box. There’s no need to fine-tune it further on code-generation tasks—although Meta has done exactly that for Code Llama.
Llama 2 Chat is not without controversy, however. Meta says that it’s open source, but the OSI begs to disagree, on two counts. Meta says that it’s more ethical and safer than other LLMs, but a class action lawsuit from three authors says that its training has violated their copyrights.
It’s nice that Llama 2 Chat works so well. It’s troubling that to train it to work well Meta may have violated copyrights. Perhaps, sooner rather than later, someone will find a way to train generative AIs to be effective without triggering legal problems.
Code Llama’s nine fine-tuned models offer additional capabilities for code generation, and the Python-specific versions seem to know something about Python classes and testing modules as well as about functional Python.
When the bigger Code Llama models are more widely available online running on GPUs, it will be interesting to see how they stack up against Llama 2 70B Chat. It will also be interesting to see how well the smaller Code Llama models perform for code completion when integrated with Visual Studio Code or another code editor.
Next read this:





This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →
Copyright 2015 - InnovatePC - All Rights Reserved
Site Design By Digital web avenue