 IDG
IDG
 IDG
IDG

 IDG
IDG
 IDG
IDG



Dell Latitude E6410 Notebook| Quantity Available: 40+
This post is intended for businesses and other organizations interested... Read more →
Posted by Richy George on 26 March, 2024
Vertex AI Studio is an online environment for building AI apps, featuring Gemini, Google’s own multimodal generative AI model that can work with text, code, audio, images, and video. In addition to Gemini, Vertex AI provides access to more than 40 proprietary models and more than 60 open source models in its Model Garden, for example the proprietary PaLM 2, Imagen, and Codey models from Google Research, open source models like Llama 2 from Meta, and Claude 2 and Claude 3 from Anthropic. Vertex AI also offers pre-trained APIs for speech, natural language, translation, and vision.
Vertex AI supports prompt engineering, hyper-parameter tuning, retrieval-augmented generation (RAG), and model tuning. You can tune foundation models with your own data, using tuning options such as adapter tuning and reinforcement learning from human feedback (RLHF), or perform style and subject tuning for image generation.
Vertex AI Extensions connect models to real-world data and real-time actions. Vertex AI allows you to work with models both in the Google Cloud console and via APIs in Python, Node.js, Java, and Go.
Competitive products include Amazon Bedrock, Azure AI Studio, LangChain/LangSmith, LlamaIndex, Poe, and the ChatGPT GPT Builder. The technical levels, scope, and programming language support of these products vary.
Vertex AI Studio is a Google Cloud console tool for building and testing generative AI models. It allows you to design and test prompts and customize foundation models to meet your application’s needs.
Foundation models are another term for the generative AI models found in Vertex AI. Calling them foundation models emphasizes the fact that they can be customized with your data for the specialized purposes of your application. They can generate text, chat, image, code, video, multimodal data, and embeddings.
Embeddings are vector representations of other data, for example text. Search engines often use vector embeddings, a cosine metric, and a nearest-neighbor algorithm to find text that is relevant (similar) to a query string.
The proprietary Google generative AI models available in Vertex AI include:
Vertex AI Studio allows you to test models using prompt samples. The prompt galleries are organized by the type of model (multimodal, text, vision, or speech) and the task being demonstrated, for example “summarize key insights from a financial report table” (text) or “read the text from this handwritten note image” (multimodal).
Vertex AI also helps you to design and save your own prompts. The types of prompt are broken down by purpose, for example text generation versus code generation and single-shot versus chat. Iterating on your prompts is a surprisingly powerful way of customizing a model to produce the output you want, as we’ll discuss below.
When prompt engineering isn’t enough to coax a model into producing the desired output, and you have a training data set in a suitable format, you can take the next step and tune a foundation model in one of several ways: supervised tuning, RLHF tuning, or distillation. Again, we’ll discuss this in more detail later on in this review.
The Vertex AI Studio speech tool can convert speech to text and text to speech. For text to speech you can choose your preferred voice and control its speed. For speech to text, Vertex AI Studio uses the Chirp model, but has length and file format limits. You can circumvent those by using the Cloud Speech-to-Text Console instead.
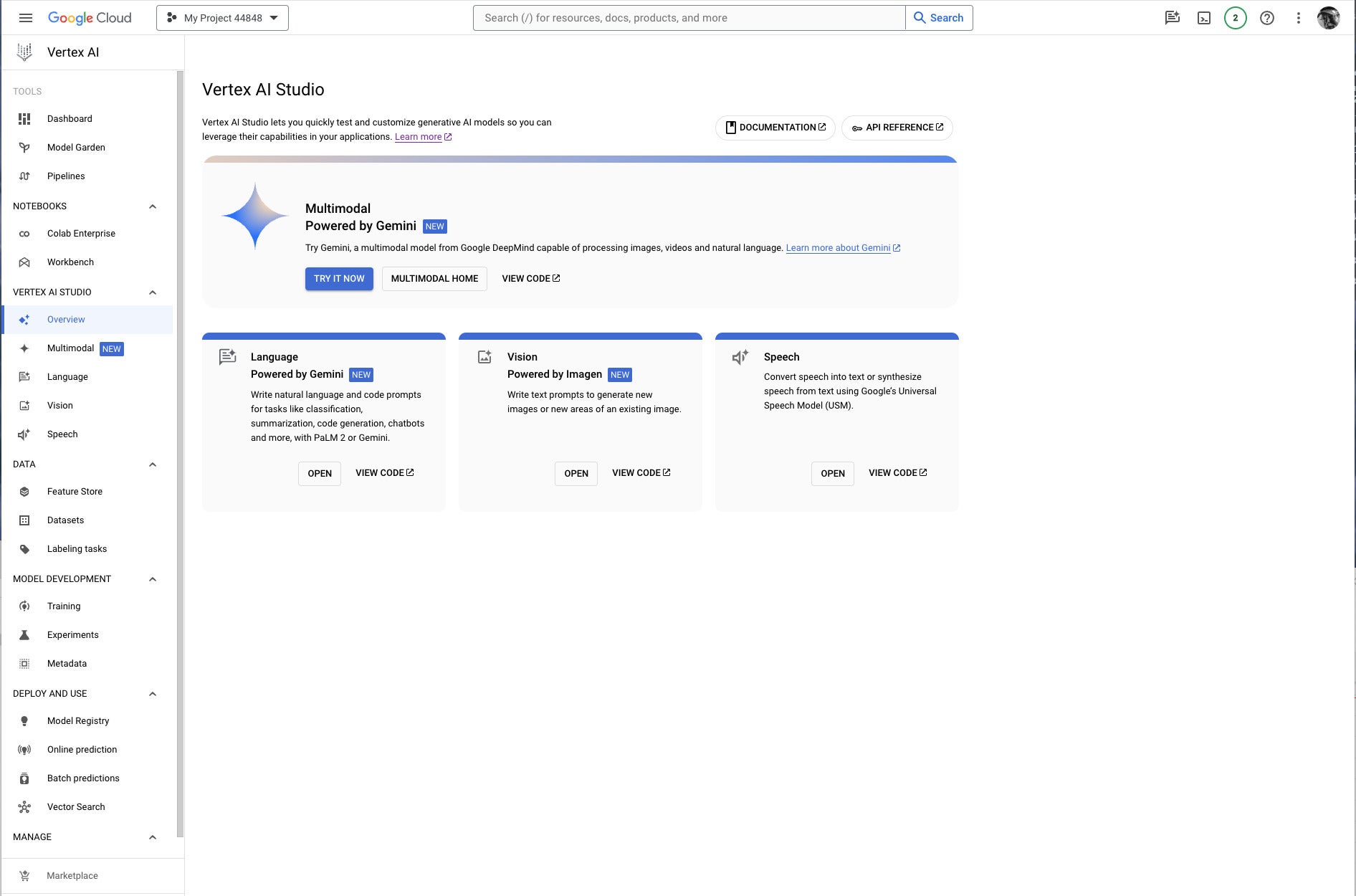
Google Vertex AI Studio overview console, emphasizing Google’s newest proprietary generative AI models. Note the use of Google Gemini for multimodal AI, PaLM2 or Gemini for language AI, Imagen for vision (image generation and infill), and the Universal Speech Model for speech recognition and synthesis.
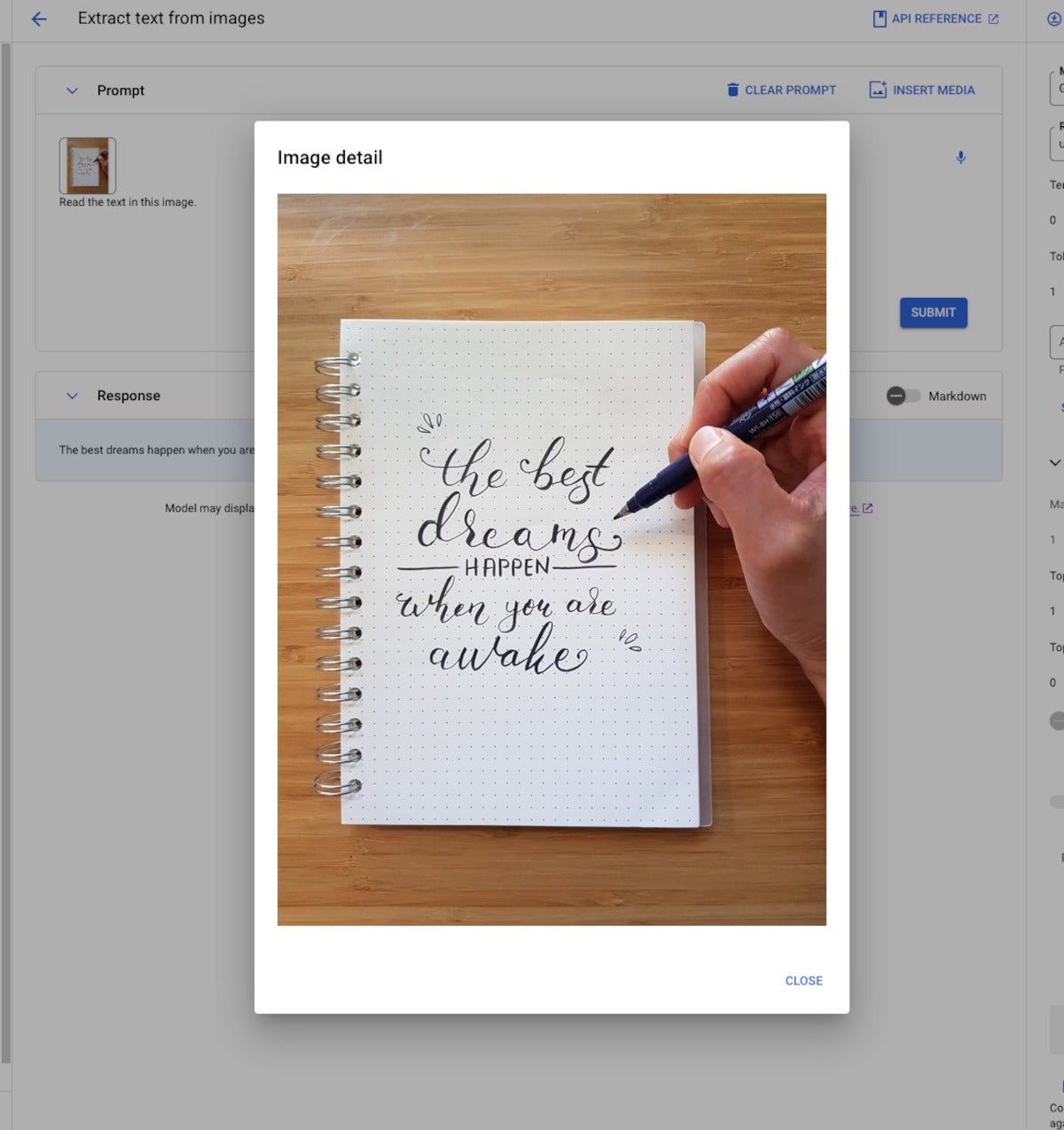
Multimodal generative AI demonstration from Vertex AI. The model, Gemini Pro Vision, is able to read the message from the image despite the elaborate calligraphy.
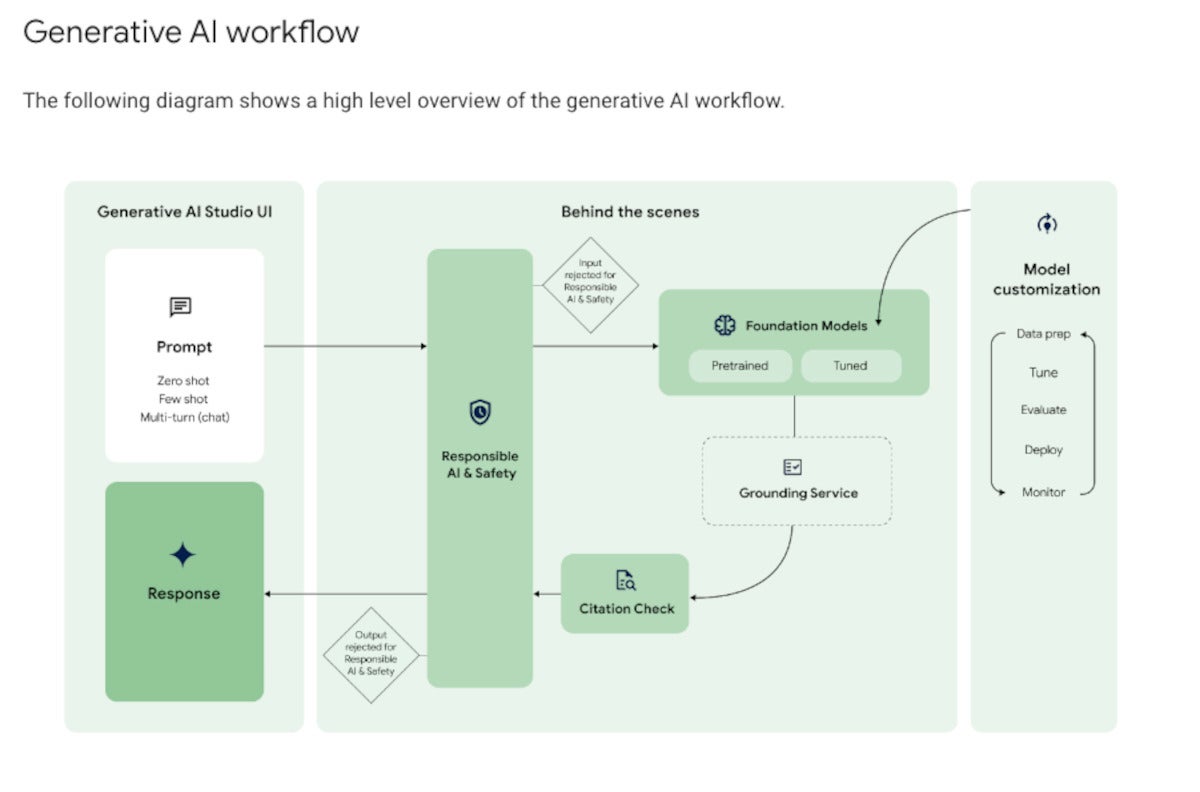
As you can see in the diagram below, Google Vertex AI’s generative AI workflow is a bit more complicated than simply throwing a prompt over the wall and getting a response back. Google’s responsible AI and safety filter applies both to the input and output, shielding the model from malicious prompts and the user from malicious responses.
The foundation model that processes the query can be pre-trained or tuned. Model tuning, if desired, can be performed using several methods, all of which are out-of-band for the query/response workflow and quite time-consuming.
If grounding is required, it’s applied here. The diagram shows the grounding service after the model in the flow; that’s not exactly how RAG works, as I explained in January. Out-of-band, you build your vector database. In-band, you generate an embedding vector for the query, use it to perform a similarity search against the vector database, and finally you include what you’ve retrieved from the vector database as an augmentation to the original query and pass it to the model.
At this point, the model generates answers, possibly based on multiple documents. The workflow allows for the inclusion of citations before sending the response back to the user through the safety filter.
The generative AI workflow typically starts with prompting by the user. On the back end, the prompt passes through a safety filter to pre-trained or tuned foundation models, optionally using a grounding service for RAG. After a citation check, the reply passes back through the safety filter and to the user.
As you might expect from the way RAG works, Vertex AI requires you to take a few steps to enable RAG. First, you need to “onboard to Vertex AI Search and Conversation,” a matter of a few clicks and a few minutes of waiting. Then you need to create an AI Search data store, which can be accomplished by crawling websites, importing data from a BigQuery table, importing data from a Cloud Storage bucket (PDF, HTML, TXT, JSONL, CSV, DOCX, or PPTX formats), or by calling an API.
Finally, you need to set up a prompt with a model that supports RAG (currently only text-bison and chat-bison, both PaLM 2 language models) and configure it to use your AI Search and Conversation data store. If you are using the Vertex AI console, this setup is in the advanced section of the prompt parameters, as shown in the first screenshot below. If you are using the Vertex AI API, this setup is in the groundingConfig section of the parameters:
{
"instances": [
{ "prompt": "PROMPT"}
],
"parameters": {
"temperature": TEMPERATURE,
"maxOutputTokens": MAX_OUTPUT_TOKENS,
"topP": TOP_P,
"topK": TOP_K,
"groundingConfig": {
"sources": [
{
"type": "VERTEX_AI_SEARCH",
"vertexAiSearchDatastore": "VERTEX_AI_SEARCH_DATA_STORE"
}
]
}
}
}
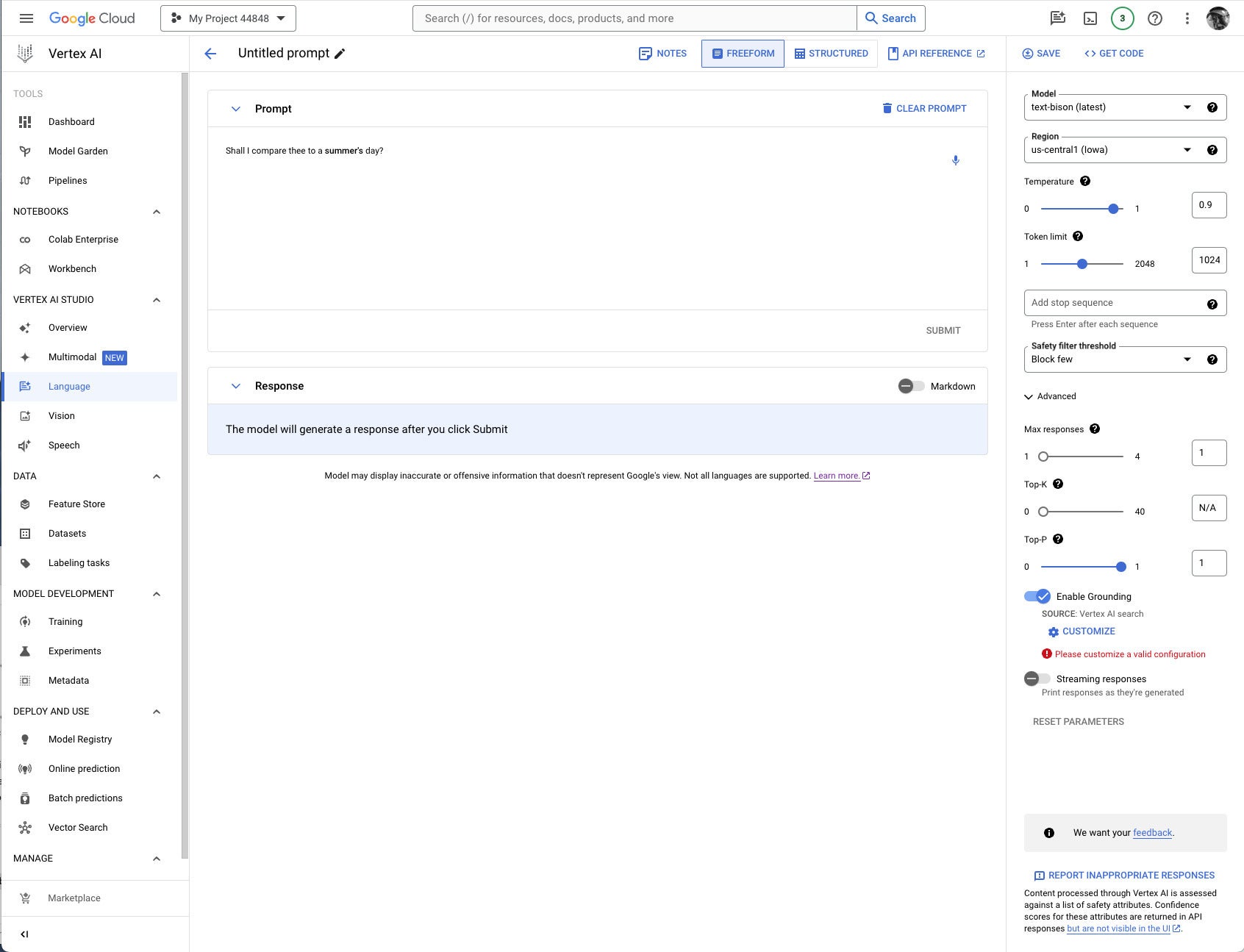
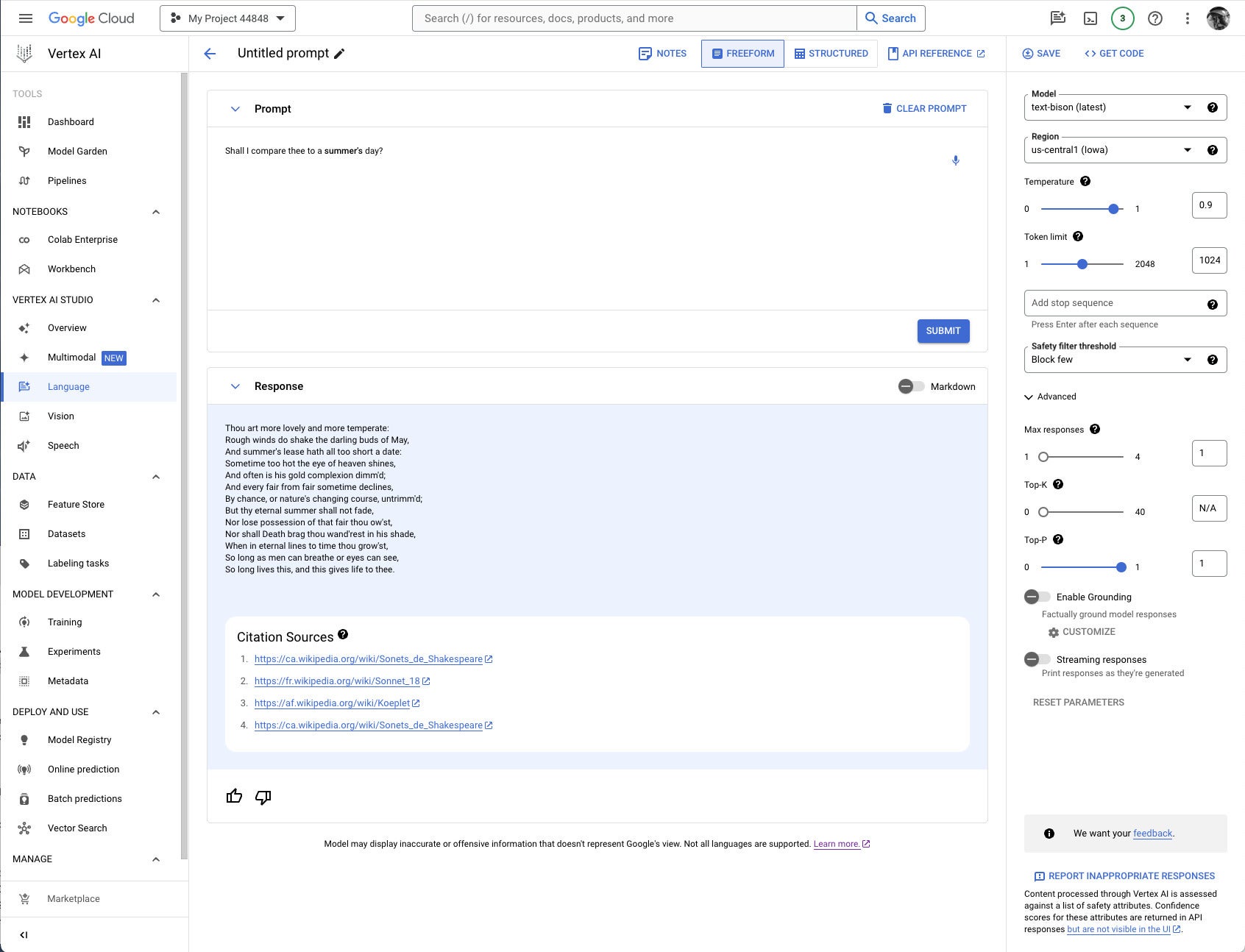
If you’re constructing a prompt for a model that supports grounding, the Enable Grounding toggle at the right, under Advanced, will be enabled, and you can click it, as I have here. Clicking on Customize brings up another right-hand panel where you can select Vertex AI Search from the drop-down list and fill in the path to the Vertex AI data store.
Note that grounding or RAG may or may not be needed, depending on how and when the model was trained.
It’s usually worth checking to see whether you need grounding for any given prompt/model pair. I thought I might need to add the poems section of the Poetry.org site to get a good completion for “Shall I compare thee to a summer’s day?” But as you can see above, the text-bison model already knew the sonnet from four sources it could (and did) cite.
Google’s proprietary models offer some of the added value of the Vertex AI site. Gemini was unique in being a multimodal model (as well as a text and code generation model) as recently as a few weeks before I wrote this. Then OpenAI GPT-4 incorporated DALL-E, which allowed it to generate text or images. Currently, Gemini can generate text from images and videos, but GPT-4/DALL-E can’t.
Gemini versions currently offered on Vertex AI include Gemini Pro, a language model with “the best performing Gemini model with features for a wide range of tasks;” Gemini Pro Vision, a multimodal model “created from the ground up to be multimodal (text, images, videos) and to scale across a wide range of tasks;” and Gemma, “open checkpoint variants of Google DeepMind’s Gemini model suited for a variety of text generation tasks.”
Additional Gemini versions have been announced: Gemini 1.0 Ultra, Gemini Nano (to run on devices), and Gemini 1.5 Pro, a mixture-of-experts (MoE) mid-size multimodal model, optimized for scaling across a wide range of tasks, that performs at a similar level to Gemini 1.0 Ultra. According to Demis Hassabis, CEO and co-founder of Google DeepMind, Gemini 1.5 Pro comes with a standard 128,000 token context window, but a limited group of customers can try it with a context window of up to 1 million tokens via Vertex AI in private preview.
Imagen 2 is a text-to-image diffusion model from Google Brain Research that Google says has “an unprecedented degree of photorealism and a deep level of language understanding.” It’s competitive with DALL-E 3, Midjourney 6, and Adobe Firefly 2, among others.
Chirp is a version of a Universal Speech Model that has over 2B parameters and can transcribe in over 100 languages in a single model. It can turn audio speech to formatted text, caption videos for subtitles, and transcribe audio content for entity extraction and content classification.
Codey exists in versions for code completion (code-gecko), code generation (̉code-bison), and code chat (codechat-bison). The Codey APIs support the Go, GoogleSQL, Java, JavaScript, Python, and TypeScript languages, and Google Cloud CLI, Kubernetes Resource Model (KRM), and Terraform infrastructure as code. Codey competes with GitHub Copilot, StarCoder 2, CodeLlama, LocalLlama, DeepSeekCoder, CodeT5+, CodeBERT, CodeWhisperer, Bard, and various other LLMs that have been fine-tuned on code such as OpenAI Codex, Tabnine, and ChatGPTCoding.
PaLM 2 exists in versions for text (text-bison and text-unicorn), chat (̉chat-bison), and security-specific tasks (sec-palm, currently only available by invitation). PaLM 2 text-bison is good for summarization, question answering, classification, sentiment analysis, and entity extraction. PaLM 2 chat-bison is fine-tuned to conduct natural conversation, for example to perform customer service and technical support or serve as a conversational assistant for websites. PaLM 2 text-unicorn, the largest model in the PaLM family, excels at complex tasks such as coding and chain-of-thought (CoT).
Google also provides embedding models for text (textembedding-gecko and textembedding-gecko-multilingual) and multimodal (multimodalembedding). Embeddings plus a vector database (Vertex AI Search) allow you to implement semantic or similarity search and RAG, as described above.
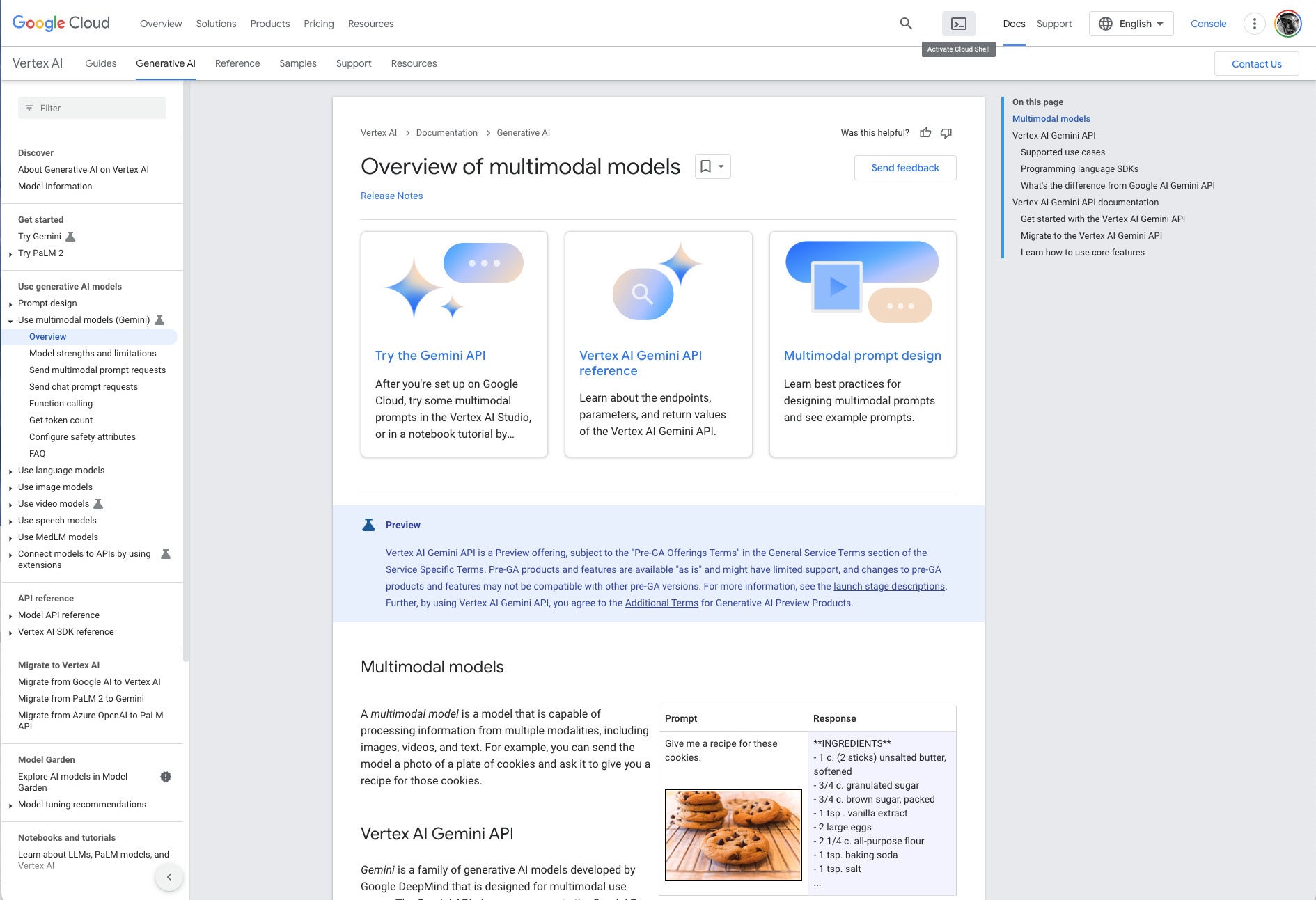
Vertex AI documentation overview of multimodal models. Note the example at the lower right. The text prompt “Give me a recipe for these cookies” and an unlabeled picture of chocolate-chip cookies causes Gemini to respond with an actual recipe for chocolate-chip cookies.
In addition to Google’s proprietary models, the Model Garden (documentation) currently offers roughly 90 open-source models and 38 task-specific solutions. In general, the models have model cards. The Google models are available through Vertex AI APIs and Google Colab as well as in the Vertex AI console. The APIs are billed on a usage basis.
The other models are typically available in Colab Enterprise and can be deployed as an endpoint. Note that endpoints are deployed on serious instances with accelerators (for example 96 CPUs and 8 GPUs), and therefore accrue significant charges as long as they are deployed.
Foundation models offered include Claude 3 Opus (coming soon), Claude 3 Sonnet (preview), Claude 3 Haiku (coming soon), Llama 2, and Stable Diffusion v1-5. Fine-tunable models include PyTorch-ZipNeRF for 3D reconstruction, AutoGluon for tabular data, Stable Diffusion LoRA (MediaPipe) for text to image generation, and ̉̉MoViNet Video Action Recognition.
The Google AI prompt design strategies page does a decent and generally vendor-neutral job of explaining how to design prompts for generative AI. It emphasizes clarity, specificity, including examples (few-shot learning), adding contextual information, using prefixes for clarity, letting models complete partial inputs, breaking down complex prompts into simpler components, and experimenting with different parameter values to optimize results.
Let’s look at three examples, one each for multimodal, text, and vision. The multimodal example is interesting because it uses two images and a text question to get an answer.
Page 2
Here the prompt asks the price of what’s shown in the first image. The Gemini Pro Vision model has to match up the fruit in the first image to the second image, and read the hand-written price tag in the second image to come up with the answer, $4 each. The next two screenshots show details of the two images.
The naive reader might think that these are green apples. Nevertheless if you view the next screenshot you’ll see that they are labeled Asian pears.
The fruits here are distinct enough that you aren’t likely to confuse them, even if Asian pears are unfamiliar, and despite the pears having wrappings in this image but not in the previous image.
This text extraction example using the Gemini Pro model asks for a JSON format answer extracted from plain text, and offers a one-shot example for guidance in the middle Examples pane. The inferred result in the Test pane is correct.
Because I’m rather bloody-minded when I test, I used an image of my own, my back yard after a snowstorm. OK, it looks like my neighbor’s garage was misidentified as a house, but the first generated caption isn’t bad.
It’s almost always worthwhile to try prompt engineering first, but if that fails, the next step to customize a base model for your own purposes is model tuning. The Google AI guidance on model tuning and model tuning with AI Studio is very good, and to the point.
Currently Vertex AI only supports supervised fine-tuning of two text foundation models, Gemini 1.0 Pro and text-bison-001. While you can sometimes get by with as few as 20 examples when you’re doing supervised learning for fine-tuning, the usual recommendations from Google are listed in the table below.
|
Task |
No. of examples in data set |
|
Classification |
100+ |
|
Summarization |
100-500+ |
|
Document search |
100+ |
—
If you’d like to try out fine-tuning for free, you can run it in Colab using this Python Quickstart.
There are two supported methods for fine-tuning text models in AI Studio, supervised tuning and RLHF tuning. Google recommends supervised tuning for classification, sentiment analysis, entity extraction, summarization of content that’s not complex, and domain-specific queries. Google recommends RLHF tuning for question answering, summarization of complex content, and content creation. However, supervised tuning is the only option for code models.
You can also tune embedding models and create distilled text models. Distilled text models use a large, capable teacher model and a labeled or an unlabeled training data set to train a smaller but more accurate student model.
If all of the above fails, your next step might be continued pre-training. The good news about that is that it uses unlabeled data. The bad news is that it requires lots of exemplars, takes days to run, and can be quite expensive.
Overall, Vertex AI Studio is a promising product that could potentially compete strongly with Amazon Bedrock and Azure AI Studio. On the other hand, Google has been busy shooting itself in the foot. The company mismanaged its Gemini Image rollout to the point where co-founder Sergey Brin returned from wherever he has been hiding to say “We definitely messed up on the image generation.” I won’t repeat my rant about Google’s history of eating its young from my review of Project IDX, but you can read it at the end of that article.
There are lots of good things about Vertex AI Studio, including its use of Google’s own models, its rapid adoption and deployment of new models from other vendors, and its straightforward support for RAG and model tuning. Meanwhile, why are the Generative AI Extensions—potentially the most useful facility of Vertex AI Studio, and the piece that competes with OpenAI GPTs—buried in a private preview?
As far as which AI app building platform you should choose, if you’re already heavily invested in the Google Cloud, then using Google Vertex AI Studio for building AI apps is probably a no-brainer, as long as you can get access to all the models and capabilities that you need, rather than be told that you can’t have them because they are in private preview.
Given Google’s investment in its cloud platform, I don’t seriously expect Vertex AI Studio to be killed outright in the next couple of years, but I wouldn’t be at all surprised by yet another rebranding.
—
Cost: Cost is based on usage. See https://cloud.google.com/vertex-ai/pricing#generative_ai_models.
Platform: Google Cloud Platform.
Next read this:
Posted by Richy George on 25 March, 2024

Starting with Redis 7.4, all future versions of Redis software will be dual-licensed under the Redis Source Available License (RSAL 2) and the Server Side Public License (SSLPv1), Redis announced. The popular NoSQL database will no longer be distributed under the three-clause Berkeley Software Distribution (BSD) license.
New source-available licenses will allow Redis the company to provide permissive use of its source code, the company said on March 20. Source code will continue to be freely available to developers, customers, and partners through Redis Community Edition.
Future Redis source-available licenses will unify core Redis with Redis Stack, including search, JSON, vector, probabilistic, and time-series data models in one package as downloadable software. This will allow Redis software to be used across a variety of contexts, including key-value and document store, a query engine, and a low-latency vector database powering generative AI applications, the company said.
Redis has faced challenges, the company said. The majority of commercial sales of Redis software are channeled through the largest cloud service providers, who commoditize Redis’s investments and its open source community. Despite efforts to support a community-led governance model and a desire to maintain the BSD license, delivering multiple software distributions simultaneously is at odds with Redis’s ability to drive the technology successfully, the company said.
Under the new licensing, cloud service providers hosting Redis products will no longer be permitted to use Redis source code free of charge. But in practice, nothing changes for the Redis developer community, who will still have permissive licensing under the dual license, Redis said. All Redis client libraries will remain open-source licensed.
RSALv2 is a permissive non-copyleft license, allowing the right to “use, copy, distribute, make available, and prepare derivative works of the software.” RSALv2 has only two primary limitations, the company said: Under RSALv2, users may not commercialize the software or provide it to others as a managed service; and users may not remove or obscure any licensing, copyright, or other notices.
Next read this:
Posted by Richy George on 22 March, 2024

Datacenter and hybrid multi-cloud software provider Nutanix has filed a lawsuit against database-as-a-service (DBaaS) providing startup, Tessell, alleging that its products were built using Nutanix’s source code and other resources.
The lawsuit, more significantly, is targeted at the three co-founders of the San Francisco-headquartered Tessell, including Bala Kuchibhotla, Kamaldeep Khanuja, and Bakul Banthia. The lawsuit alleged that the co-founders developed Tessell products while being employed at Nutanix.
While Kuchibhotla served as the general manager and senior VP of the Era business, Khanuja and Banthia were senior engineers.
“Kuchibhotla used Nutanix facilities, equipment, services, and even the Nutanix Era source code when developing the Tessell product. Kuchibhotla planned, developed, obtained initial financing for, and demonstrated prototypes of the competing product—all using Nutanix computers,” the company alleged in the lawsuit filed with the Northern District Court of California.
“One of the Tessell prototypes they demonstrated actually ran on Nutanix servers,” the company added.
The lawsuit further goes on to say that the theft of intellectual property was discovered after the company carried out a thorough forensic investigation of their internal resources, which was triggered based on suspicions arising post the launch of Tessell’s offerings.
“When Tessell launched its product in late 2022, however, the speed with which it came to market with features strikingly similar to Era caused Nutanix to commence a full-fledged forensic investigation,” the company said.
Nutanix describes its Era offering as software that helps enterprises manage multiple databases in servers located in their data centers or hybrid cloud environments.
Essentially, Era simplifies the processes for managing databases, including creating, populating, backing up, duplicating, and administering databases, the company explained, adding that Era helps enterprises cut down on time, money, and talent significantly.
Tessell’s offerings, which include targeted products for PostgreSQL, MySQL, SQL Server, Milvus, Oracle, MongoDB, and SQL Server, compete with Nutanix Era, which also supports databases such as Oracle, Microsoft SQL Server, MongoDB, MySQL, and PostgreSQL.
The company sees the act of the three founders as a case of intellectual property theft as it believes that all three former employees were contractually bound to disclose and assign “the stolen IP” to Nutanix.
An email query sent to Tessell about the lawsuit received no response.
In a separate statement to the press, Nutanix said that the lawsuit filed against Tessell and its founders also alleges that they schemed to remove all indicia of Nutanix branding from their prototype, and then tried to cover their tracks by wiping their Nutanix laptops.
“Nutanix is seeking the return of its stolen intellectual property, an injunction to stop further infringement, restitution for the Nutanix resources taken by the three former employees for the founding of Tessell, and money damages in an amount to be proven,” the company said.
Further, Nutanix added that it was commencing separate arbitration proceedings against the Tessell founders per their Nutanix employee agreements.
Next read this:
Posted by Richy George on 18 March, 2024
The world has become “sensor-fied.”
Sensors on everything, including cars, factory machinery, turbine engines, and spacecraft, continuously collect data that developers leverage to optimize efficiency and power AI systems. So, it’s no surprise that time series—the type of data these sensors collect—is one of the fastest-growing categories of databases over the past five-plus years.
However, relational databases remain, by far, the most-used type of databases. Vector databases have also seen a surge in usage thanks to the rise of generative AI and large language models (LLMs). With so many options available to organizations, how do they select the right database to serve their business needs?
Here, we’ll examine what makes databases perform differently, key design factors to look for, and when developers should use specialized databases for their apps.
At the outset, it’s important to understand that there is no one-size-fits-all formula that guarantees database superiority. Choosing a database entails carefully balancing trade-offs based on specific requirements and use cases. Understanding their pros and cons is crucial. An excellent starting point for developers is to explore the CAP theorem, which explains the trade-offs between consistency, availability, and partition tolerance.
For example, the emergence of NoSQL databases generated significant buzz around scalability, but that scalability often came at the expense of surrendering guarantees in data consistency offered by traditional relational databases.
Some design considerations that significantly impact database performance include:
These and other factors collectively shape database performance. Strategically manipulating these variables allows teams to tailor databases to meet the organization’s specific performance requirements. Sacrificing certain features becomes viable for a given scenario, creating finely-tuned performance optimization.
Selecting the appropriate database for your application involves weighing several critical factors. There are three major considerations that developers should keep in mind when making a decision.
The primary determinant in choosing a database is understanding how an application’s data will be accessed and utilized. A good place to begin is by classifying workloads as online analytical processing (OLAP) or online transaction processing (OLTP). OLTP workloads, traditionally handled by relational databases, involve processing large numbers of transactions by large numbers of concurrent users. OLAP workloads are focused on analytics and have distinct access patterns compared to OLTP workloads. In addition, whereas OLTP databases work with rows, OLAP queries often involve selective column access for calculations. Data warehouses commonly leverage column-oriented databases for their performance advantages.
The next step is considering factors such as query latency requirements and data write frequency. For near-real-time query needs, particularly for tasks like monitoring, organizations might consider time series databases designed for high write throughput and low-latency query capabilities.
Alternatively, for OLTP workloads, the best choice is typically between relational databases and document databases, depending on the requirements of the data model. Teams should evaluate whether they need the schema flexibility of NoSQL document databases or prefer the consistency guarantees of relational databases.
Finally, a crucial consideration is assessing if a workload exhibits consistent or highly active patterns throughout the day. In this scenario, it’s often best to opt for databases that offer scalable hardware solutions to accommodate fluctuating workloads without incurring downtime or unnecessary hardware costs.
Another consideration when selecting a database is the internal team’s existing expertise. Evaluate whether the benefits of adopting a specialized database justify investing in educating and training the team and whether potential productivity losses will appear during the learning phase. If performance optimization isn’t critical, using the database your team is most familiar with may suffice. However, for performance-critical applications, embracing a new database may be worthwhile despite initial challenges and hiccups.
Maintaining architectural simplicity in software design is always a goal. The benefits of a specialized database should outweigh the additional complexity introduced by integrating a new database component into the system. Adding a new database for a subset of data should be justified by significant and tangible performance gains, especially if the primary database already meets most other requirements.
By carefully evaluating these factors, developers can make educated and informed decisions when selecting a database that aligns with their application’s requirements, team expertise, and architectural considerations, ultimately optimizing performance and efficiency in their software solutions.
IoT environments have distinct characteristics and demands for deploying databases. Specifically, IoT deployments need to ensure seamless operation at both the edge and in the cloud. Here is an overview of database requirements in these two critical contexts.
The edge is where data is locally generated and processed before transmission to the cloud. For this, databases must handle data ingestion, processing, and analytics at a highly efficient level, which requires two things:
In cloud data centers, databases play a crucial role in collecting, transforming, and analyzing data aggregated from edge servers. Key requirements include:
Because the database landscape evolves swiftly, developers must stay informed about the latest trends and technologies. While sticking to familiar databases is reliable, exploring specialized options can offer advantages that include cost savings, enhanced user performance, scalability, and improved developer efficiency.
Ultimately, balancing the organization’s business requirements, storage needs, internal knowledge, and (as always) budget constraints gives teams the best chance for long-term success.
Anais Dotis-Georgiou is lead developer advocate at InfluxData.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
Next read this:
Posted by Richy George on 15 March, 2024
Posted by Richy George on 12 March, 2024
PostgreSQL pioneer Mike Stonebraker and Spark creator Matei Zaharia, along with other computer scientists at MIT and Stanford have come up with a new database-oriented operating system (DBOS) to help development of greenfield web applications.
They have set up a company, DBOS Inc., to make the OS available to developers.
Its first product, DBOS Cloud, launched Tuesday, is a transactional serverless application platform, also sometimes defined as functions-as-a-service (FaaS). It is offered via Amazon Web Services (AWS) using the open-source virtual machine monitoring service Firecracker and is powered by the DBOS operating system.
It consists of three main components: an open source DBOS SDK currently for TypeScript, a DBOS Time Travel Debugger, and the underlying OS.
The company said it will help developers build and run serverless functions, workflows, and applications, adding that it comes with features such as time-travel debugging and SQL-accessible observability data.
But how did Stonebraker, Zaharia and the other researchers come together to build DBOS and what was their rationale?
Over three years ago, Stonebraker told InfoWorld, he identified that the rise in demand for data and compute had thrown up a new challenge for databases—storing operating system states of large magnitude. Around that time he attended a talk by Zaharia, who is also the CTO of Databricks, where he heard the latter “complain” about the performance of PostgreSQL.
The Databricks CTO, according to Stonebraker, was explaining how his company was performing OS scheduling.
“Zaharia said that Databricks is routinely managing a ‘million-ish’ Spark sub tasks on a cloud and there’s no possible way that the company can run at that scale and use traditional OS scheduling techniques. Instead, Zaharia said that Databricks was putting all the scheduling information in a Postgres database, and doing scheduling as a SQL application,” Stonebraker explained.
Stonebraker reached out to the Zaharia soon after, realizing that “there is a whole bunch of commercial companies that can’t use traditional OS capabilities at scale.”
Their discussions led to the birth of DBOS, as the founders decided to run a database management system at the bottom of their new stack, and then run all OS services as equal.
“We built enough of this along with the team to prove that this inverted OS is about as fast as whatever enterprises were using or currently doing. Essentially, this meant that enterprises could get everything in the database with no drop in performance,” Stonebraker said.
As the database logs everything, the team’s next task was to develop a data provenance system that minimizes the use of the Linux-based kernel.
“We have a very sophisticated provenance system that gets spooled into a data warehouse,” Stonebraker said, adding that this allows DBOS to eliminate may layers, such as Linux, Kubernetes, any other transactional file systems, and any high availability delivery system.
The elimination of layers, according to the company, provides benefits in terms of cost, complexity, and reduced attack surface.
“You don’t need containers or orchestration layers, and you write less code because the OS is doing more for you,” Stonebraker explained, adding that it is a simple environment to maintain and keep a watch on abnormal events without compromising speed when compared to existing products.
The other advantage, according to Stonebraker, is the ability for the OS to backup quickly in case of adverse events, such as a ransomware attack.
“In the event of an attack, the system can be backed up to a specific time as it has the entire event log to skirt past around the offensive transaction. The backup takes seconds to minutes in contrast to other offerings where it may take days or weeks,” the founder explained.
After the development of the provenance system, the team built a programming interface for developers with a focus on the cloud rather than on-premises systems.
“We wrote a software-as-a-service (SaaS) programming environment on top of our database system,” Stonebraker said, adding that it was a Typescript-based environment.
It enables developers to write a collection of micro-operations connected into a graph, which are ingested into the database where they will get concurrency control to stop parallel program bugs. It also supports a debugger for applications, he said.
Although the team decided to launch DBOS in the cloud first, that’s not its only target.
“Over time, once we get traction, then we will probably pivot to the enterprise because that’s where large amounts of money are,” Stonebraker said, adding that enterprise software sales cycles are typically “very long.”
To get it to run on-premises, the team will need to add support for the POSIX set of standard interfaces for Unix .
The technical documentation for DBOS to help developers start using it can be found here.
In terms of pricing, DBOS Cloud in its free tier offers a million service calls per month and a system data retention time of 3 days while using Amazon RDS Postgres.
Enterprises or developers can choose to use DBOS Cloud across other databases but will have to raise a request for customization.
While several analysts, including IDC’s Carl Olofson, dbInsight’s Tony Baer and Constellation Research’s Holger Mueller, attest to DBOS’ positive impact on reducing the time taken to develop an application and the security advantages of the platform, they highlight certain drawbacks and concerns.
Mueller wondered whether DBOS the company can scale. “Will a small team at DBOS be able to run an OS, database, observability, workflow and cyber stack as good as the combination of the best of breed vendors?” he asked.
Olfson also pointed out that in this era of specialized database management systems, such as key-value, timeseries, and document, among others, a relational database system might not be able to address all needs.
Explaining further about cybersecurity, Olofson pointed out that though DBOS has good security features, the biggest cause of data theft and loss is the use of false credentials, usually obtained through techniques, such as phishing attacks.
“No DBMS technology can prevent a bad actor with apparently legitimate credentials from stealing or destroying data,” Olofson said.
Next read this:
Posted by Richy George on 11 March, 2024
In the good old days, databases had a relatively simple job: help with the monthly billing, deliver some reports, maybe answer some ad hoc queries. Databases were important, but they weren’t in constant demand.
Today the picture is different. Databases are often tasked with powering business operations and hyperscale online services. The flow of transactions is incessant, and response times need to be near-instantaneous. In this new paradigm, businesses aren’t just informed by their database—they’re fundamentally built on it. Decisions are made, strategies are drafted, and services are personalized in real time based on vast streams of data.
Relational databases sit at the epicenter of this seismic shift. Their role transcends storage. It extends to processing complex transactions, enforcing business logic, and serving real-time analytical insights. The structured nature of relational databases, coupled with the innate ability to ensure the atomicity, consistency, isolation, and durability (ACID) of transactions, makes them indispensable in a world where data forms the core of business strategies.
To meet the demands of modern applications, relational databases need a radically new architecture. The must be designed from the ground up to handle voluminous data and transaction loads, resist different types of failure, and function seamlessly during times of peak demand without manual intervention or patchwork scaling strategies.
This architecture must be intrinsically scalable and reliable. Those two qualities can’t be bolted on. They have to be fundamental to the design. Scalability allows the database to efficiently accommodate fluctuating workloads. Reliability ensures consistent performance, preventing data loss or downtime that could critically impinge business operations or decision-making.
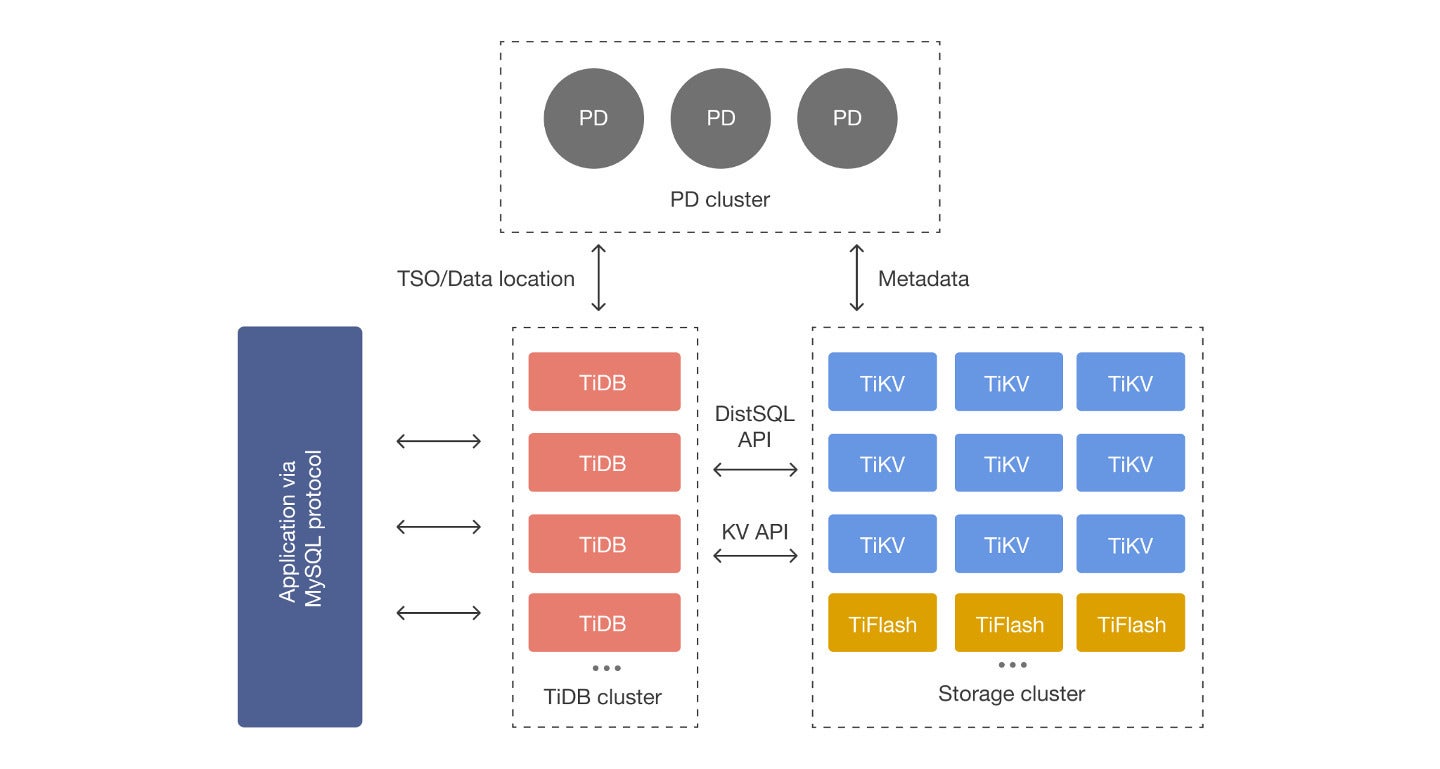
TiDB is a prime example of this new database architecture. It is an open-source distributed SQL database designed for the most demanding applications, scaling out to handle data volumes up to a petabyte in size. In this article we’ll explore the architectural features that give TiDB its scalability and reliability.
A cornerstone of TiDB’s architecture is its decoupling of storage and compute. Each of those two components can scale independently, ensuring optimal resource allocation and performance even as data needs evolve. This enables organizations to make the most efficient use of their hardware, enhancing cost-effectiveness and operational efficiency.
Another key design element is TiDB’s support for native horizontal scaling, or scale-out. Traditional transactional databases struggle with increasing data volumes and query loads. The easiest solution is to scale up—basically, to switch to more powerful hardware. However, there are limitations on the hardware of a single machine. TiDB automatically scales out to accommodate growth in transactions and data volumes. By adding new nodes to the system, TiDB keeps performance and availability consistent, even as data and user demands increase.
Another benefit to native horizontal scaling is that it eliminates the need for complex, disruptive sharding operations. The idea behind sharding is to speed up transactions and improve reliability by splitting the database into smaller, more manageable chunks, stored in separate database instances on separate physical media. In practice, maintaining a sharded system involves untold hours of manual work to keep each of the shards in optimal condition. Native horizontal scaling eliminates this burden. The database grows as needed, allowing it to manage unexpected spikes in demand—say, a surge in e-commerce traffic on Black Friday.
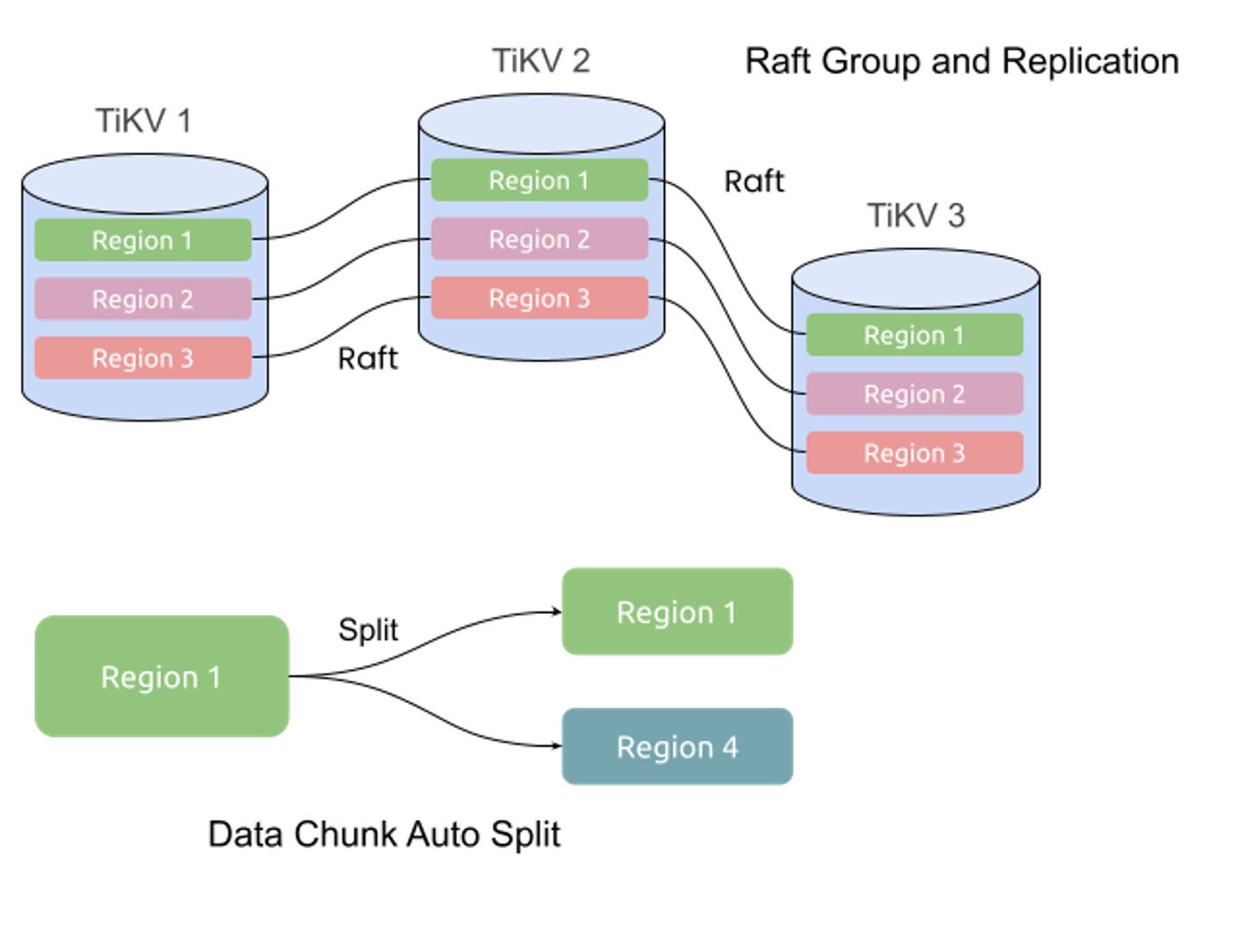
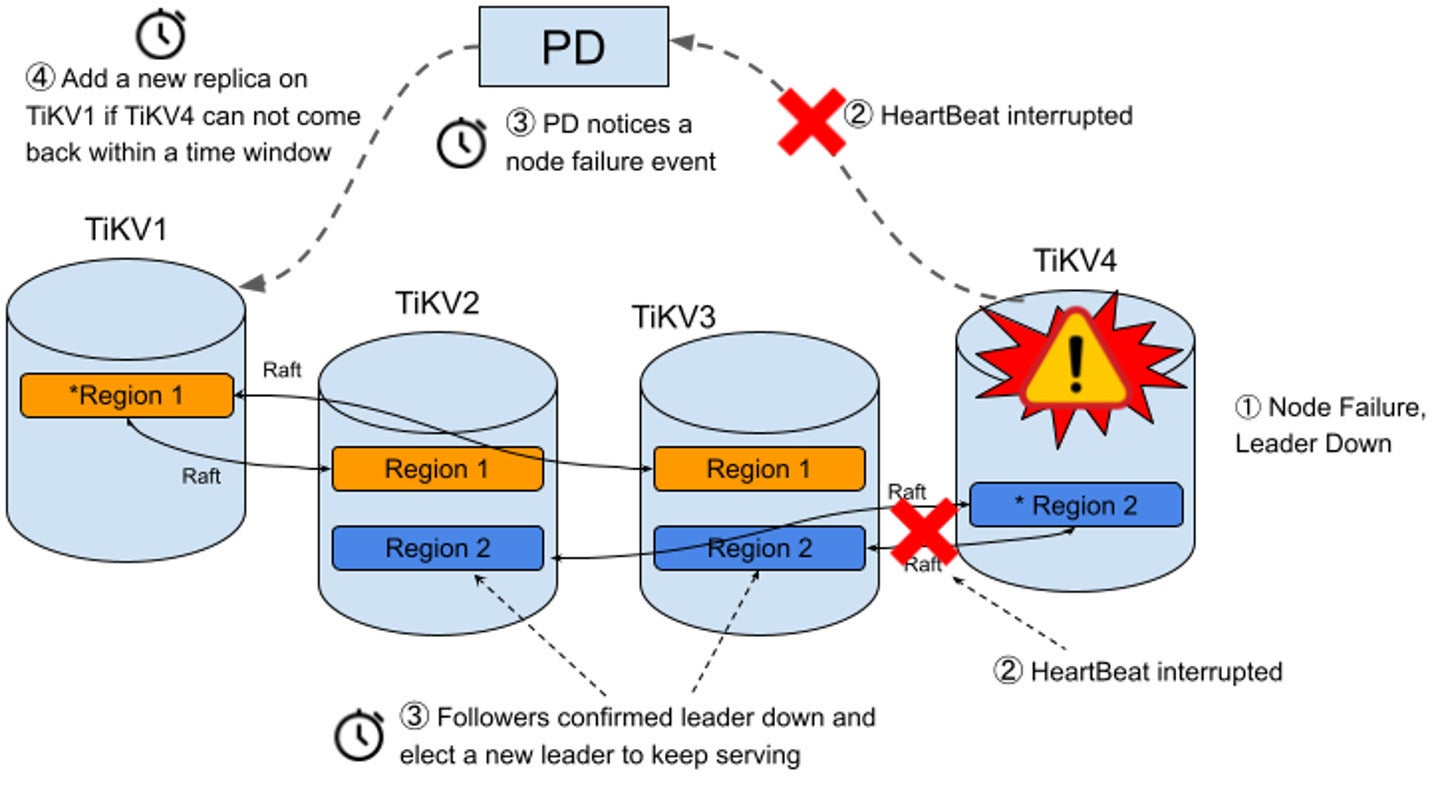
TiKV is TiDB’s distributed, transactional, key-value storage engine. TiKV stores data in key-value format. It can split the data into small chunks automatically and spread the chunks among the nodes according to the workload, available disk space, and other factors. TiDB leverages the Raft consensus algorithm in its replication model to ensure strong consistency and high availability for the data chunks.
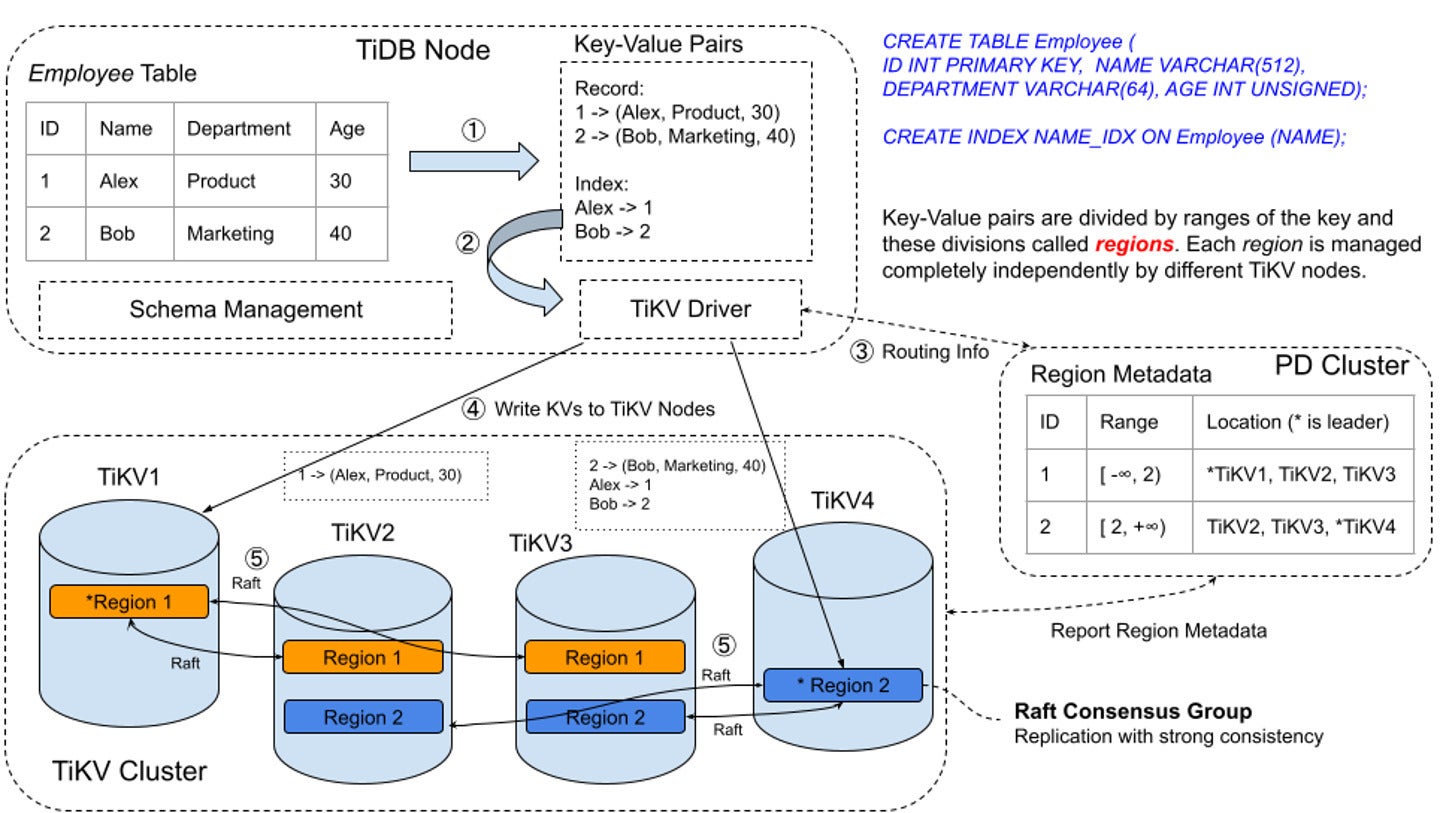
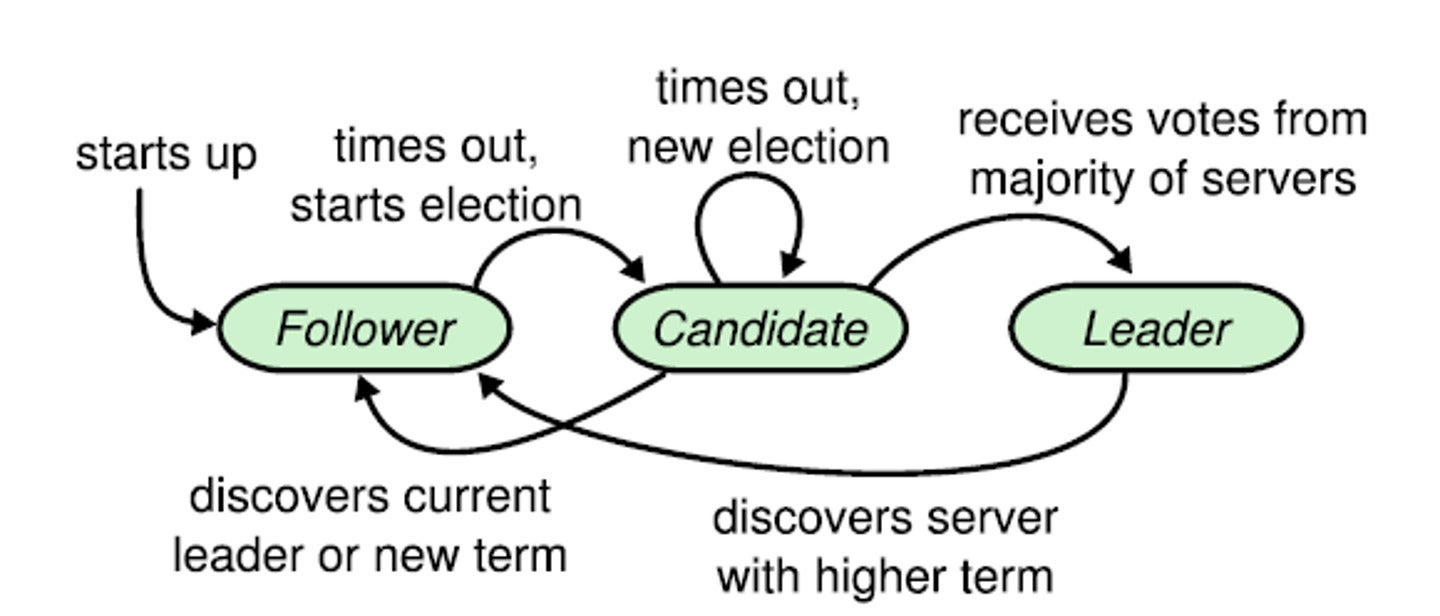
The Raft consensus algorithm is another important building block in TiDB’s architecture. TiDB uses Raft to manage the replication and consistency of data, ensuring the data behaves as if it were stored on a single machine even though it’s distributed across multiple nodes.
Here’s how it works. TiDB breaks down data into small chunks called regions. Each region acts as a Raft group, and can be split into multiple regions as data volumes and workloads change. When data is written to the TiDB cluster, it’s written to the leader node of the region. The Raft protocol ensures the data is replicated to follower nodes via log replication, maintaining data consistency across multiple replicas.
Initially, when a TiDB cluster is small, data is contained within a single region. However, as more data is added, TiDB automatically splits the region into multiple regions, allowing the cluster to scale horizontally. This process is known as auto-sharding, and it’s crucial to ensuring that TiDB can handle large amounts of data efficiently.
If the leader fails, Raft guarantees that one of the followers will be elected as the new leader, ensuring high availability. Raft also provides strong consistency, ensuring that every replica holds the same data at any given time. This enables TiDB to replicate data consistently across all nodes, making it resilient to node failures and network partitions.
One of the key benefits of TiDB’s auto-split and merge mechanism is that it is entirely transparent to the applications using the database. The database automatically reshards data and redistributes it across the entire cluster, negating the need for manual sharding schemes. This leads to both reduced complexity and reduced potential for human error, while also freeing up valuable developer time.
By implementing the Raft consensus algorithm and data chunk auto-split, TiDB ensures robust data consistency and high availability while providing scalability. This seamless combination allows businesses to focus on deriving actionable insights from their data, rather than worrying about the underlying complexities of data management in distributed environments.
Another building block of TiDB’s distributed architecture is distributed transactions, maintaining the essential ACID (atomicity, consistency, isolation, and durability) properties fundamental to relational databases. This capability ensures that operations on data are reliably processed and the integrity of data is upheld across multiple nodes in the cluster.
TiDB’s native support for distributed transactions is transparent to applications. When an application performs a transaction, TiDB automatically takes care of distributing the transaction across the involved nodes. There’s no need for developers to write complex, error-prone, distributed transaction control logic in the application layer. Moreover, TiDB employs strong consistency, meaning the database ensures that every read receives the most recent write, or an error in the case of ongoing conflicting transactions.
Because distributed transactions are natively supported by the TiKV storage engine, every node in the SQL layer can function as both a reader and a writer. This design eliminates the need for a designated primary node for writes, thereby enhancing the database’s horizontal scalability and eliminating potential bottlenecks or single points of failure. This is a significant advantage compared with systems that achieve scale by leveraging separate nodes to scale reads, while still using a single node to write. By eliminating the single-writer issue, TiDB achieves orders-of-magnitude higher TPS.
In discussing scalability, it’s imperative to look beyond data volumes and queries per second (QPS). Also important is the ability to handle unpredictable workloads and implement intelligent scheduling. TiDB is designed to anticipate and adapt to varying workload types and sudden demand surges. Its scheduling algorithms dynamically allocate resources, optimize task management, and prevent performance bottlenecks, ensuring consistent and efficient operation.
TiDB’s approach to scalability is also evident in its handling of large-scale database operations. TiDB’s architecture streamlines database definition language (DDL) tasks, which are often a bottleneck in large, complex systems. This ensures that even as a TiDB database grows, operations like schema changes perform efficiently.
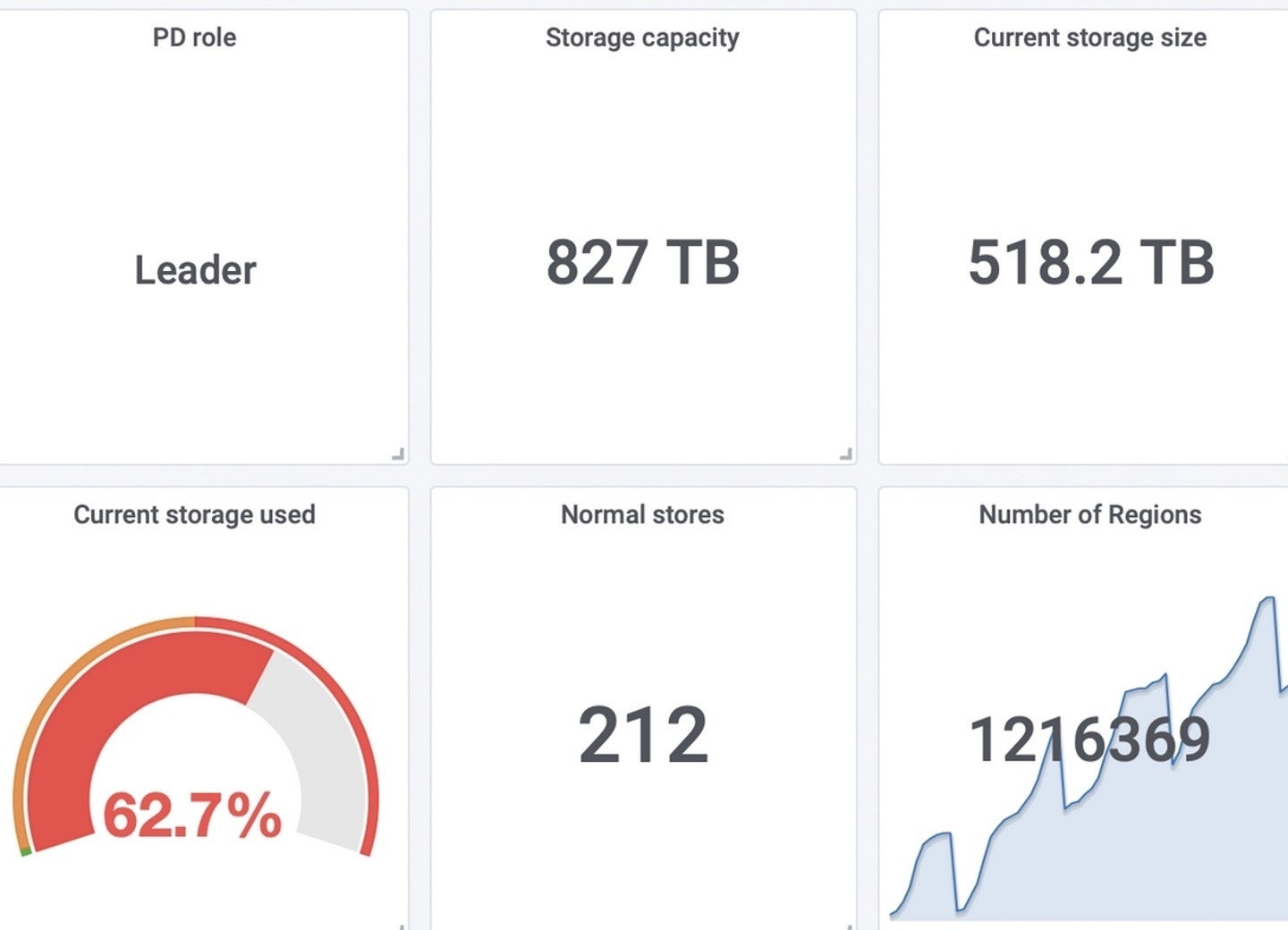
Here I’ll point you to two real-world examples of TiDB scalability. The first example shows a single TiDB cluster managing 500TB of data, encompassing 1.3 trillion records. The diagram below is the screenshot of the TiDB cluster monitoring dashboard.
The second example, from Flipkart, the largest e-commerce company in India, shows a TiDB cluster scaling to 1 million QPS. Compared with Flipkart’s previous solution, TiDB achieves better performance and reduces storage space by 82%.
Applications and services depend on uninterrupted operation and robust data protection. Without them, users will quickly lose faith in the utility of the database system and its output.
TiDB offers native support for high availability to minimize downtime for critical applications and services. It also provides features and tools for quick restoration of data in the event of a major outage.
We have discussed how TiDB uses the Raft algorithm to achieve strong, consistent replication. The location of replicas can be defined in various ways depending on the topology of the network and the types of failures users want to guard against.
Typical scenarios supported by TiDB include:
With a data placement scheduling framework, TiDB can support the needs of different data strategies.
For short-term failures, such as a server restart, TiDB uses Raft to continue seamlessly as long as a majority of replicas remain available. Raft ensures that a new “leader” for each group of replicas is elected if the former leader fails so that transactions can continue. Affected replicas can rejoin their group once they’re back online.
For longer-term failures (the default timeout is 30 minutes), such as a zone outage or a server going down for an extended period of time, TiDB automatically rebalances replicas from the missing nodes, leveraging unaffected replicas as sources. By using capacity information from the storage nodes, TiDB identifies new locations in the cluster and re-replicates missing replicas in a distributed fashion, using all available nodes and the aggregate disk and network bandwidth of the cluster.
In addition to Raft, TiDB provides a wide range of tools and features for disaster recovery including data mirroring, quick error rectification, continuous data backups, and full-scale restoration.
The business world revolves around data. The worldwide surge in online financial transactions, fueled by business models like pay-as-you-go, has created an unprecedented demand for performance, along with the assurance that that performance will be there when it’s needed.
A distributed SQL database is what you get when you redesign relational databases around the idea of change. As the foundation for business applications, databases must be able to adapt to the unexpected, whether it be unexpected growth, unexpected traffic, or unexpected catastrophes.
It all comes back to scale and reliability, the capacity to perform and the trust in performance. Scale gives users the ability to make things the world has never seen before. Reliability gives them the faith that what they build will keep working. It’s what turns a prototype into a profitable business. And at the heart of the business, behind the familiar SQL interface, is a new architecture for a world where data is paramount.
Li Shen is senior vice president at PingCAP, the company behind TiDB.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
Next read this:
Posted by Richy George on 8 March, 2024

Entity Framework Core is an object-relational mapper, or ORM, that isolates your application’s object model from the data model. That allows you to write code that performs CRUD operations without worrying about how the data is stored. In other words, you work with the data using familiar .NET objects.
In Entity Framework Core, the DbContext connects the domain classes to the database by acting as a bridge between them. You can take advantage of the DbContext to query data in your entities or save your entities to the underlying database.
I’ve discussed the basics of DbContext in a previous article. In this article we’ll dive into DbContext in a little more detail, discuss the DbContext lifetime, and offer some best practices for using DbContext in Entity Framework Core. EF Core allows you to instantiate a DbContext in several ways. We’ll examine some of the options.
To use the code examples provided in this article, you should have Visual Studio 2022 installed in your system. If you don’t already have a copy, you can download Visual Studio 2022 here.
To create an ASP.NET Core 8 Web API project in Visual Studio 2022, follow the steps outlined below.
We’ll use this ASP.NET Core Web API project to work with DbContext in the sections below.
When working with Entity Framework Core, the DbContext represents a connection session with the database. It works as a unit of work, enabling developers to monitor and control changes made to entities before saving them to the database. We use the DbContext to retrieve data for our entities or persist our entities in the database.
The DbContext class in EF Core adheres to the Unit of Work and Repository patterns. It provides a way to encapsulate database logic within the application, making it easier to work with the database and maintain code reusability and separation of concerns.
The DbContext in EF Core has a number of responsibilities:
The DbContext class in Entity Framework Core plays a crucial role in facilitating the connection between the application and the database, providing support for data access, change tracking, and transaction management. The lifetime of a DbContext instance starts when it is instantiated and ends when it is disposed.
Here is the sequence of events in a typical unit of work using EF Core:
A DbContext instance should be disposed when it is no longer needed to free up any unmanaged resources and prevent memory leaks. However, it is not a recommended practice to dispose off DbContext instances explicitly or to use DbContext within a using statement.
Here’s why you should not dispose of your DbContext instances:
Instead of using using blocks to dispose of the DbContext instances in your application, consider taking advantage of dependency injection to manage their lifetime. Using dependency injection will ensure that the DbContext is created and disposed of appropriately, depending on the life cycle of the application or the scope of the operation.
There is no specific rule for creating a DbContext instance. The requirements of your application should determine which approach you take. Each of the approaches illustrated below has its specific use cases—none of them is better than the others.
You can extend the DbContext class in EF Core to create your own DbContext class as shown below.
public class IDGDbContext : DbContext
{
public ApplicationDbContext(DbContextOptions<ApplicationDbContext> options)
: base(options)
{
}
}
Similarly, you could instantiate a DbContextOptionsBuilder class and then use this instance to create an instance of DbContextOptions. This DbContextOptions instance could then be passed to the DbContext constructor. This approach helps you explicitly create a DbContext instance.
Alternatively, you can create DbContext instances via dependency injection (DI) by configuring your DbContext instance using the AddDbContext method as shown below.
services.AddDbContext<IDGDbContext>(
options => options.UseSqlServer("name=ConnectionStrings:DefaultConnection"));
You can then take advantage of constructor injection in your controller to retrieve an instance of DbContext as shown below.
public class IDGController
{
private readonly IDGDbContext _dbContext;
public IDGController(IDGDbContext dbContext)
{
_dbContext = dbContext;
}
}
Typically, an HTTP request-response cycle represents a unit of work in web applications. With DI, we are able to create a DbContext instance for each request and dispose of it when that request terminates.
I prefer using a DI container to instantiate and configure DbContext because the DI container manages the DbContext instances and lifetimes for you, relieving you of the pain of managing these instances explicitly.
A third option is to create a DbContext instance by overriding the OnConfiguring method in your custom DbContext class. You can then take advantage of the DbContext constructor to pass configuration information, such as a connection string.
The code snippet below shows how you can initialize DbContext in the OnConfiguring method of your custom DbContext class.
public class IDGDbContext : DbContext
{
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder.UseSqlServer("Specify your database connection string here.");
}
}
You can also create an instance of DbContext using a factory. A factory comes in handy when your application needs to perform multiple units of work within a particular scope.
In this case, you can use the AddDbContextFactory method to register a factory and create your DbContext objects as shown in the code snippet given below.
services.AddDbContextFactory<IDGDbContext>(
options =>
options.UseSqlServer("Specify your database connection string here."));
You can then use constructor injection in your controller to construct DbContext instances as shown below.
private readonly IDbContextFactory<IDGDbContext> _dbContextFactory;
public IDGController(IDbContextFactory<IDGDbContext> dbContextFactory)
{
_dbContextFactory = dbContextFactory;
}
You can turn on sensitive data logging to include application data when exceptions are logged in your application. The following code snippet shows how this can be done.
optionsBuilder
.EnableSensitiveDataLogging()
.UseSqlServer("Specify your database connection string here.");
Finally, note that multiple parallel operations cannot be executed simultaneously on the same DbContext instance. This refers to both the parallel execution of async queries and any explicit use of multiple threads of the instance simultaneously. Therefore, it is recommended that parallel operations be performed using separate instances of the DbContext. Additionally, you should never share DbContext instances between threads because it is not thread-safe.
Next read this:
Posted by Richy George on 8 March, 2024

Entity Framework Core is an object-relational mapper, or ORM, that isolates your application’s object model from the data model. That allows you to write code that performs CRUD operations without worrying about how the data is stored. In other words, you work with the data using familiar .NET objects.
In Entity Framework Core, the DbContext connects the domain classes to the database by acting as a bridge between them. You can take advantage of the DbContext to query data in your entities or save your entities to the underlying database.
I’ve discussed the basics of DbContext in a previous article. In this article we’ll dive into DbContext in a little more detail, discuss the DbContext lifetime, and offer some best practices for using DbContext in Entity Framework Core. EF Core allows you to instantiate a DbContext in several ways. We’ll examine some of the options.
To use the code examples provided in this article, you should have Visual Studio 2022 installed in your system. If you don’t already have a copy, you can download Visual Studio 2022 here.
To create an ASP.NET Core 8 Web API project in Visual Studio 2022, follow the steps outlined below.
We’ll use this ASP.NET Core Web API project to work with DbContext in the sections below.
When working with Entity Framework Core, the DbContext represents a connection session with the database. It works as a unit of work, enabling developers to monitor and control changes made to entities before saving them to the database. We use the DbContext to retrieve data for our entities or persist our entities in the database.
The DbContext class in EF Core adheres to the Unit of Work and Repository patterns. It provides a way to encapsulate database logic within the application, making it easier to work with the database and maintain code reusability and separation of concerns.
The DbContext in EF Core has a number of responsibilities:
The DbContext class in Entity Framework Core plays a crucial role in facilitating the connection between the application and the database, providing support for data access, change tracking, and transaction management. The lifetime of a DbContext instance starts when it is instantiated and ends when it is disposed.
Here is the sequence of events in a typical unit of work using EF Core:
A DbContext instance should be disposed when it is no longer needed to free up any unmanaged resources and prevent memory leaks. However, it is not a recommended practice to dispose off DbContext instances explicitly or to use DbContext within a using statement.
Here’s why you should not dispose of your DbContext instances:
Instead of using using blocks to dispose of the DbContext instances in your application, consider taking advantage of dependency injection to manage their lifetime. Using dependency injection will ensure that the DbContext is created and disposed of appropriately, depending on the life cycle of the application or the scope of the operation.
There is no specific rule for creating a DbContext instance. The requirements of your application should determine which approach you take. Each of the approaches illustrated below has its specific use cases—none of them is better than the others.
You can extend the DbContext class in EF Core to create your own DbContext class as shown below.
public class IDGDbContext : DbContext
{
public ApplicationDbContext(DbContextOptions<ApplicationDbContext> options)
: base(options)
{
}
}
Similarly, you could instantiate a DbContextOptionsBuilder class and then use this instance to create an instance of DbContextOptions. This DbContextOptions instance could then be passed to the DbContext constructor. This approach helps you explicitly create a DbContext instance.
Alternatively, you can create DbContext instances via dependency injection (DI) by configuring your DbContext instance using the AddDbContext method as shown below.
services.AddDbContext<IDGDbContext>(
options => options.UseSqlServer("name=ConnectionStrings:DefaultConnection"));
You can then take advantage of constructor injection in your controller to retrieve an instance of DbContext as shown below.
public class IDGController
{
private readonly IDGDbContext _dbContext;
public IDGController(IDGDbContext dbContext)
{
_dbContext = dbContext;
}
}
Typically, an HTTP request-response cycle represents a unit of work in web applications. With DI, we are able to create a DbContext instance for each request and dispose of it when that request terminates.
I prefer using a DI container to instantiate and configure DbContext because the DI container manages the DbContext instances and lifetimes for you, relieving you of the pain of managing these instances explicitly.
A third option is to create a DbContext instance by overriding the OnConfiguring method in your custom DbContext class. You can then take advantage of the DbContext constructor to pass configuration information, such as a connection string.
The code snippet below shows how you can initialize DbContext in the OnConfiguring method of your custom DbContext class.
public class IDGDbContext : DbContext
{
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder.UseSqlServer("Specify your database connection string here.");
}
}
You can also create an instance of DbContext using a factory. A factory comes in handy when your application needs to perform multiple units of work within a particular scope.
In this case, you can use the AddDbContextFactory method to register a factory and create your DbContext objects as shown in the code snippet given below.
services.AddDbContextFactory<IDGDbContext>(
options =>
options.UseSqlServer("Specify your database connection string here."));
You can then use constructor injection in your controller to construct DbContext instances as shown below.
private readonly IDbContextFactory<IDGDbContext> _dbContextFactory;
public IDGController(IDbContextFactory<IDGDbContext> dbContextFactory)
{
_dbContextFactory = dbContextFactory;
}
You can turn on sensitive data logging to include application data when exceptions are logged in your application. The following code snippet shows how this can be done.
optionsBuilder
.EnableSensitiveDataLogging()
.UseSqlServer("Specify your database connection string here.");
Finally, note that multiple parallel operations cannot be executed simultaneously on the same DbContext instance. This refers to both the parallel execution of async queries and any explicit use of multiple threads of the instance simultaneously. Therefore, it is recommended that parallel operations be performed using separate instances of the DbContext. Additionally, you should never share DbContext instances between threads because it is not thread-safe.
Next read this:
Posted by Richy George on 4 March, 2024

SQL, the Structured Query Language, remains one of the most widely used programming languages, coming in fourth in Stack Overflow’s research for 2023. Just over half (51.52%) of professional developers use SQL in their work, but only around a third (35.29%) of those learning to code use SQL.
For a language that has remained in use for decades, SQL has a mixed reputation among developers. Why does SQL remain in use when so many other languages have come and gone? And why does SQL have a bright future still?
One reason why SQL remains in use is because it is ubiquitous. Knowing SQL is a base-level skill for many developers, leading to a large pool of people with the skills available. In turn, this encourages more people to learn SQL, as they can see the demand for people with those skills and deliver career opportunities they can take advantage of.
Alongside this ubiquity, SQL is stable. It is an effective standard that developers can rely on and it won’t change from version to version. This makes SQL suitable for long-term support planning, and the teams involved can plan ahead around their data infrastructure. This also makes it simpler to transition projects between different developers as staff members change roles.
Following on from this, SQL makes it easier to meet compatibility requirements around data within applications. Using SQL as your approach to interrogating data in one data component makes it easier to transfer over to using another option if your needs change. For example, if you decide to switch from one database to another, you would not need to edit how your application logic works when using SQL terms, as these are the same everywhere.
Because SQL acts like a standard, one benefit is that it makes it easier to make your data portable. Rather than being tied to a specific database with its own language and way of storing data, SQL ensures that your data is yours and you can do what you want with it. Effectively, you no longer have to think specifically about your databases and what they can deliver. Instead, you can look at the tools that exist within the language as the point of control over your infrastructure planning process.
As an example, consider your choices around running a database like MySQL, and then wanting to change to another option like PostgreSQL. These databases would be different in how they operate and manage data over time. However, from a functional point of view, using SQL to interrogate that data would give you the same results.
Alongside the popularity of SQL as a language, it is also worth looking at what SQL delivers from a technology standpoint. On this front, the biggest benefit is that it is logical in its design. This means that, when you understand how it works, it can be used in elegant and clever ways.
As part of this, we do have to look at the link between SQL and relational databases. For many developers, SQL is tied very tightly to the relational database model, with all the strengths and failings that this might have. However, SQL as a language is separate from relational databases, and it is important not to conflate the two together.
Nowadays many non-relational databases have embraced a table-like model and SQL language. It’s been a long time since SQL and the relational model were synonymous, and with the rise of non-relational databases the boundaries have become more fluid. For example, some key-value stores and some document store databases have adopted a table-like structure for organizing their data, and some provide a subset of SQL or a SQL-like query language for enhanced accessibility and to make it easier for developers to work with their products.
Over the years, the relational model has proved to be an extremely effective one for database designs. The reason for this is that the model is based on solid mathematical theory that is very precise. These strong theoretical foundations are why relational databases have remained so popular in computer science and software engineering generally. SQL has made it easier to access that logical and computing power over time, and to keep those systems running in a uniform way that everyone can understand.
While I have mentioned that SQL is a de facto standard, like any other standard it has evolved over time and can be extended when planned well. The best example of this evolution is the change in the standard that allows database vendors to support different JSON formats in 2016.
For many years, developers who wanted to work with JSON had the option to use document-oriented databases like MongoDB for their data store, while other databases would be secondary options due to performance and ease of use. Today, that is not the case, as many relational databases like PostgreSQL have implemented JSON support that can work as fast or even faster than document-oriented databases for certain workloads. This support makes it easier for developers to design systems and infrastructure that directly supports their application goals, rather than being tied to a specific approach.
Another benefit of SQL is that it is a declarative language. Declarative programming works by describing what you want the program to do, rather than specifying the steps that you want the program to take to do it. For developers and databases, this makes creating queries easier, because you can concentrate on the result you want to achieve rather than putting together the whole calculation. In effect, SQL lets you describe the outcome, and leaves the complexity of executing the calculation to the database.
Like any powerful language, SQL has its critics. For example, one common complaint is that SQL optimizers are not very effective at improving performance. While you might want to improve your results and the speed of response, these tools are only as powerful as the amount of work that you put in at the start. We sometimes face a similar problem with language compilers. Although compilers usually succeed at turning the developer’s code into a smaller and faster binary, they have been known to fail badly on occasion, with the opposite result.
As a developer, you may need to assist the compiler or optimizer to achieve the right results. Sometimes this knowledge can be obscure! Like Spider-Man’s Uncle Ben said, great power comes with great responsibility. You should expect to optimize your SQL approach yourself as much as possible, rather than solely relying on tools to deliver improvements.
Another common criticism of SQL is due to its strong link to relational databases. How can something so deeply rooted in traditional database design be right for the modern world? Of course, the combination of SQL and relational databases continues to serve hundreds of use cases today, delivering scalability and performance that can meet application needs. The challenge is to design your approach based on understanding what SQL is good at delivering.
As the demand for software, the pace of software development, and the number of developers have increased, the challenge for SQL is that fewer developers have a deep understanding of how SQL operates from a theoretical perspective. While movements like devops and site reliability engineering concentrate on meeting the demands that businesses have around IT services, the roles involved tend to cover multiple parts of the IT stack rather than specific functions.
Although these roles theoretically focus on the total system, there is not enough focus on how to align the business logic, or what the customer wants to achieve, with the intricacies of the infrastructure. Why is this so important? Because a database architecture must not only meet functional requirements but also align with performance, scalability, and security objectives. Without both, you lack a solid foundation for successful software development.
When applications start to scale massively or when performance problems appear, knowing how SQL works can prove to be extremely useful. Understanding query design, such as how to cherry-pick data from a larger table rather than parsing data from the same table multiple times, can have a huge impact on performance. These data management skills effectively depend on understanding database theory. This takes time to understand and deploy in practice, but it is essential to deliver better results.
Learning any language can be difficult and time-consuming. Many of us don’t have the time to dig into the principles and then apply that knowledge across languages and applications. However, this does lead to problems such as poor performance, which then become harder to diagnose and treat effectively. Deploying the wrong kind of database can also affect the success of your project. You can be very happy with one database that is great for certain use cases, but it might not be right for everything. SQL makes it easier to abstract those requirements away from the underlying infrastructure. Even if you make a mistake with your database choice, SQL makes it easier to move to a better option.
SQL remains popular with many users, and it will remain popular because it solves some of the biggest challenges that exist around how to work with data. It may have a scary reputation for some, but that does not take away from the huge amount of information technology that relies on SQL every day to provide us with value. Long may we SELECT SQL and CREATE value with it.
Charly Batista is PostgreSQL technical lead at Percona.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
Next read this:





This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →

This post is intended for businesses and other organizations interested... Read more →
Copyright 2015 - InnovatePC - All Rights Reserved
Site Design By Digital web avenue