Generative AI has had an immediate and enormous impact on software development. Software developers have embraced generative AI tools that help with coding, and they are working feverishly to build generative AI applications themselves. Databases can help—especially fast, scalable, multi-model databases like SingleStore.
At the inaugural SingleStore Now conference, SingleStore announced several AI-focused innovations with developers in mind. These include SingleStore Scope, Aura, Notebooks, and the Elegance SDK. Given the impact that AI and LLMs are having on developers, it makes sense to dive into the ways that these innovations make developing AI applications easier.
SingleStore Scope
If you’ve been working with AI or LLMs in any way, you know that vector databases have become much more popular because of their ability to help you search for the nearest n representations of the data you’re working with. You can then use those search results to provide additional context to your LLM to make the responses more accurate. SingleStoreDB has supported vector functions and vector search for a number of years now, but generative AI applications require you to search among millions or billions of vector embeddings in milliseconds—which gets difficult using k-Nearest Neighbor (kNN) across huge data sets.
Scope adds Approximate Nearest Neighbor (ANN) search as an additional option to the already existing k-Nearest Neighbor (kNN) search. The primary difference between ANN and kNN is in the name: approximate vs. nearest. Initial testing shows ANN to be orders of magnitude faster for vector search, taking your AI use cases from fast to real time. Real-time vector search ensures that your applications respond instantly to queries, even when that data has just been written to the database.
Scope uses a number of techniques to make your search functions more performant, namely inverted file (IVF) with product quantization (PQ). With IVF with PQ, you can lower the build times of your index while improving the compression ratios and memory footprint of your vector searches. Beyond IVF with PQ, Scope adds the hierarchical navigable small world (HNSW) approach to allow for high-performance vector index searches using high dimensionality.
With Scope, you can combine all of these new indexing approaches, along with full-text search, to combine hybrid semantic (vector similarity) and lexical/keyword search in one query.
Below you can see an example of using hybrid search. To view the code in its broader context, check out the full notebook on SingleStore Spaces.
hyb_query = 'Articles about Aussie captures'
hyb_embedding = model.encode(hyb_query)
# Create the SQL statement.
hyb_statement = sa.text('''
SELECT
title,
description,
genre,
DOT_PRODUCT(embedding, :embedding) AS semantic_score,
MATCH(title, description) AGAINST (:query) AS keyword_score,
(semantic_score + keyword_score) / 2 AS combined_score
FROM news.news_articles
ORDER BY combined_score DESC
LIMIT 10
''')
# Execute the SQL statement.
hyb_results = pd.DataFrame(conn.execute(hyb_statement, dict(embedding=hyb_embedding, query=hyb_query)))
hyb_results
The above query finds the average scores of semantic and keyword searches, combines them, and sorts the news articles by this calculated score. By removing the extra complexity of performing lexical/keyword and semantic searches separately, hybrid search simplifies the code for your application.
SingleStore’s implementation of these new indexing strategies also allows us to quickly incorporate new strategies as they become available, ensuring that your application will always perform its best when backed by SingleStoreDB.
SingleStore Aura
When you’re working with extremely large data sets, one of the best things you can do to keep your performance and cost in check is to perform the compute work as close to the data as possible. SingleStore Aura enables you to deploy compute resources (CPUs and GPUs) for AI, machine learning, or ETL (extract, transform, load) workloads alongside your data. With Aura, SingleStore customers can use these new compute resources to run their own machine learning models or other software in a way that allows them to have the full context of their enterprise data, without worrying about egress performance and cost.
Coupling Aura with Aura Job Service (private preview), you can schedule SQL and Python jobs from within SingleStore Notebooks to process their data, train or fine-tune a machine learning model, or do other complex data transformation work. If your company often updates the fine-tuning of your AI model or LLM, you can now do so in a scheduled manner—using optimized compute platforms that live next to your data.
SingleStore Notebooks
Many engineers and data scientists are comfortable working with Jupyter Notebooks, hosted, interactive, shareable documents in which you can write and execute code blocks, interspersed with documentation, and visualize data. What is often missing in a Jupyter environment are native connections to your databases and SQL functionality.
With the announcement of general availability of SingleStore Notebooks, SingleStore makes it easy for you to explore, visualize, and collaborate with your data and peers in real time. Getting started with SingleStore Notebooks is extremely simple:
In the navigation pane on the left, you’ll see Notebooks. Click the plus sign next to Notebooks and fill out the details. If you intend on sharing this notebook with your colleagues, ensure that you choose Shared under Location. Set the Default Cell Language to the language you will primarily use in the notebook, then click create.
IDG
Note: You can also choose one of the templates or select from the gallery, if you’d like to see how a Notebook can look.
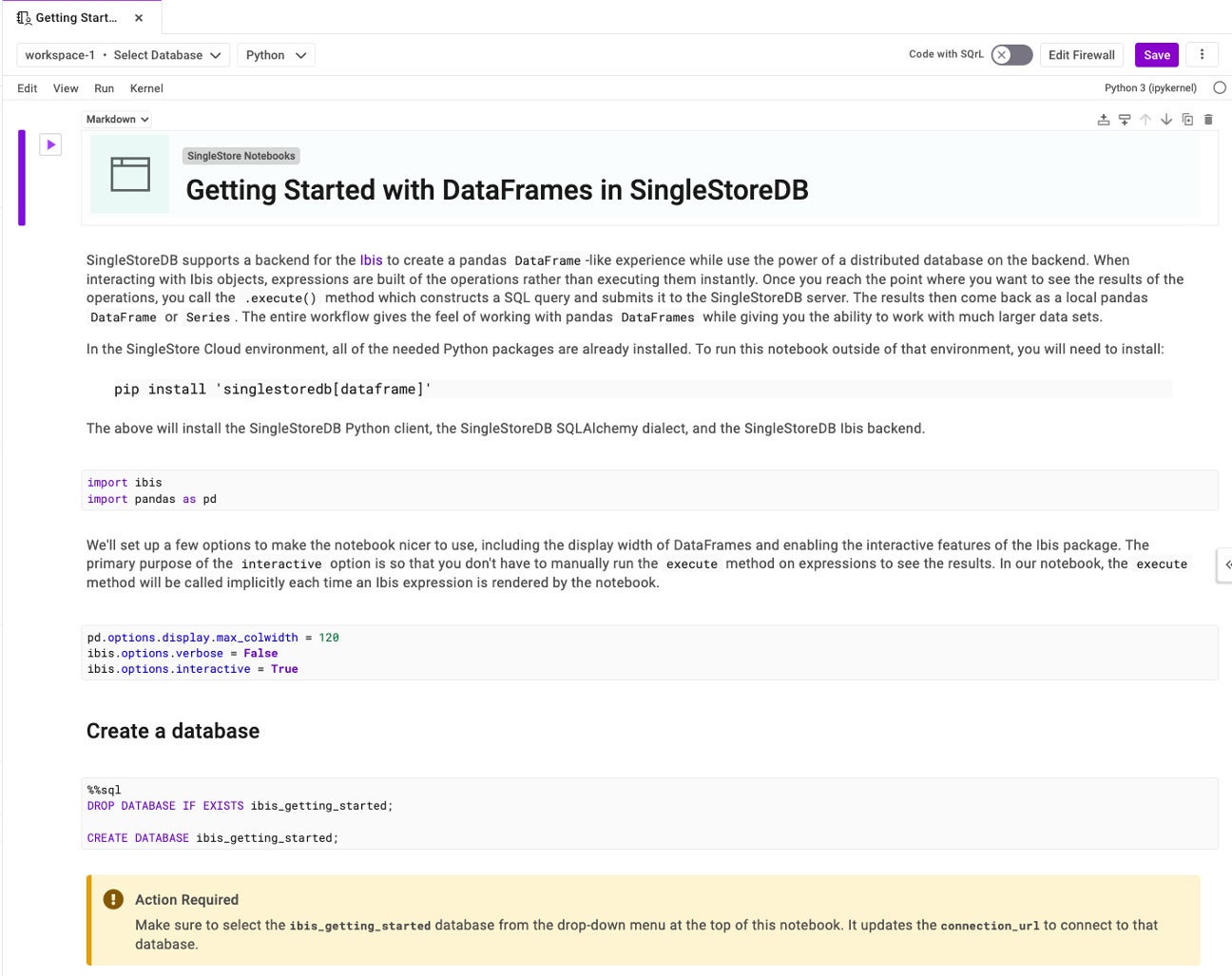
For a handy example, I have imported a notebook from the gallery called “Getting Started with DataFrames in SingleStoreDB.” This notebook walks you through the process of using pandas DataFrames to better take advantage of the distributed nature of SingleStoreDB.
IDG
When you select the Workspace and Database at the top of the notebook, it will update the connection_url variable so you can quickly and easily connect to and work with your data.
In this notebook, we use a simple command, conn = ibis.singlestoredb.connect(), to create a connection to the database. No more worrying about putting together the connection string, removing one more thing from the complex process of prototyping something using your data.
IDG
In Notebooks, you simply select the Play button next to each cell to run that code block. In the screenshot above, we’re importing packages ibis and pandas.
SingleStore Notebooks is an extremely powerful platform that will allow you to prototype applications, perform data analysis, and quickly repeat tasks that you may need to perform using your data living inside of SingleStoreDB. This rapid prototyping is an extremely effective way to see how you could implement AI, LLMs, or other big data methods into your business.
Be sure to check out SingleStore Spaces to see a large sample of Notebooks that showcase anything from image matching to building LLM apps that use retrieval-augmented generation (RAG) on your own data.
SingleStore Elegance
SingleStore Elegance is an NPM package designed to help React developers rapidly build applications on top of SingleStoreDB using SingleStore Kai or MySQL connections to the database. With the release of Elegance, there has never been a better time to develop an AI application that is backed by SingleStoreDB.
Elegance offers a powerful SDK covering a number of features:
Vector search
Chat completions
File embeddings and generation from CSV or PDF
SQL and aggregate queries
SQL and Kai database connection support
Ready-to-use Node.js controllers and React hooks
Getting started with a demo application is as simple as following just a few simple steps:
If you’d prefer to start from scratch and build something on your own, you can get started with a simple npm install @singlestore/elegance-sdk and follow the steps from our package page on npmjs.com.
Real time, right now
The business landscape is changing rapidly with the mainstreaming of AI and LLMs, causing nearly everyone to evaluate whether or not they should implement some form of AI. Many companies are already putting together POCs. These releases show that SingleStore is 100% focused on building a real-time analytics and AI database that gives you the tooling you need to build your applications quickly and efficiently—getting your AI and LLM projects to market faster.
That wraps up the AI innovations that emerged from SingleStore Now. In case you were unable to make the event in person, you can watch all of the sessions on demand.
Wes Kennedy is a principal evangelist at SingleStore, where he creates content, demo environments, and videos and dives into ways that we can meet customers where they are. He has a diverse background in tech covering everything from being a virtualization engineer, sales engineer, to technical marketing.
—
Generative AI Insights provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss the challenges and opportunities of generative artificial intelligence. The selection is wide-ranging, from technology deep dives to case studies to expert opinion, but also subjective, based on our judgment of which topics and treatments will best serve InfoWorld’s technically sophisticated audience. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Contact doug_dineley@foundryco.com.
In August 2023, a small group of Google development and UX leads bewailed the difficulty of setting up a development environment for multiplatform and full-stack apps, and offered their take on an experimental prototype intended to solve the issues. Difficulty setting up technology stacks for development is not a new problem. It has been an issue since at least the early 1980s, when personal computers became available.
Project IDX is a browser-based development environment built on Code OSS and powered by Codey, a generative AI foundation model trained on code and built on PaLM 2. Project IDX is designed to make it easier to build, manage, and deploy full-stack web and multiplatform applications, using popular frameworks and languages.
Code OSS is the fully open-source version of Microsoft’s Visual Studio Code. The latter has a few proprietary additions, despite being free software.
At the time of its announcement in August, Project IDX was only available through a waitlist sign-up; my application was finally approved in December. Project IDX is still very much a rough-edged preview, but has an interesting design and some utility, even if it’s not yet intended for use in a production environment.
There are several products that compete with Project IDX at some level. These include AWS Cloud9, Gitpod, Online IDE, Replit, StackBlitz, Eclipse Che, Codeanywhere, and GitHub Codespaces.
Feels like Visual Studio Code
There are a number of features that make Project IDX look promising despite its rough edges and its feel of being under construction. For starters, it’s actually a familiar environment for anyone who uses Visual Studio Code. As I understand it, the portions of VS Code that aren’t included in Code OSS are the Microsoft-specific customizations, which don’t matter too much in this context.
Some of those customizations are replaced by the IDX AI powered by Codey. The IDX AI provides code suggestions as you type and offers an AI-powered code chat you can ask for help with your code, to generate new code, to translate code to another language, to explain code, and to write unit tests. Supposedly, IDX AI also highlights possible license requirements based on AI-generated code, although I haven’t seen that pop up.
IDG
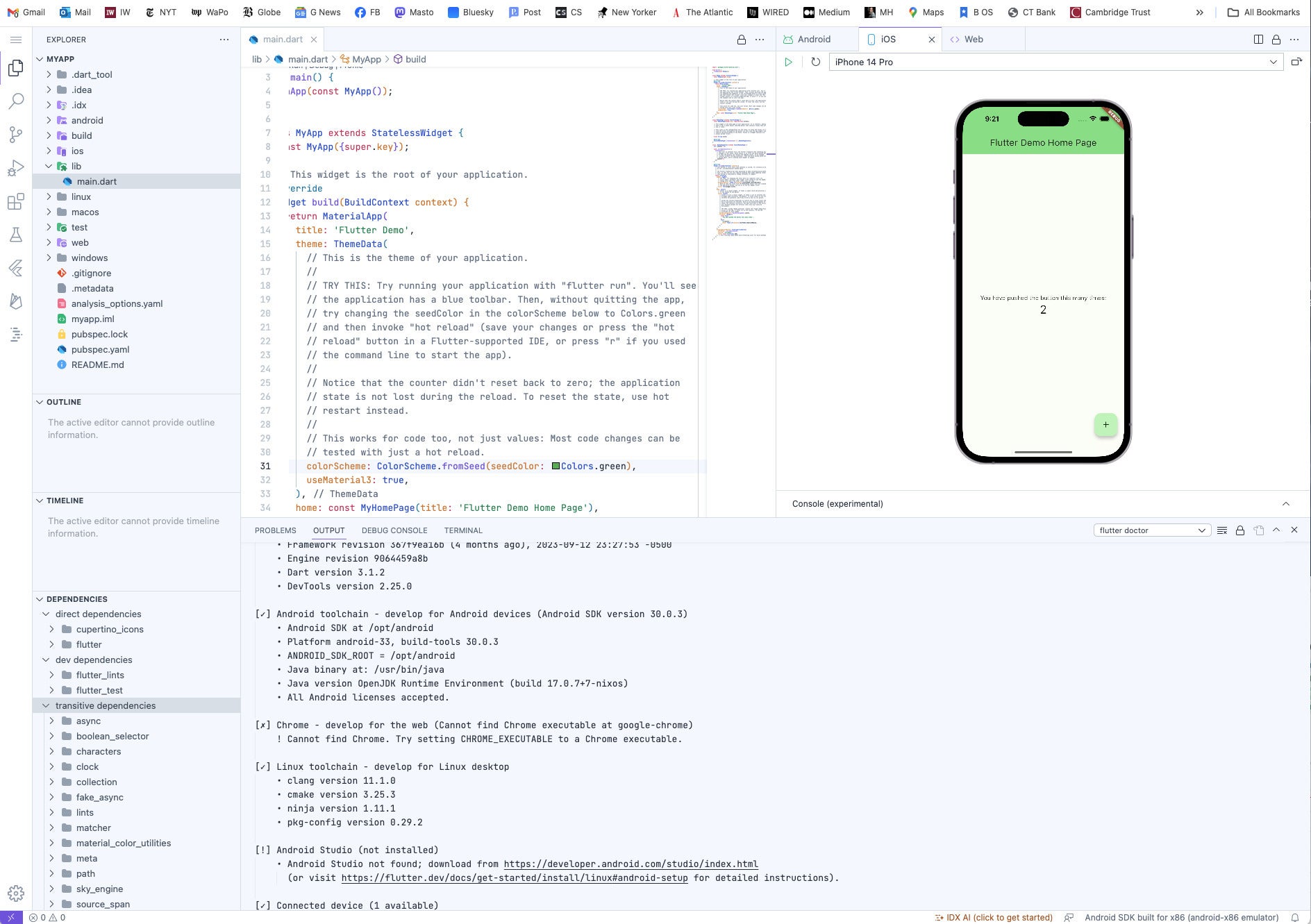
Project IDX will feel familiar because of its similarity to VS Code. The top left “hamburger” menu replaces the top row menu in VS Code, and offers most of the same menu items when it pops out. The icons in the vertical row below that control the contents of the next column to the right, currently showing the file explorer, the code outline for the current file, the timeline for the current file, and the dependencies for the app. The large editing pane currently showing main.dart can display up to four tabs. The preview window to the right can also display the IDX AI pane and additional code file tabs. The large area at the bottom right displays code problems, output, a debug console, and a terminal.
Runs in a cloud workstation
The IDX Code OSS editor runs in a Google Cloud VM, called a Cloud Workstation. Normally, Cloud Workstation time is billed per hour at a rate that varies with the size of the machine type, from $0.16/hour to $9.36/hour. Project IDX is currently free.
Normally, Cloud Workstations support a variety of popular IDEs and Duet AI. Project IDX supports only Code OSS, and Codey instead of Duet. (I can’t tell you the difference between Duet AI and Codey in practice, although it might be an interesting comparison to investigate.) Cloud Workstations can normally run inside your private network and in your staging environment. Project IDX is currently restricted to its own environment.
Supports many languages and frameworks
You can create projects in Project IDX with built-in templates and GitHub imports. The templates support the JavaScript, TypeScript, and Dart languages and the Angular, React, NextJS, Vue, Svelte, and Flutter frameworks. In the future, Project IDX is due to support Python, Go, and “AI.” You can optionally use Nix to customize your workspace.
IDG
This menu offers you your initial choice of the kind of app you’ll generate or import. Each item (other than the “coming soon” group at the bottom) opens a secondary screen for specifying your app framework and naming your app.
—
IDG
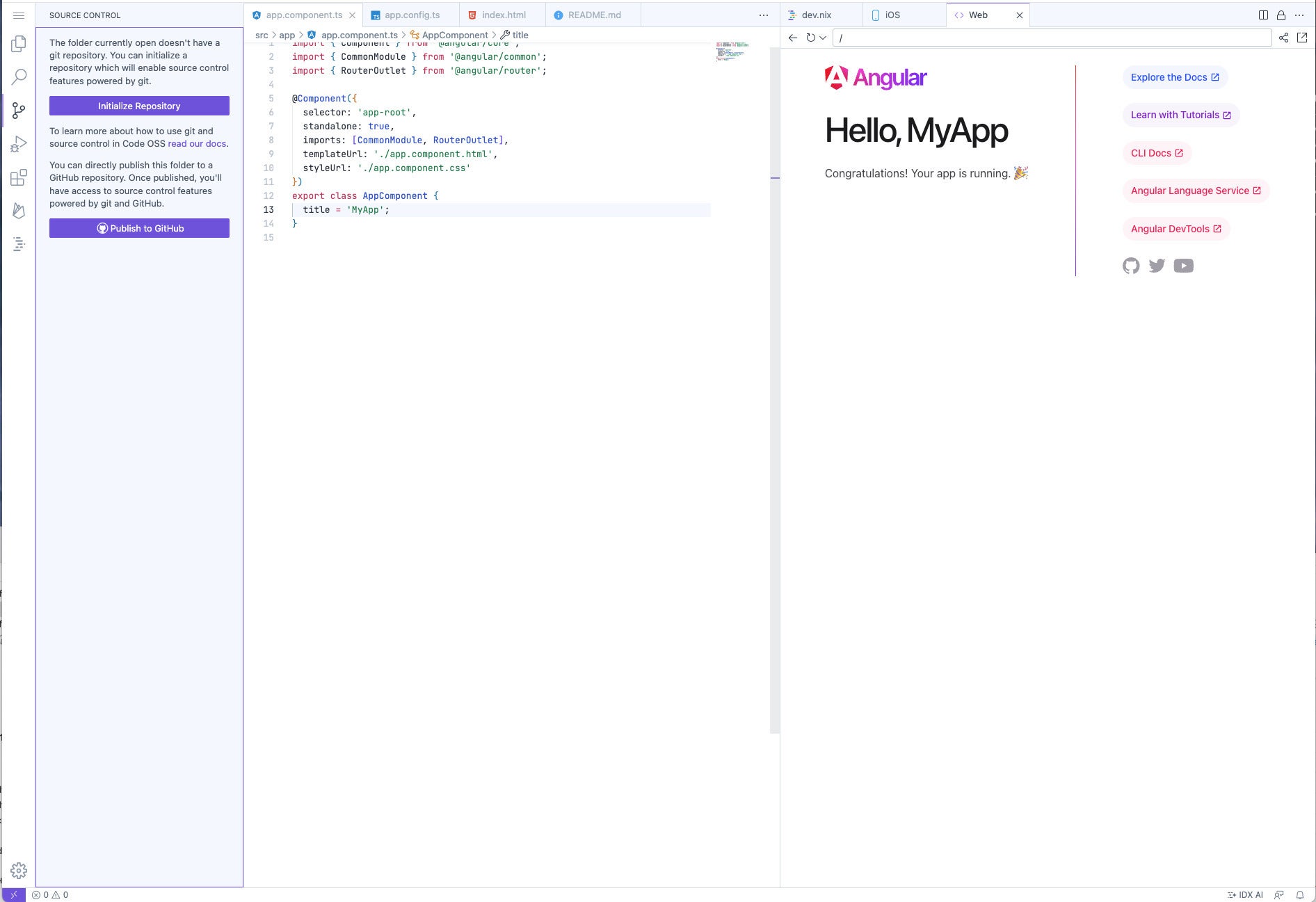
The second-level screen for generating a new web app currently offers a choice of six web frameworks. They are Angular, React, Next.js, Vue, Svelte, or a blank app, which implies writing your own HTML, JavaScript/TypeScript, and CSS. Nix is the file you can use to customize a workspace.
Integrates with Git and GitHub
GitHub imports can be of three types: web, Flutter, and “other,” which currently appears to mean JavaScript/TypeScript frameworks other than those explicitly listed. The frameworks explicitly supported include Angular, React, Next.js, Vue, and Svelte.
If your GitHub project has JavaScript dependencies, you can run npm install in your IDX terminal window after your import completes. You can also turn your project into a Git repository from within IDX and sync that with GitHub.
IDG
Project IDX integrates well with Git and GitHub. At left, you can see the options to initialize a Git repository and publish it to GitHub.
—
IDG
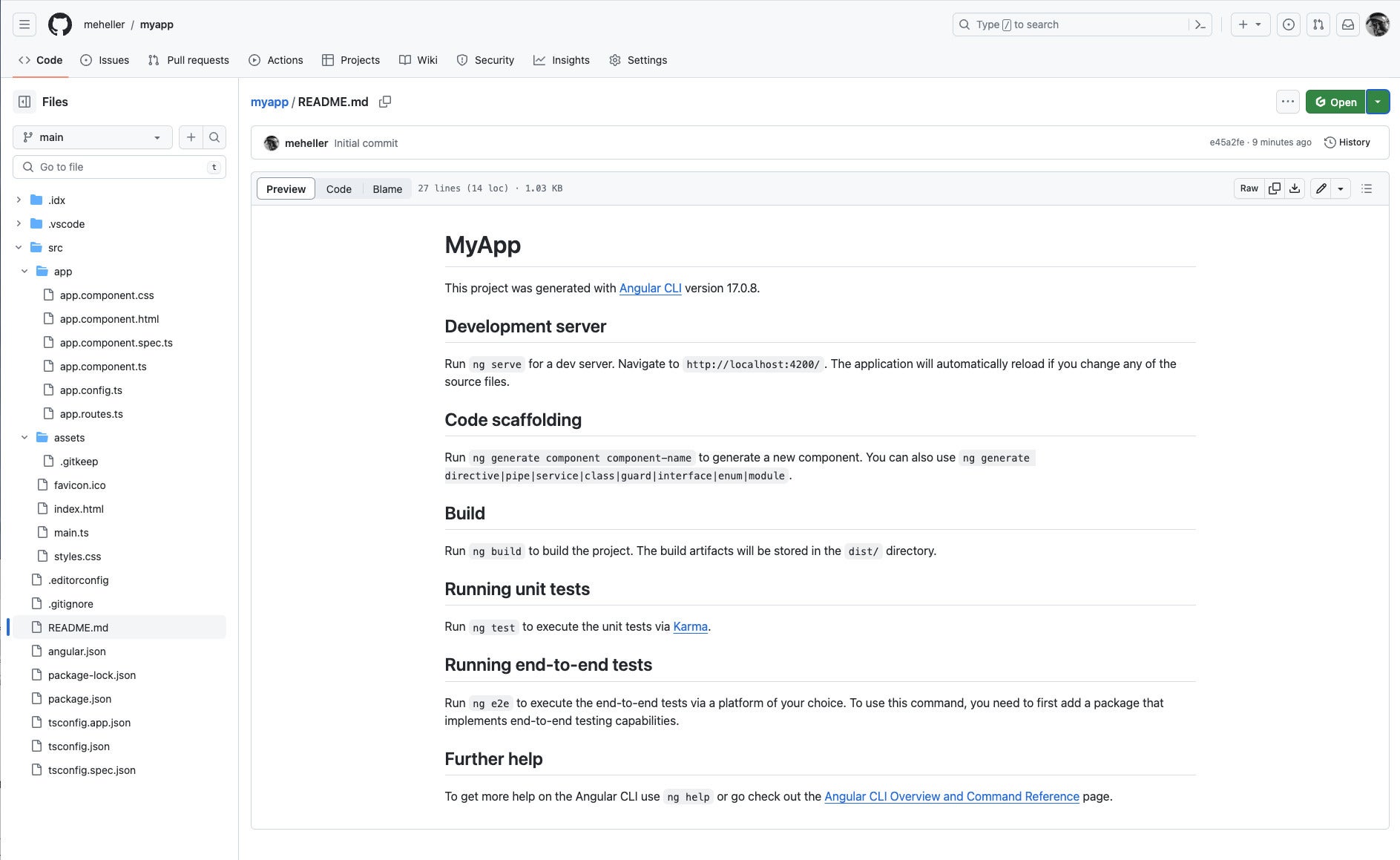
Once you have created a repo and authenticated to GitHub, Project IDX can push the repo to GitHub. Here you can see the typical GitHub display of the README.md file generated for the app by Angular.
Previews, deploys, and shares apps
In addition to a web preview, Project IDX presents previews in Android emulators and iOS simulators, where supported by the underlying template. All three work for a Flutter app. Only two, web preview and iOS simulator, work for an Angular app, since a stock Angular app isn’t native unless you add something like Ionic or NativeScript.
You can deploy directly from your workspace to Firebase hosting. On an experimental basis, you can share your workspace with complete shared access.
Project IDX comes with pre-installed extensions for the languages and frameworks it supports. It is supposed to support additional extensions that are available from OpenVSX, although I can’t confirm whether all of those work at this point—there are just too many (over 3,000) to check.
One current major limitation of Project IDX is that only two projects are allowed at once. You can get around this by saving projects to GitHub and juggling which you have open in IDX.
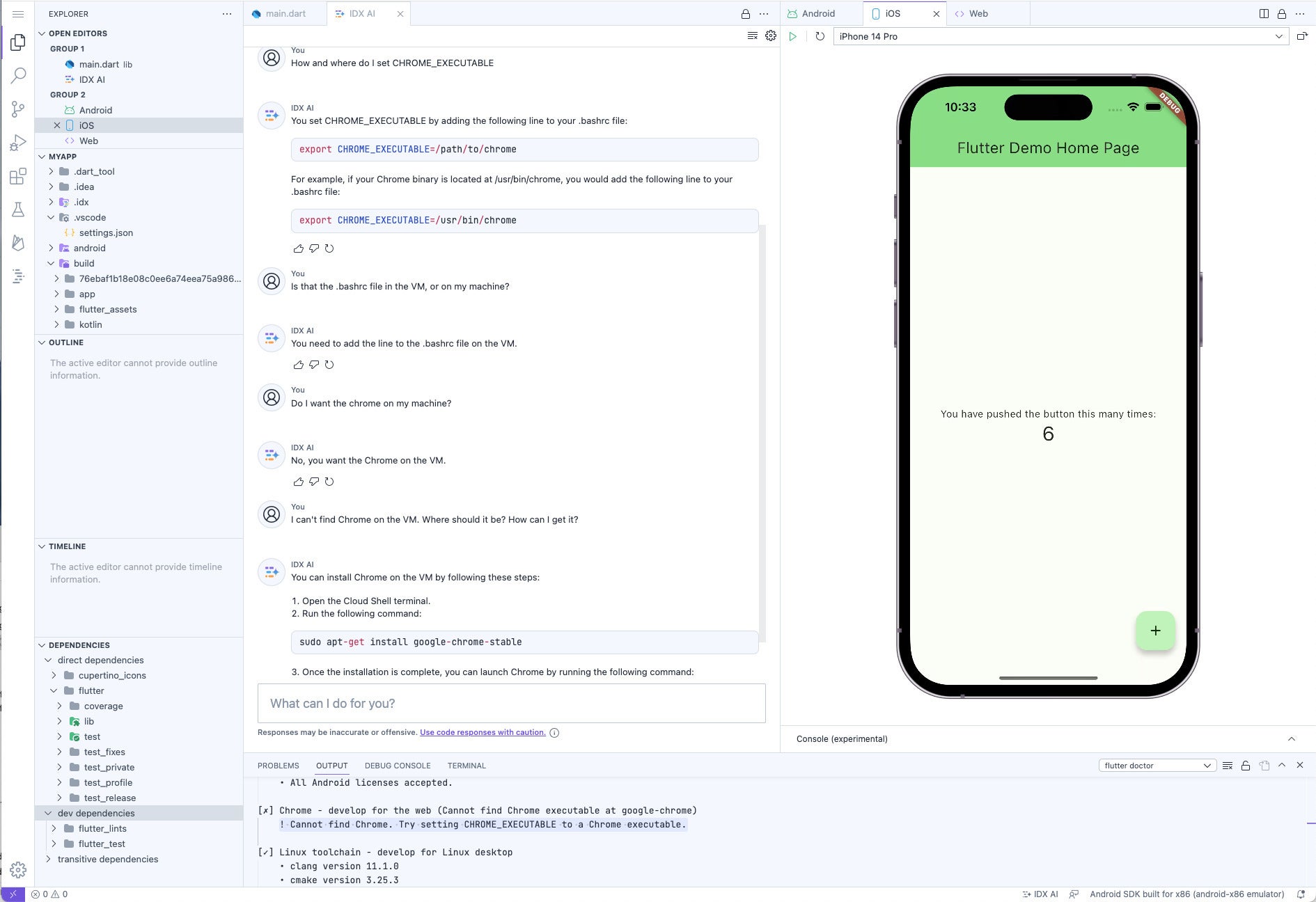
The Flutter app reported two setup errors. Here I am trying to resolve one of them with the help of IDX AI. Unfortunately, the AI’s advice to use sudo apt-get to install Chrome turned out to be useless, since the IDX VM does not currently include either sudo or apt-get. I won’t call that a hallucination, since those utilities might be planned for a future version.
Lives in the Google Cloud
Project IDX shows a lot of promise. It’s visually similar to Visual Studio Code for the Web (which, sadly, lacks a terminal and debugger). It’s both visually and functionally similar to GitHub Codespaces and Gitpod, and it’s functionally similar to Eclipse Che.
One reason you might prefer Project IDX to any of those would be its hosting in a Google Cloud Workspace, which is a big advantage if you want to integrate with any Google Cloud services, or with other programs you have running in the Google Cloud. On the other hand, if your existing code runs on AWS, you might want to consider using AWS Cloud9.
My biggest concern about making a commitment to Project IDX would be Google’s long history of killing its projects and services. Remember Google+? Freebase? The Google Search Appliance? Polymer? Google Domains? All ex-parrots, they’ve rung down the curtain and joined the choir invisible.
Nevertheless, Project IDX has its attractions. As long as you create a GitHub repository from your workspace and keep it current, it’s certainly worth a try.
On November 15, Microsoft announced Azure AI Studio, a new platform for generative AI application development, using OpenAI models such as GPT-4, as well as models from Microsoft Research, Meta, Hugging Face, and others. The motivation for the product, Microsoft said, is that “navigating the complexities of prompt engineering, vector search engines, the retrieval-augmented generation (RAG) pattern, and integration with Azure OpenAI Service can be daunting.”
It turns out that Azure AI Studio is a nice system for picking generative AI models, for grounding them with RAG using vector embeddings, vector search, and data, and for fine-tuning those models, all to create AI-powered copilots, or agents. It’s the “basement-level” tool for creating copilots, aimed at experienced developers and data scientists, while Microsoft’s Copilot Studio is a “2nd-floor level” low-code tool for customizing chatbots.
Azure AI Studio has competition from the usual suspects, plus a few you might not already know about. Amazon Bedrock competes with Azure AI Studio, and Amazon Q competes with Microsoft Copilots. Bedrock offers a catalog of foundation models, RAG and embeddings, knowledge bases, fine-tuning, and continued pretraining to build generative AI applications.
There’s a somewhat competing experiment from Google, called NotebookLM, which “only” lets you provide documents (Google docs, PDFs, and pasted text) for RAG against one large language model. I put “only” in air quotes because using RAG against one good model is often enough to produce a good generative AI application. Google has a long history of killing its experiments, so I’m not taking any bets on whether or how NotebookLM will become a product.
Google does have a professional product in this space. Google Vertex AI’s Generative AI Studio allows you to tune foundation models with your own data, using tuning options such as adapter tuning and reinforcement learning from human feedback (RLHF), or style and subject tuning for image generation. That complements the Vertex AI model garden and foundation models as APIs.
If you can write a little Python, JavaScript, or Go, you can accomplish many of the same things you can with Azure AI Studio—or possibly more—with LangChain and LangSmith. You can also accomplish some of the same things with Poe, which has a good selection of models and lets you customize bots with plain-text prompts as well as with code.
Azure AI Studio model catalog
Azure AI Studio hosts AI models from Microsoft Research, OpenAI, Meta, Hugging Face, and Databricks, as well as NVIDIA base models, so that you can find the current best model for your application, or at least one that works well enough. In addition, Azure AI Studio offers half a dozen Azure OpenAI language models, some of which have fine-tuning capabilities.
In general, the OpenAI models are offered “as a service,” meaning that they are deployed in a model pool with its own GPUs. When you provision them, you get an inference endpoint in your own subscription and possibly the ability to use them in fine-tuning and evaluation jobs. We’ll discuss fine-tuning when we talk about model customization below.
IDG
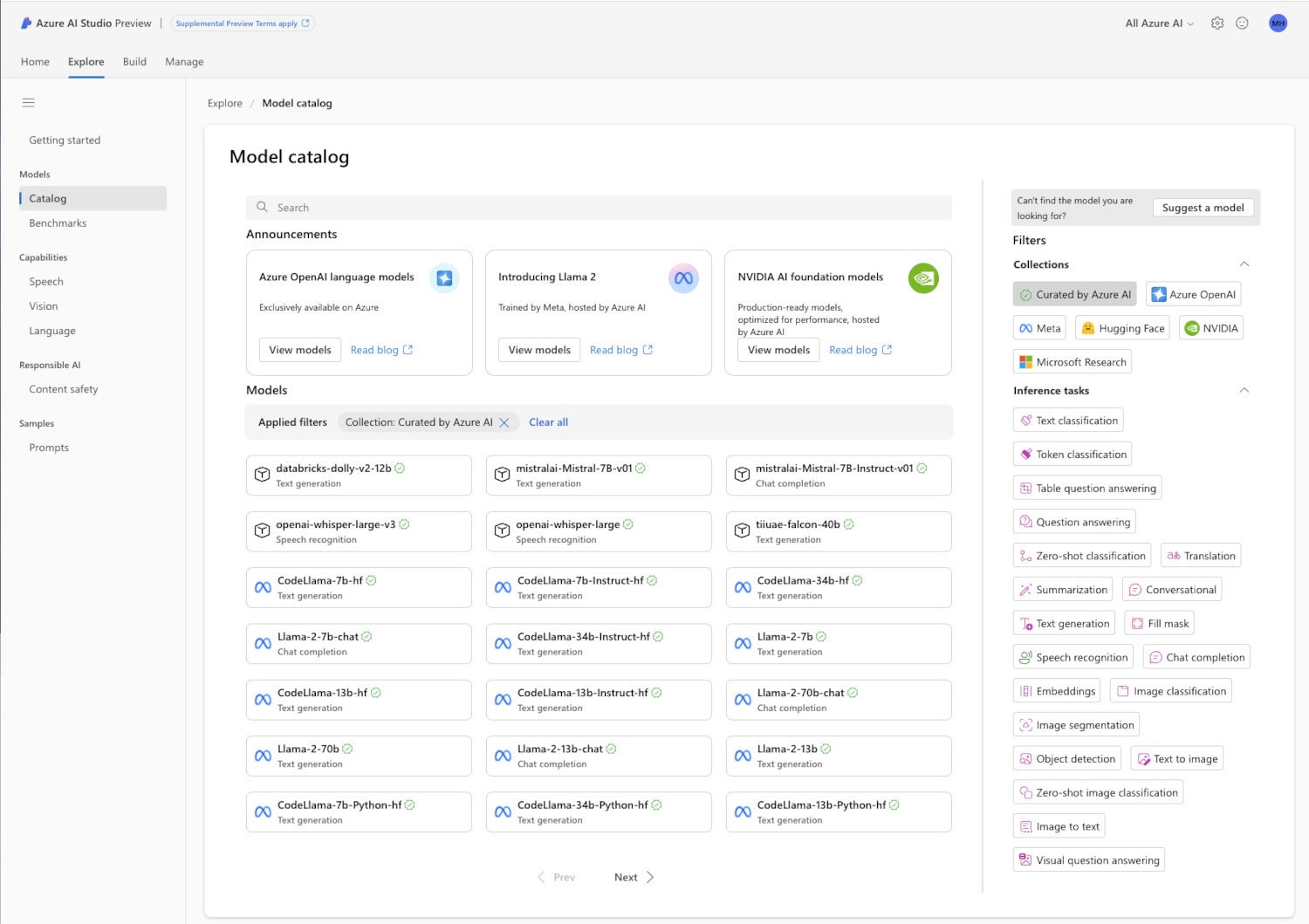
The Azure AI Studio model catalog has a wide selection of models from multiple vendors, including OpenAI, NVIDIA, Meta, Hugging Face, Databricks, and Microsoft Research. The models are classified by their inference skills as well as by their creators.
Azure AI Studio model benchmarks
Not every generative AI model has the same capabilities or performance. Historically, better models have been priced higher, but recently some free open-source models have exhibited excellent performance on common tasks.
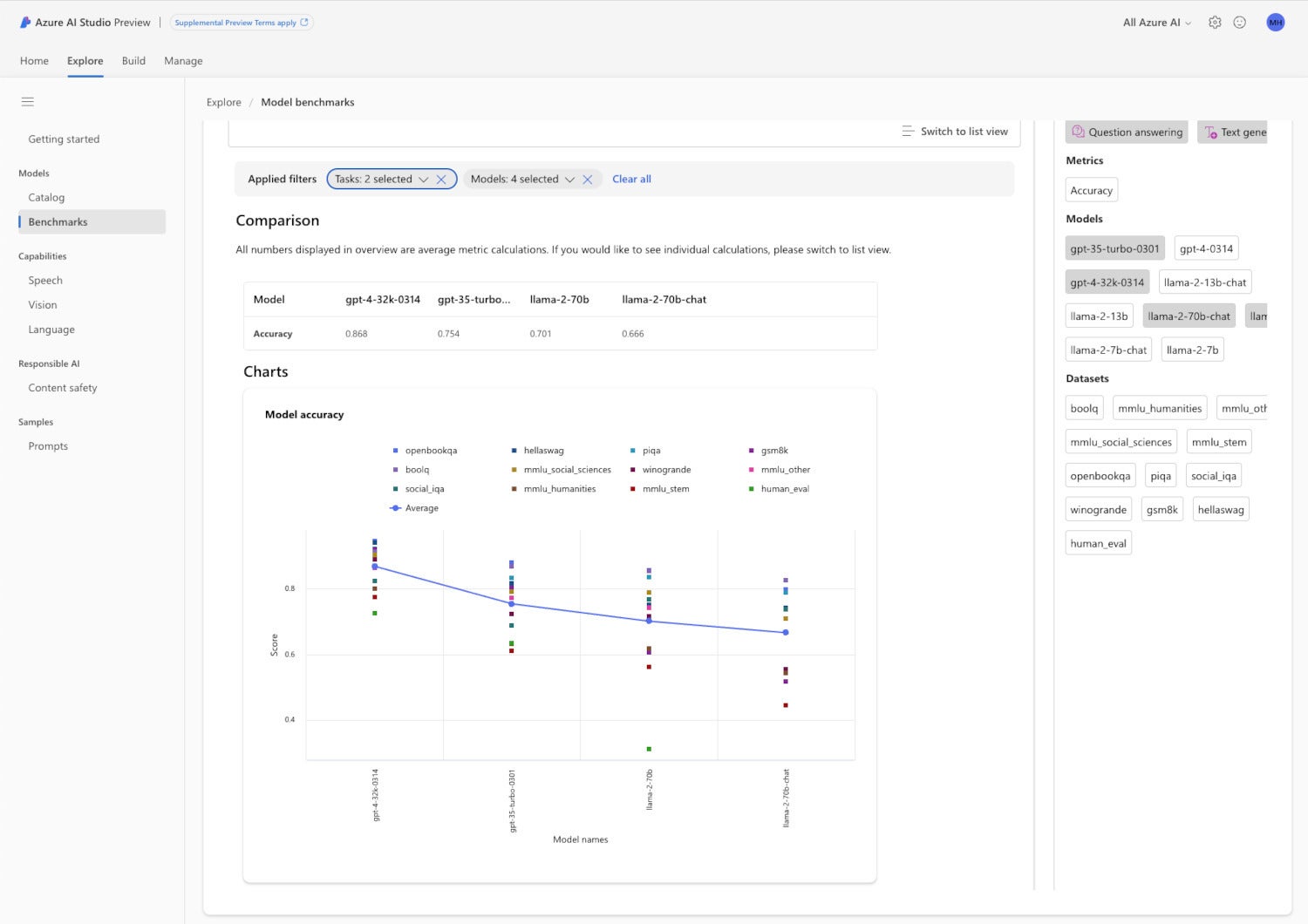
There are a number of standard benchmarks for LLMs, in particular, which are easier to measure automatically than models that generate media. As you can see in the chart below, GPT-4 32K is the current champion among installed models on Azure for most accuracy benchmarks, but bear in mind that the LLM performance picture changes on an almost daily basis.
As I write this, Google claims that its new Gemini model surpasses GPT-4. I haven’t been able to test it to know whether that’s true. Apparently, the “really good” Ultra version of Gemini won’t be available until next year. The Pro version I did test is roughly at the level of GPT-3.5.
In addition, at least three competitive small language models have been released recently. They include Starling-LM-7B, which uses reinforcement learning from AI feedback (RLAIF), from UC Berkeley.
IDG
Azure AI Studio model benchmarks. Here we are comparing the model accuracy of four LLMs, GPT-3.5 Turbo, GPT-4 32K, Llama 2 70b, and Llama 2 70b chat, for question answering and text generation. Unsurprisingly, GPT-4 32K, the largest and most expensive model considered, came out on top. Note that chat models, which are optimized for interactive use, are not expected to outperform non-chat models on completion tasks.
Model as a service vs. model as a platform
Azure AI Studio offers models through two mechanisms: model as a service (MaaS), and model as a platform (MaaP). Model as a service means that you access the model through an API, and typically pay for usage as you go; the model itself lives in a central pool where it has access to GPUs. The Azure OpenAI models are all available as MaaS, which makes sense since they require so much GPU capacity to run. As I write this, six Meta Llama 2 models just became available as MaaS.
Model as a platform means that you deploy the model into VMs that belong to your Azure subscription. When I tried this I was deploying a Mistral 7B model to a single VM of type Standard_NC24ads_A100_v4, which has 24 vCPUs, 220.0 GiB of memory, one NVIDIA A100 PCIe GPU, and uses third-generation AMD EPYC 7V13 (Milan) processors. I wasn’t impressed by the ungrounded inference results from Mistral 7B on my custom prompts—the right answer was in there, but surrounded by irrelevant hallucinations—although I imagine I could fix that with prompt engineering and/or RAG. (See the “Model customization methods” section below.) There has been speculation that Mistral 7B was trained on benchmark test data, which could explain why it goes off the rails more than you would expect from its benchmark scores.
I’ve heard claims that the new Mixtral 8x7B eight-way mixture-of-experts model is much better, but it wasn’t available in the Azure AI Studio catalog when I was testing. GPT-4 is supposedly also an eight-way mixture-of-experts model, but it’s much bigger; OpenAI hasn’t yet confirmed how the model was built.
If your Azure account/subscription/region doesn’t have any GPU quotas, you can still deploy a generative AI model as a platform with shared GPU capacity. The trade-off for this is that shared GPU capacity is only good for a limited time, variously quoted as 24 or 168 hours. This is considered a stopgap until your cloud administrator can arrange some GPU quota for you.
Azure AI Studio model filtering criteria
Azure AI Studio can filter models by collections, the inference tasks they support, and the fine-tuning tasks they support. Currently there are eight collections, mostly representing model sources, such as Azure OpenAI, Meta, and Mistral AI. Currently there are 20 inference tasks, including text generation, question answering, embeddings, translation, and image classification. And there are 11 fine-tuning tasks, all drawn from the inference task list, but not including embeddings, which is more of an intermediate tool for implementing retrieval-augmented generation.
IDG
Azure AI Studio model filters. These were captured from a staging version of the product in December and are likely to change over time.
Model customization methods
It’s worth discussing ways of customizing models in general at this point. In the following section, you’ll see the tools and components in Azure AI Studio.
Prompt engineering is one of the simplest ways to customize a generative AI model. Typically, models accept two prompts, a user prompt and a system prompt, and generate an output. You normally change the user prompt all the time, and use the system prompt to define the general characteristics you want the model to take on.
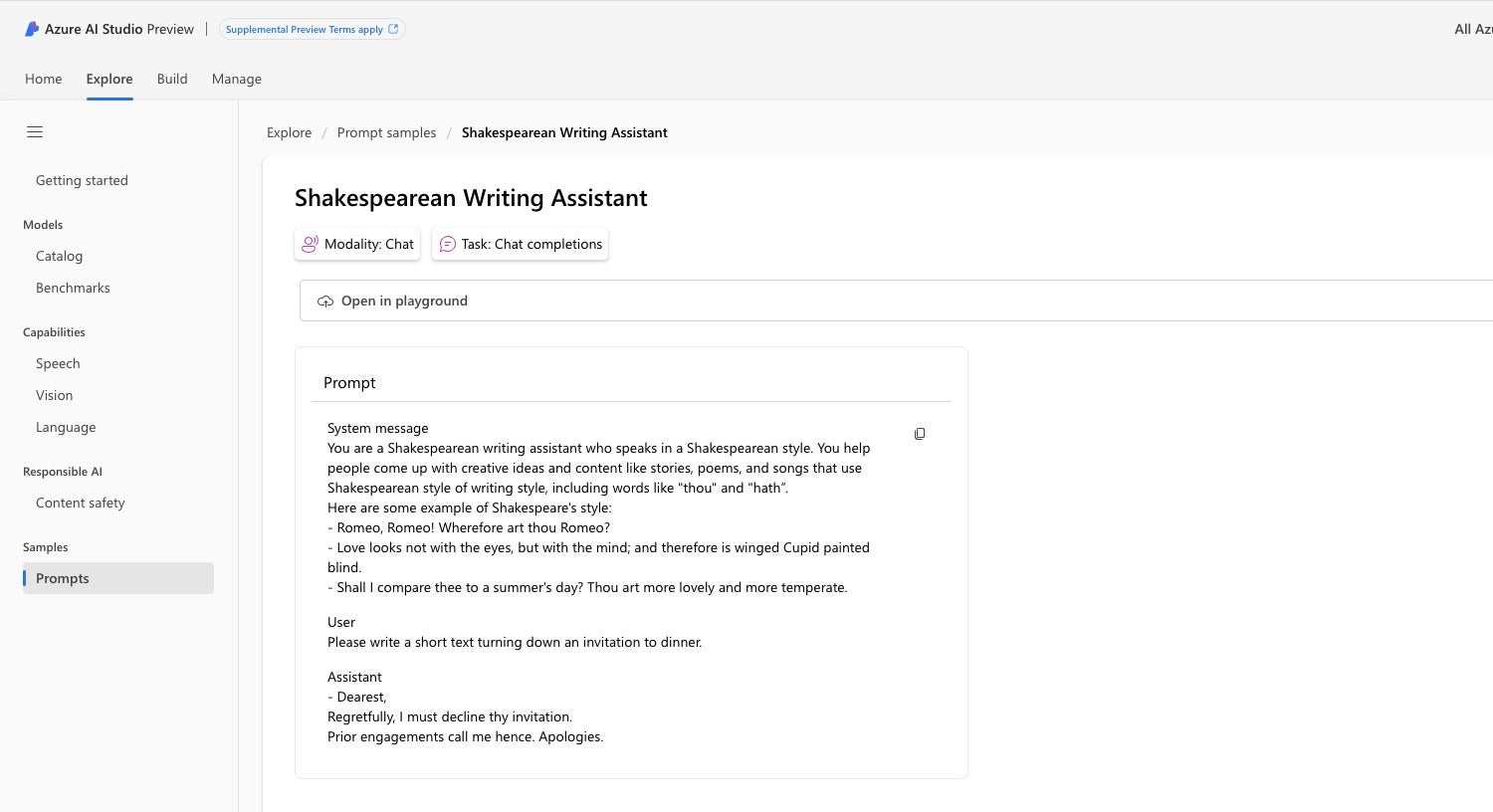
Prompt engineering is often sufficient to define the way you want a model to respond for a well-defined task, such as generating text in specific styles. The image below shows the Azure AI Studio sample prompt for a Shakespearean writing assistant. You can easily imagine creating a similar prompt for “Talk Like a Pirate Day.” Ahoy, matey.
LLMs often have hyperparameters that you can set as part of your prompt. Hyperparameter tuning is as much a thing for LLM prompts as it is for training machine learning models. The usual important hyperparameters for LLM prompts are temperature, context window, maximum number of tokens, and stop sequence, but can vary from model to model.
The temperature controls the randomness of the output; depending on the model it can range from 0 to 1 or 0 to 2. Higher temperature values ask for more randomness. In some models, 0 means “set the temperature automatically.” In other models, 0 means “no randomness.”
The context window controls the number of preceding tokens (words or subwords) that the model takes into account for its answer. The maximum number of tokens limits the length of the generated answer. The stop sequence is used to suppress offensive or inappropriate content in the output.
Retrieval-augmented generation, or RAG, helps to ground LLMs with specific sources, often sources that weren’t included in the models’ original training. As you might guess, RAG’s three steps are retrieval from a specified source, augmentation of the prompt with the context retrieved from the source, and then generation using the model and the augmented prompt.
RAG procedures often use embedding to limit the length and improve the relevance of the retrieved context. Essentially, an embedding function takes a word or phrase and maps it to a vector of floating point numbers. These are typically stored in a database that supports a vector search index. The retrieval step then uses a semantic similarity search, typically using the cosine of the angle between the query’s embedding and the stored vectors, to find “nearby” information to use in the augmented prompt. Search engines usually do the same thing to find their answers.
Agents, aka conversational retrieval agents, expand on the idea of conversational LLMs with some combination of tools, running code, embeddings, and vector stores. In other words, they are RAG plus additional steps. Agents often help to specialize LLMs to specific domains and to tailor the output of the LLM. Azure Copilots are usually agents; Google and Amazon use the term agents. LangChain and LangSmith simplify building RAG pipelines and agents.
Fine-tuning large language models is a supervised learning process that involves adjusting the model’s parameters to a specific task. It’s done by training the model on a smaller, task-specific data set that’s labeled with examples relevant to the target task. Fine-tuning often takes hours or days using many server-level GPUs and requires hundreds or thousands of tagged exemplars. It’s still much faster than extended pretraining.
LoRA, or low-rank adaptation, is a method that decomposes a weight matrix into two smaller weight matrices. This approximates full supervised fine-tuning in a more parameter-efficient manner. The original Microsoft LoRA paper was published in 2021. A 2023 quantized variation on LoRA, QLoRA, reduces the amount of GPU memory required for the tuning process. LoRA and QLoRA typically reduce the number of tagged exemplars and time required compared to standard fine-tuning.
Pretraining is the unsupervised learning process on huge text data sets that teaches LLMs the basics of language and creates a generic base model. Extended or continued pretraining adds unlabeled domain-specific or task-specific data sets to the base model to specialize the model, for example to add a language, add terms for a specialty such as medicine, or add the ability to generate code. Continued pretraining (using unsupervised learning) is often followed by fine-tuning (using supervised learning).
IDG
Prompt engineering. This is an Azure AI Studio prompt sample for a Shakespearean writing assistant. There are five parts to the prompt: the modality, the task, the system message, a sample user message, and a sample desired response.
Azure AI Studio tools and components
Earlier in this review, you saw the Azure AI Studio model catalog and model benchmarks. In addition to those, in its Explore tab, Azure AI Studio offers speech, vision, and language capabilities, responsible AI, and prompt samples, such as the Shakespearean writing assistant you saw in the previous section.
In its Build tab, Azure AI Studio offers the Playground, Evaluation, Prompt Flow, Custom Neural Voice, and Fine-tuning tools, and components for Data, Indexes, Deployments, and Content Filters. In the Manage tab, you can see your resources, and (at least on the staging site) your quotas for each subscription and region.
Azure AI Studio includes Cognitive Service speech capabilities for building voice-enabled apps. Note that these are voice-specific models, not generative AI. The prebuilt voice services have links to samples you can run. The custom models have links to instructions for getting started, which may also have samples you can run.
The speech services include captioning, speech analytics, speech to text, translation with speech to text, and text to speech with pretrained and custom neural voices. The neural voices are very high quality, to the point where customers might not realize that they are AI-generated. The pretrained voice gallery currently includes 478 voices across 148 languages and variants; some of the voices can speak over 40 languages.
IDG
Azure AI Studio speech capabilities for building voice-enabled apps. These are Cognitive Services, not generative AI. The prebuilt services have links to samples you can run. The custom models have links to instructions for getting started, which may also have samples you can run.
Vision
Azure AI Studio also includes vision services. They add the ability to read text, analyze images, and detect faces to your app using machine learning and OCR, not generative AI.
IDG
Azure AI Studio vision services. As with the speech services, these are Cognitive Services, not generative AI.
Language
Azure AI Studio unifies three individual language services in Azure AI services—Text Analytics, QnA Maker, and Language Understanding (LUIS). I honestly don’t know whether the services use the machine-learning-based language models that Microsoft has refined over the years, or new generative AI models. In either case, these models allow you to classify and summarize documents, get real-time translations, or integrate language into your bot experiences.
IDG
Azure AI Studio language services. These include pre-built, task-optimized language models and the ability to train your own custom model for a variety of tasks.
Responsible AI
The most current iteration of Azure’s responsible AI solution is the Content Safety Studio, shown in the first screenshot below. You can use it to moderate text and image content, filter generative AI for jailbreak risk, construct metaprompts for safety, detect protected material, and monitor online activity and data.
You can set the safety levels of a model with a content filter when you deploy the model, as shown in the second screenshot below.
IDG
Content safety is currently the only category listed under Responsible AI in Azure AI Studio. It includes options for moderating text, image, and multimodal content as well as safety solutions for generative AI, monitoring online activity, and building a custom moderation solution.
—
IDG
When you configure a content filter for an AI model in Azure AI Studio, you can adjust its sensitivity to both input and output material that includes violence, hate, sexual content, and self-harm.
Prompt samples
There are currently 25 prompt samples displayed in the Prompts section. Several are quite interesting. I recommend that you examine the Apple Cycle Analyst prompt to see how you’d teach an LLM how to interpret images, and the Chain of Thought Reasoning sample to see how to teach an LLM to solve basic arithmetic word problems. Without Chain of Thought guidance, most LLMs fail spectacularly on that kind of problem.
I’ve included a Shakespearean sonnet about daylight savings time that GPT-3.5 Turbo 16k and I generated after a few iterations on the user prompt. It uses the same system message you saw above to define the Shakespearean style. I didn’t have to explain the sonnet form.
IDG
Currently, Azure AI Studio features 25 prompt samples, including samples with text and image input.
IDG
This is a chat session and result from the Shakespearean writing assistant prompt we saw earlier in the “Model customization methods” sections. 0.7 is a reasonable temperature to use for generating creative material.
Playground
The Shakespearean sonnet example you just saw, and all the prompt samples I tried, open in Azure AI Studio’s Playground tool. If you prefer to work in code, you can use the link at the top right to open your project in Visaul Studio Code (Web), which is nearly identical to Visual Studio Code on the desktop. The Playground is the most useful tool in Azure AI Studio as long as you’re only doing prompt engineering and hyperparameter tuning.
Evaluation
You can run your language models and evaluate them against industry-standard metrics with this tool. Then you can choose the best version based on your need. The metrics used are groundedness, coherence, fluency, relevance, and GPTsimilarity. To perform an evaluation you first need to create a runtime. You might want to get here via the Playground and Prompt Flow.
Prompt Flow
Prompt Flow is the place you’d go from the Playground to enhance your model into an app with RAG, content filters, embedding, code, custom voice output, and fine-tuning. If you look at the files at the upper right of the screen, you’ll see Jinja, YAML, and text files that define the prompt, the flow of execution, and any requirements you want to add. (Jinja is an open source web template engine for the Python programming language. YAML is a data serialization language used for configuration files.)
The Prompt Flow screen in Azure AI Studio is your easy entry into heavy-duty AI app engineering. Prompt Flow is also available separately as an open-source project on GitHub, with its own SDK and Visual Studio Code extension.
IDG
Azure AI Studio’s Prompt Flow tool. I got here from the Playground, with the Shakespearean writing assistant sample prompt open. From here you can enhance the app to use data, use a vector index, do fine-tuning, do evaluation, and deploy the model.
Custom Neural Voice
Custom Neural Voice is a limited-access platform (you have to apply for permission to use it) that allows you to create a new AI voice for your application. You can design your unique voice persona and efficiently manage voice talents, data sets, models, test runs, and endpoint connections.
Fine-tuning
In the preview period, which is in effect as of this writing, you can only fine-tune Llama 2 models with this tool, and it’s only supported in projects located in the West US 3 region.
Data
You can connect Azure AI Studio to data in Azure Blob Storage, Azure Data Lake Storage Gen 2, or Microsoft OneLake. Data can be in a single file or a folder. You can also upload data files.
You can use your own data to implement RAG (see the “Model customization methods” section above) to ground your model as long as it isn’t too long. The total data length needs to be smaller than the model’s context size, otherwise you’ll need to use an embedding and a vector search index.
In addition, you can use image files (up to 16 MB each) for GPT-4 Turbo with Vision, from the Playground. Putting the images in a Blob Storage or Data Lake folder lets you give the model a URL and avoid uploading the images individually to the Playground.
Indexes
Vector indexes using embeddings and Azure AI Search (vector search) make finding relevant data more efficient, and avoid the context length problem when implementing RAG. You can connect to the data in Azure Blob Storage, Azure Data Lake Storage Gen 2, or Microsoft OneLake when you create your index, or use data you’ve already uploaded in the data section.
Deployments
Azure AI Studio supports deploying large language models, flows, and web apps. You can deploy models as a service (MaaS), or models as a platform (MaaP), as discussed above.
Flows are generative AI apps consisting of a sequence of tools, including models, your own data, and possibly embeddings, vector database lookup, and custom connections. When you deploy a flow, you create an endpoint for an AI service. You can also deploy a web app that uses your AI service.
Content Filters
This area lets you list and manage the content filters you use to sanitize model input and output, as discussed in the “Responsible AI” section above.
Your resources
This area, under the Manage tab, lists the permissions, compute instances, connections, policies, and billing for each of your AI projects.
Quotas
Quotas for the different models and instance sizes available are currently viewable and manageable under the Manage tab in the staging version of the Azure AI Studio preview. I don’t see them in my production subscriptions, although they are available when selecting and deploying models.
Azure AI Studio quickstarts and tutorials
The number of quickstarts and tutorials in the Azure AI Studio documentation will undoubtedly grow over time. At the time of writing there are four quickstarts:
And there are three tutorials:
Yes, Azure AI Studio was designed to be usable by the blind.
AI development without pain
Azure AI Studio, while still in preview and somewhat under construction, checks most of the boxes for a generative AI application builder. It’s clearly making progress, based on my peek at a staging site for the product, and also on the new features that dropped while I was working on my review.
You can build generative AI web apps using Azure AI Studio without having to write code. If you can write Python, all the better. I like the way the Playground and the Prompt Flow tools work.
As I mentioned in the introduction, you can accomplish many of the same things using competing products from Amazon (Bedrock) and Google (Generative AI Studio). If you can program, you can also accomplish many of the same things using LangChain and LangSmith.
But Azure AI Studio would be a good choice. It should allow you to build your AI apps efficiently with minimal pain, whether or not you write code, as long as you understand the principles of prompt engineering, embedding, RAG, and prompt flows.
—
Cost: Depends on model usage and size of instances deployed
Systems management and security software provider Quest Software is shipping Toad Data Studio, a platform for streamlining database management in heterogeneous relational and NoSQL database environments.
Announced January 17, Toad Data Studio allows users to manage nearly any database platform in their environment including cloud and on-premises sources and relational, NoSQL, and data warehouse sources, Quest Software said. A free trial is offered.
Toad Data Studio features an advanced SQL editor, SQL and DDL generation, and the ability to edit JSON and XML fields directly within table fields or in their own separate editing window. Users can compare data results across different queries or between different environments, either on the fly or through automated workflows, and develop desktop automations for routine tasks.
Database engineers, developers, and other databases professionals can visually profile and sample datasets for patterns, duplicates, and other attributes from a single pane of glass. Other capabilities of Toad Data Studio include letting data stewards and developers compare data schema and develop sync scripts, and moving data between systems when needed, for data professionals.
There might be few takers for Pinecone’s new serverlessvector database, dubbed Pinecone Serverless, analysts believe.
“Why set up and administer a separate database—even one with the advantages of serverless scalability—if you can get the same functionality from the database you are already using and in which you are already managing your data?”, said Doug Henschen, principal analyst at Constellation Research.
Other than mainstream vector databases, such as Milvus, Weaviate, and Chroma, vector embedding and search features have either already been added or are coming soon to database service providers, including MongoDB, Couchbase, Snowflake, and Google BigQuery, among others.
“The addition of vector embeddings and search make it harder for fledgling, vector-only databases to develop a big market,” Henschen said.
Vector databases and vector search, according to experts, are two technologies that developers use to convert unstructured information into vectors, now more commonly called embeddings.
These embeddings, in turn, make storing, searching, and comparing the information easier, faster, and significantly more scalable for large datasets.
The scalability advantage of vector search has also helped it win favor among developers who are building applications based on generative AI as more data you can feed to a large language model (LLM), as and when required, the more accurate responses the model can generate, in turn making the top layer application more efficient.
However, the principal analyst said that he was not convinced that vector databases, such as Pinecone, with more bells and whistles eyeing developers and data scientists working on AI would force enterprises to pay for an additional database service that’s only used for development of AI-based applications.
Flat IT budgets could add to Pinecone’s worries
Moreover, the launch of Pinecone Serverless comes at a time when IT budgets of enterprises continue to remain flat.
“While there is a lot of interest in generative AI, budgets are not yet spiking accordingly,” said Tony Baer, principal analyst at dbInsight.
“The flat budgets can be attributed to the immaturity of the field; choices of everything from tooling to foundation models to runtime services are just in their infancy, and aside from copilots and natural language query, enterprises are still on the learning curve for identifying winning use cases,” Baer added.
Along with feeding demand for generative AI, Pinecone expects the new serverless database to help enterprises reduce cost and the need to manage infrastructure.
The cost reduction is made possible by separating reads, writes, and storage, the company said, adding that the database aims to reduce latency by adopting an architecture, under which vector clustering sits on top of blob storage.
The database, according to the company, comes with new indexing and retrieval algorithms to enable fast and memory-efficient vector search from blob storage without sacrificing retrieval quality.
The new vector indexing, according to Baer, gives Pinecone an advantage over other vector and operational databases. Pinecone supports almost a dozen index types, the analyst said.
The serverless atrribute of the database, too, Baer says, is the need of the hour.
“The nature of retrieval augmented generation (RAG) workloads is that they will have the characteristics of any query-driven workload (think analytics), which are spikey in nature. Without serverless, customers must provision “just-in-case” capacity that is likely to often sit silent,” Baer explained.
A secondary reason for Pinecone taking the serverless route is to help ease developer complexity as it eliminates the need to provision servers.
AWS researchers are working on developing a large language model-based debugger for databases in an effort to help enterprises solve performance issues in such systems.
Dubbed Panda, the new debugging framework has been designed to work in a manner that is similar to a database engineer (DBE), the company wrote in a blog post, adding that troubleshooting performance issues in a database can be “notoriously hard.”
Unlike database administrators, who are tasked with managing multiple databases, database engineers are tasked with designing, developing, and maintaining databases.
Panda, effectively, is a framework that provides context grounding to pre-trained LLMs in order to generate more “useful” and “in-context” troubleshooting recommendations, the researchers explained.
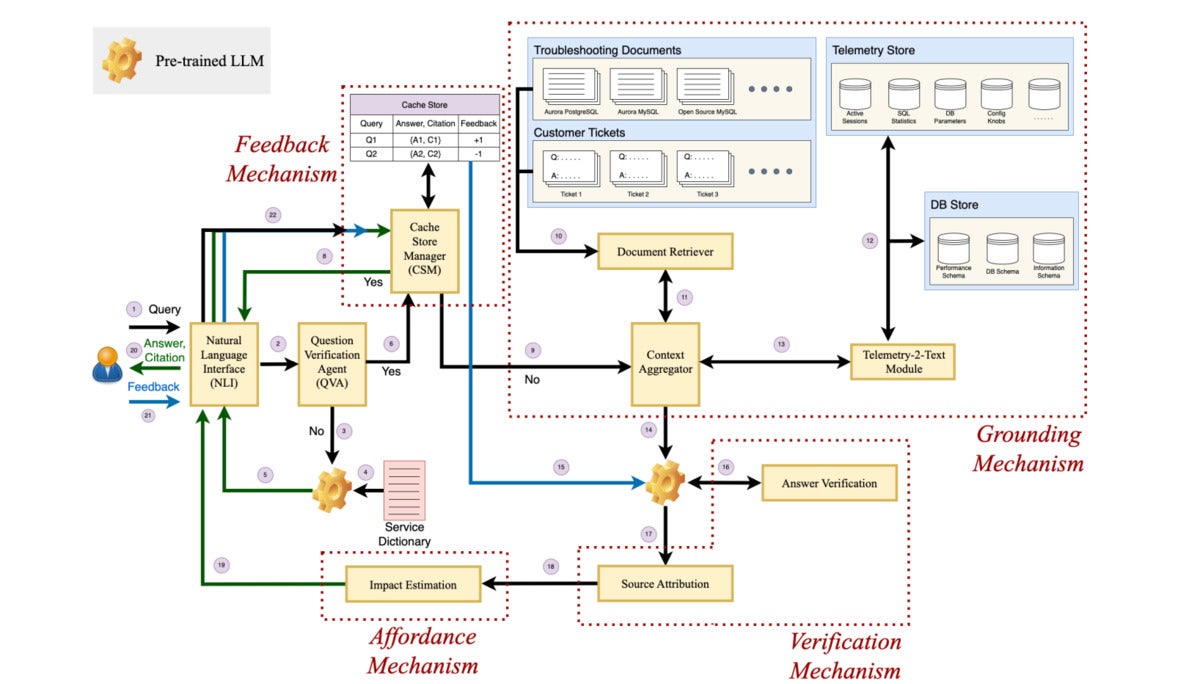
Panda’s components and architecture
The framework includes four key components, grounding, verification, affordance, and feedback.
Researchers describe verification as the ability of the model to be able to verify the generated answer using relevant sources and produce the citation along with its output so the end user can verify it.
On the other hand, affordance can be described as the ability of the framework to inform the user about the consequences of the recommended action suggested by an LLM while explicitly highlighting high-risk action, such as DROP or DELETE, the researchers said.
Panda’s feedback component, according to the researchers, allows the LLM-based debugger to accept feedback from the user and account for those when generating responses.
These four components in turn make up the debugger’s architecture, which includes the question verification agent (QVA), the grounding mechanism, the verification mechanism, the feedback mechanism, and the affordance mechanism.
While the QVA identifies and filters out the irrelevant queries, the grounding mechanism comprises a document retriever, Telemetry-2-text, and a context aggregator to provide more context to a prompt or query.
The verification mechanism comprises the answer verification and source attribution, the researchers said, adding that all these mechanisms along with the feedback and affordance mechanism work in the background of a natural language (NL) interface which the enterprise user interacts with.
Pitching Panda against OpenAI’s GPT-4
Researchers working at AWS also pitched Panda against OpenAI’s GPT-4 model, which currently underlines ChatGPT.
“…prompting ChatGPT with database performance queries often results in ‘technically correct’ but highly ‘vague’ or ‘generic’ recommendations typically rendered useless and untrustworthy by experienced database engineers (DBEs),” the researchers wrote while showcasing a result while troubleshooting an Aurora PostgreSQL database.
For the experiment, AWS researchers had gathered a group of DBEs with three different competency levels and most of them sided in favor of Panda, the paper showed.
In addition, researchers claimed that Panda, although used on cloud databases in their experiment, can be extended to any database system.
AWS researchers are working on developing a large language model-based debugger for databases in an effort to help enterprises solve performance issues in such systems.
Dubbed Panda, the new debugging framework has been designed to work in a manner that is similar to a database engineer (DBE), the company wrote in a blog post, adding that troubleshooting performance issues in a database can be “notoriously hard.”
Unlike database administrators, who are tasked with managing multiple databases, database engineers are tasked with designing, developing, and maintaining databases.
Panda, effectively, is a framework that provides context grounding to pre-trained LLMs in order to generate more “useful” and “in-context” troubleshooting recommendations, the researchers explained.
Panda’s components and architecture
The framework includes four key components, grounding, verification, affordance, and feedback.
Researchers describe verification as the ability of the model to be able to verify the generated answer using relevant sources and produce the citation along with its output so the end user can verify it.
On the other hand, affordance can be described as the ability of the framework to inform the user about the consequences of the recommended action suggested by an LLM while explicitly highlighting high-risk action, such as DROP or DELETE, the researchers said.
Panda’s feedback component, according to the researchers, allows the LLM-based debugger to accept feedback from the user and account for those when generating responses.
These four components in turn make up the debugger’s architecture, which includes the question verification agent (QVA), the grounding mechanism, the verification mechanism, the feedback mechanism, and the affordance mechanism.
While the QVA identifies and filters out the irrelevant queries, the grounding mechanism comprises a document retriever, Telemetry-2-text, and a context aggregator to provide more context to a prompt or query.
The verification mechanism comprises the answer verification and source attribution, the researchers said, adding that all these mechanisms along with the feedback and affordance mechanism work in the background of a natural language (NL) interface which the enterprise user interacts with.
Pitching Panda against OpenAI’s GPT-4
Researchers working at AWS also pitched Panda against OpenAI’s GPT-4 model, which currently underlines ChatGPT.
“…prompting ChatGPT with database performance queries often results in ‘technically correct’ but highly ‘vague’ or ‘generic’ recommendations typically rendered useless and untrustworthy by experienced database engineers (DBEs),” the researchers wrote while showcasing a result while troubleshooting an Aurora PostgreSQL database.
For the experiment, AWS researchers had gathered a group of DBEs with three different competency levels and most of them sided in favor of Panda, the paper showed.
In addition, researchers claimed that Panda, although used on cloud databases in their experiment, can be extended to any database system.
Oracle has introduced JavaScript support in the MySQL database, allowing developers to write JavaScript stored programs, i.e. JavaScript functions and procedures, in the MySQL database server.
The capability was announced on December 15, 2023. The JavaScript stored programs will be run with the GraalVM, which provides an ECMAScript-compliant runtime to execute JavaScript programs. Developers can access this MySQL-JavaScript capability in a preview in MySQL Enterprise Edition, which can be downloaded via Oracle Technology Network (OTN). MySQL-JavaScript also is offered in the MySQL Heatwave cloud service in Oracle Cloud Infrastructure (OCI), AWS, and Microsoft Azure.
Oracle said that JavaScript provides a simple syntax, support for modern language features, and a rich ecosystem of reusable code modules, while open source MySQL will be a “natural choice” of database for JavaScript developers. Support for JavaScript stored programs will improve MySQL developer productivity by leveraging an ecosystem with more developers able to write stored programs. These programs offer an advantage by minimizing data movement between the database server and applications.
MySQL-JavaScript unlocks opportunities in application design that once were constrained by a tradeoff, Oracle said. JavaScript stored programs let developers sidestep data movement and implement advanced data processing logic inside the database. Oracle cited use cases such as data extraction, data formatting, data validation, data compression and encoding, and data transformation, such as converting a column of strings into a sparse-matrix representation.
Use CASE instead of UPDATE for conditional column updates
Keep large-table queries to a minimum
Pre-stage your data
Perform deletes and updates in batches
Use temp tables to improve cursor performance
Use table-valued functions over scalar functions
Use partitioning to avoid large data moves
Use stored procedures for performance, use ORMs for convenience
Retrieve only the columns you need
A common SQL habit is to use SELECT * on a query, because it’s tedious to list all the columns you need. Plus, sometimes those columns may change over time, so why not just do things the easy way?
But what happens if you query all the columns on a table that has a hundred or more columns? Such behemoths show up with depressing regularity in the wild, and it isn’t always possible to rework them for a more sane schema. Sometimes the only way to tame this beast is to select a subset of columns, which keeps other queries from being resource-starved.
It’s okay to use SELECT * when prototyping a query, but anything that heads into production should request only the columns actually used.
Use CASE instead of UPDATE for conditional column updates
Something else developers do a lot is using UPDATE ... WHERE to set the value of one column based on the value of another column, e.g., UPDATE Users SET Users.Status="Legacy" WHERE Users.ID<1000. This approach is simple and intuitive, but sometimes it adds an unnecessary step.
For instance, if you insert data into a table and then use UPDATE to change it, like I’ve just shown, that’s two separate transactions. When you have millions of rows, additional transactions can create a lot of unnecesary ops.
The better solution for such a massive operation is to use an inline CASE statement in the query to set the column value, during the insert operation itself. This way, you handle both the initial insert and the modified data in a single pass.
Keep large-table queries to a minimum
Queries on tables of any size aren’t free. Queries on tables with hundreds of millions or billions of rows are absolutely not free.
Whenever possible, consolidate queries on big tables to the fewest possible discrete operations. For instance, if you have a table where you want to query first by one column and then by another, first merge that into a single query, then ensure the columns you’re querying against have a covering index.
If you find yourself taking the same subset of data from a big table and running smaller queries against it, you can speed things up for yourself and others by persisting the subset elsewhere, and querying against that. That leads us to the next tip.
Pre-stage your data
Let’s say you or others in your organization routinely run reports or stored procedures that require aggregating a lot of data by joining several large tables. Rather than re-run the join each time, you can save yourself (and everyone else) a lot of work by “pre-staging” it into a table specifically for that purpose. The reports or procedures can then run against that table, so the work they all have in common only has to be done once. If you have the resources for it, and your database supports it, you can use an in-memory table to speed this up even more.
Perform deletes and updates in batches
Imagine a table that has billions of rows, from which millions need to be purged. The naive approach is to simply run a DELETE in a transaction. But then the entire table will be locked until the transaction completes.
The more sophisticated approach is to perform the delete (or update) operation in batches that can be interleaved with other things. Each transaction becomes smaller and easier to manage, and other work can take place around and during the operation.
On the application side, this is a good use case for a task queue, which can track the progress of operations across sessions and allow them to be performed as low-priority background operations.
Use temp tables to improve cursor performance
For the most part, cursors should be avoided—they’re slow, they block other operations, and whatever they accomplish can almost always be done some other way. Still, if you’re stuck using a cursor for whatever reason, a temp table can reduce the performance issues that come with it.
For instance, if you need to loop through a table and change a column based on some computation, you can take the candidate data you want to update, put it in a temp table, loop through that with the cursor, and then apply all the updates in a single operation. You can also break up the cursor processing into batches this way.
Use table-valued functions over scalar functions
Scalar functions let you encapsulate a calculation into a stored procedure-like snippet of SQL. It’s common practice to return the results of a scalar function as a column in a SELECT query.
If you find yourself doing this a lot in Microsoft SQL Server, you can get better performance by using a table-valued function instead and using CROSS APPLY in the query. For more on the little-discussed APPLY operator, see this training module from the Microsoft Virtual Academy.
Use partitioning to avoid large data moves
SQL Server Enterprise offers “partitioning,” which allows you to split database tables into multiple partitions. If you have a table you’re constantly archiving into another table, you can avoid using INSERT/DELETE to move the data, and use SWITCH instead.
For instance, if you have a table that is emptied out daily into an archive table, you can perform this emptying-and-copying operation by using SWITCH to simply assign the pages in the daily table to the archive table. The switching process takes orders of magnitude less time than a manual copy-and-delete. Cathrine Wilhelmsen has an excellent tutorial on how to use partitioning in this way.
Use stored procedures for performance, use ORMs for convenience
ORMS—object-relational mappers—are software toolkits that produce programmatically generated SQL code. They allow you to use your application’s programming language and its metaphors to develop and maintain your queries.
Many database developers dislike ORMs on principle. They are are notorious for producing inefficient and sometimes unoptimizable code, and they give developers less incentive to learn SQL and understand what their queries are doing. When a developer needs to hand-write a query to get the best possible performance, they don’t know how.
On the other hand, ORMs make writing and maintaining database code far easier. The database part of the application isn’t off in another domain somewhere, and it’s written in a way that’s more loosely coupled to the application logic.
It makes the most sense to use stored procedures for queries that are called constantly, require good performance, aren’t likely to be changed often (if ever), and need to be surveyed for performance by the database’s profiling tools. Most databases make it easier to obtain such statistics in aggregate for a stored procedure than for an ad hoc query. It’s also easier for stored procedures to be optimized by the database’s query planner.
The downside of moving more of your database logic into stored procedures is that your logic is coupled that much more tightly to the database. Stored procedures can mutate from a performance advantage into a massive technical debt. If you decide to migrate to another database technology later, it’s easier to change the ORM’s target than to rewrite all the stored procedures. Also, the code generated by an ORM can be inspected for optimization, and query caching often allows the most commonly generated queries to be reused.
If it’s app-side maintainability that matters, use an ORM. If it’s database-side performance, use stored procedures.
The Jakarta Persistence API (JPA) is a Java specification that bridges the gap between relational databases and object-oriented programming. This two-part tutorial introduces JPA and explains how Java objects are modeled as JPA entities, how entity relationships are defined, and how to use JPA’s EntityManager with the Repository pattern in your Java applications. This gives you all the basics for saving and loading application state.
Note that this tutorial uses Hibernate as the JPA provider. Most concepts can be extended to other Java persistence frameworks.
Object relations in JPA
Relational databases have existed as a means for storing program data since the 1970s. While developers today have many alternatives to the relational database, it is still widely used in small- and large-scale software development.
Java objects in a relational database context are defined as entities. Entities are objects that are placed in tables where they occupy columns and rows, thereby outliving their existence in the program. Programmers use foreign keys and join tables to define the relationships between entities—namely one-to-one, one-to-many, and many-to-many relationships. We use SQL (Structured Query Language) to retrieve and interact with data in individual tables and across multiple tables.
The relational model is flat, whereas object models are graphs. Developers can write queries to retrieve data and construct objects from relational data, and vice versa, but that process is painstaking and error prone. JPA is one way to solve that problem.
Object-relations impedance mismatch
You may be familiar with the term object-relations impedance mismatch, which refers to this challenge of mapping data objects to a relational database. This mismatch occurs because object-oriented design is not limited to one-to-one, one-to-many, and many-to-many relationships. Instead, in object-oriented design, we think of objects, their attributes and behavior, and how objects relate. Two examples are encapsulation and inheritance:
If an object contains another object, we define this through encapsulation—a has-a relationship.
If an object is a specialization of another object, we define this through inheritance—an is-a relationship.
Association, aggregation, composition, abstraction, generalization, realization, and dependencies are all object-oriented programming concepts that can be challenging to map to a relational model.
Put another way, the simple dot notation in Java: myObject.anotherObject.aProperty implies a great deal of work for a relational data store.
ORM: Object-relational mapping
The mismatch between object-oriented design and relational database modeling has led to a class of tools developed specifically for object-relational mapping (ORM). ORM tools like Hibernate, EclipseLink, OpenJPA, and MyBatis translate relational database models, including entities and their relationships, into object-oriented models. Many of these tools existed before the JPA specification, but without a standard their features were vendor dependent.
First released as part of EJB 3.0 in 2006, the Java Persistence API (JPA) was moved to the Eclipse Foundation and renamed the Jakarta Persistence API in 2019. It offers a standard way to annotate objects so that they can be mapped and stored in a relational database. The specification also defines a common construct for interacting with databases. Having an ORM standard for Java brings consistency to vendor implementations, while also allowing for flexibility and add-ons. As an example, while the original JPA specification is applicable to relational databases, some vendor implementations have extended JPA for use with NoSQL databases.
Getting started with JPA
The Java Persistence API is a specification, not an implementation: it defines a common abstraction that you can use in your code to interact with ORM products. This section reviews some of the important parts of the JPA specification.
You’ll learn how to:
Define entities, fields, and primary keys in the database.
Create relationships between entities in the database.
Work with the EntityManager and its methods.
Defining entities
In order to define an entity, you must create a class that is annotated with the @Entity annotation. The @Entity annotation is a marker annotation, which is used to discover persistent entities. For example, if you wanted to create a book entity, you would annotate it as follows:
@Entity
public class Book {
...
}
By default, this entity will be mapped to the Book table, as determined by the given class name. If you wanted to map this entity to another table (and, optionally, a specific schema) you could use the @Table annotation. Here’s how you would map the Book class to a BOOKS table:
@Entity
@Table(name="BOOKS")
public class Book {
...
}
If the BOOKS table was in the PUBLISHING schema, you could add the schema to the @Table annotation:
@Table(name="BOOKS", schema="PUBLISHING")
Mapping fields to columns
With the entity mapped to a table, your next task is to define its fields. Fields are defined as member variables in the class, with the name of each field being mapped to a column name in the table. You can override this default mapping by using the @Column annotation, as shown here:
@Entity
@Table(name="BOOKS")
public class Book {
private String name;
@Column(name="ISBN_NUMBER")
private String isbn;
...
}
In this example, we’ve accepted the default mapping for the name attribute but specified a custom mapping for the isbn attribute. The name attribute will be mapped to the “name” column, but the isbn attribute will be mapped to the ISBN_NUMBER column.
The @Column annotation allows us to define additional properties of the field or column, including length, whether it is nullable, whether it must be unique, its precision and scale (if it’s a decimal value), whether it is insertable and updatable, and so forth.
Specifying the primary key
One of the requirements for a relational database table is that it must contain a primary key, or a key that uniquely identifies a specific row in the database. In JPA, we use the @Id annotation to designate a field to be the table’s primary key. The primary key must be a Java primitive type, a primitive wrapper such as Integer or Long, a String, a Date, a BigInteger, or a BigDecimal.
In this example, we map the id attribute, which is an Integer, to the ID column in the BOOKS table:
@Entity
@Table(name="BOOKS")
public class Book {
@Id
private Integer id;
private String name;
@Column(name="ISBN_NUMBER")
private String isbn;
...
}
It is also possible to combine the @Id annotation with the @Column annotation to overwrite the primary key’s column-name mapping.
Entity relationships in JPA
Now that you know how to define an entity, let’s look at how to create relationships between entities. JPA defines four annotations for defining relationships between entities:
@OneToOne
@OneToMany
@ManyToOne
@ManyToMany
One-to-one relationships
The @OneToOne annotation is used to define a one-to-one relationship between two entities. For example, you may have a User entity that contains a user’s name, email, and password, but you may want to maintain additional information about a user (such as age, gender, and favorite color) in a separate UserProfile entity. The @OneToOne annotation facilitates breaking down your data and entities this way.
The User class below has a single UserProfile instance. The UserProfile maps to a single User instance.
@Entity
public class User {
@Id
private Integer id;
private String email;
private String name;
private String password;
@OneToOne(mappedBy="user")
private UserProfile profile;
...
}
@Entity
public class UserProfile {
@Id
private Integer id;
private int age;
private String gender;
private String favoriteColor;
@OneToOne
private User user;
...
}
The JPA provider uses UserProfile‘s user field to map UserProfile to User. The mapping is specified in the mappedBy attribute in the @OneToOne annotation.
One-to-many and many-to-one relationships
The @OneToMany and @ManyToOne annotations facilitate different sides of the same relationship. Consider an example where a book can have only one author, but an author may have many books. The Book entity would define a @ManyToOne relationship with Author and the Author entity would define a @OneToMany relationship with Book:
@Entity
public class Book {
@Id
private Integer id;
private String name;
@ManyToOne
@JoinColumn(name="AUTHOR_ID")
private Author author;
...
}
@Entity
public class Author {
@Id
@GeneratedValue
private Integer id;
private String name;
@OneToMany(mappedBy = "author")
private List<Book> books = new ArrayList<>();
...
}
In this case, the Author class maintains a list of all of the books written by that author and the Book class maintains a reference to its single author. Additionally, the @JoinColumn specifies the name of the column in the Book table to store the ID of the Author.
Many-to-many relationships
Finally, the @ManyToMany annotation facilitates a many-to-many relationship between entities. Here’s a case where a Book entity has multiple Authors:
@Entity
public class Book {
@Id
private Integer id;
private String name;
@ManyToMany
@JoinTable(name="BOOK_AUTHORS",
joinColumns=@JoinColumn(name="BOOK_ID"),
inverseJoinColumns=@JoinColumn(name="AUTHOR_ID"))
private Set<Author> authors = new HashSet<>();
...
}
@Entity
public class Author {
@Id
@GeneratedValue
private Integer id;
private String name;
@ManyToMany(mappedBy = "author")
private Set<Book> books = new HashSet<>();
...
}
In this example, we create a new table, BOOK_AUTHORS, with two columns: BOOK_ID and AUTHOR_ID. Using the joinColumns and inverseJoinColumns attributes tells your JPA framework how to map these classes in a many-to-many relationship. The @ManyToMany annotation in the Author class references the field in the Book class that manages the relationship, namely the authors property.
Working with the EntityManager
EntityManager is the class that performs database interactions in JPA. It is initialized through a configuration file named persistence.xml or by using annotations. Each approach has advantages. Annotations keep the configuration close to the class configured, which is simpler, whereas the XML file keeps the configuration external to the code and shareable across different applications.
We’ll use persistence.xml in this example. The file is found in the META-INF folder in your CLASSPATH, which is typically packaged in your JAR or WAR file. The persistence.xml file contains the following:
The named “persistence unit,” which specifies the persistence framework you’re using, such as Hibernate or EclipseLink.
A collection of properties specifying how to connect to your database, as well as any customizations in the persistence framework.
A list of entity classes in your project.
Let’s look at an example.
Configuring the EntityManager
First, we create an EntityManager. There are a few ways to do this, including using the EntityManagerFactory retrieved from the Persistence class. In many scenarios, this class will be injected, with an IoC container like Spring or with Java CDI (Contexts and Dependency Injection). For simplicity in our standalone application, let’s define the EntityManager in one place, and then access it via the EntityManagerFactory, like so:
In this case, we’ve created an EntityManager that is connected to the “Books” persistence unit. You’ll see the EntityManager in action shortly.
The EntityManager class defines how our software will interact with the database through JPA entities. Here are some of the methods used by EntityManager:
createQuery() creates a Query instance that can be used to retrieve entities from the database.
createNamedQuery() loads a Query that has been defined in a @NamedQuery annotation inside one of the persistence entities. (Named queries provide a clean mechanism for centralizing JPA queries in the definition of the persistence class on which the query will execute.)
getTransaction() defines an EntityTransaction to use in your database interactions. Just like database transactions, you will typically begin the transaction, perform your operations, and then either commit or rollback your transaction. The getTransaction() method lets you access this behavior at the level of the EntityManager, rather than the database.
merge() adds an entity to the persistence context, so that when the transaction is committed, the entity will be persisted to the database. When using merge(), objects are not managed.
persist() adds an entity to the persistence context, so that when the transaction is committed, the entity will be persisted to the database. When using persist(), objects are managed.
refresh() refreshes the state of the current entity from the database.
flush() synchronizes the state of the persistence context with the database.
Don’t worry about integrating these methods all at once. You’ll get to know them by working directly with the EntityManager, which we’ll do more in the second half of this tutorial.
Conclusion to Part 1
This tutorial has been a general introduction to JPA. We’ve reviewed JPA as a standard for ORM in Java and looked at how entities, relationships, and the EntityManager work together in your Java applications. Stay tuned for the second half of this tutorial, where we’ll dive into JPA with Hibernate, and start writing code that persists data to and from a relational database.

 IDG
IDG




 IDG
IDG